Pytorch模型定义与深度学习自查手册
目录
- 定义神经网络
- 权重初始化
- 方法1:net.apply(weights_init)
- 方法2:在网络初始化的时候进行参数初始化
- 常用的操作
- 利用nn.Parameter()设计新的层
- nn.Flatten
- nn.Sequential
- 常用的层
- 全连接层nn.Linear()
- torch.nn.Dropout
- 卷积torch.nn.ConvNd()
- 池化
- 最大池化torch.nn.MaxPoolNd()
- 均值池化torch.nn.AvgPoolNd()
- 反池化
- 最大值反池化nn.MaxUnpool2d()
- 组合池化
- 正则化层
- BatchNorm
- LayerNorm
- InstanceNorm
- GroupNorm
- 激活函数
- torch.nn.GELU
- torch.nn.ELU(alpha=1.0,inplace=False)
- torch.nn.LeakyReLU(negative_slope=0.01,inplace=False)
- torch.nn.PReLU(num_parameters=1,init=0.25)
- torch.nn.ReLU(inplace=False)
- torch.nn.ReLU6(inplace=False)
- torch.nn.SELU(inplace=False)
- torch.nn.CELU(alpha=1.0,inplace=False)
- torch.nn.Sigmoid
- torch.nn.LogSigmoid
- torch.nn.Tanh
- torch.nn.Tanhshrink
- torch.nn.Softplus(beta=1,threshold=20)
- torch.nn.Softshrink(lambd=0.5)
- nn.Softmax
- 参考资料
定义神经网络
- 继承nn.Module类;
- 初始化函数__init__:网络层设计;
- forward函数:模型运行逻辑。
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
|
权重初始化
pytorch中的权值初始化
方法1:net.apply(weights_init)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
net=Model()
net.apply(weights_init)
|
方法2:在网络初始化的时候进行参数初始化
- 使用net.modules()遍历模型中的网络层的类型;
- 对其中的m层的weigth.data(tensor)部分进行初始化操作。
class Model(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = ...
...
# 权值参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
|
常用的操作
利用nn.Parameter()设计新的层
import torch
from torch import nn
class MyLinear(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, input):
return (input @ self.weight) + self.bias
|
nn.Flatten
展平输入的张量: 28x28 -> 784
input = torch.randn(32, 1, 5, 5)
m = nn.Sequential(
nn.Conv2d(1, 32, 5, 1, 1),
nn.Flatten()
)
output = m(input)
output.size()
|
nn.Sequential
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
net = nn.Sequential(
('fc1',MyLinear(4, 3)),
('act',nn.ReLU()),
('fc2',MyLinear(3, 1))
)
|
常用的层
全连接层nn.Linear()
torch.nn.Linear(in_features, out_features, bias=True,device=None, dtype=None)
in_features: 输入维度 out_features:输出维度 bias: 是否有偏置 |
m = nn.Linear(20, 30) input = torch.randn(128, 20) output = m(input) print(output.size()) |
torch.nn.Dropout
''' p:将元素置0的概率,默认值=0.5 ''' torch.nn.Dropout(p=0.5, inplace=False) |
卷积torch.nn.ConvNd()
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
in_channels(int) – 输入信号的通道 out_channels(int) – 卷积产生的通道 kerner_size(int or tuple) - 卷积核的尺寸 stride(int or tuple, optional) - 卷积步长 padding (int or tuple, optional)- 输入的每一条边补充0的层数 dilation(int or tuple, optional) – 卷积核元素之间的间距 groups(int, optional) – 从输入通道到输出通道的阻塞连接数 bias(bool, optional) - 如果bias=True,添加偏置 |
input: (N,C_in,H_in,W_in) N为批次,C_in即为in_channels,即一批内输入二维数据个数,H_in是二维数据行数,W_in是二维数据的列数
output: (N,C_out,H_out,W_out) N为批次,C_out即为out_channels,即一批内输出二维数据个数,H_out是二维数据行数,W_out是二维数据的列数
conv2 = nn.Conv2d(
in_channels=5,
out_channels=32,
kernel_size=5,
stride=1,
padding=2 #padding是需要计算的,padding=(stride-1)/2
)
#只能接受tensor/variable
conv2(torch.Tensor(16, 5, 3, 10))
conv2(Variable(torch.Tensor(16, 5, 3, 10)))
|
池化
最大池化torch.nn.MaxPoolNd()
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
kernel_size- 窗口大小 stride- 步长。默认值是kernel_size padding - 补0数 dilation– 控制窗口中元素步幅的参数 return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助 ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取的操作 |
max2=torch.nn.MaxPool2d(3,1,0,1) max2(torch.Tensor(16,15,15,14)) #output_shape=torch.Size([16, 15, 13, 12]) |
均值池化torch.nn.AvgPoolNd()
kernel_size - 池化窗口大小 stride- 步长。默认值是kernel_size padding- 输入的每一条边补充0的层数 dilation – 一个控制窗口中元素步幅的参数 return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助 ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作 |
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True) |
反池化
是池化的一个“逆”过程,但“逆”只是通过上采样恢复到原来的尺寸,像素值是不能恢复成原来一模一样,因为像最大池化是不可逆的,除最大值之外的像素都已经丢弃了。
最大值反池化nn.MaxUnpool2d()
功能:对二维图像进行最大值池化上采样
参数:
kernel_size- 窗口大小 stride - 步长。默认值是kernel_size padding - 补0数 |
torch.nn.MaxUnpool2d(kernel_size, stride=None, padding=0) |
img_tensor=torch.Tensor(16,5,32,32) # 上采样 max_pool = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2), return_indices=True, ceil_mode=True) img_pool, indices = max_pool(img_tensor) # 下采样 img_unpool = torch.rand_like(img_pool, dtype=torch.float) # 输入图像的大小和上采样的大小保持一致 max_unpool = nn.MaxUnpool2d((2, 2), stride=(2, 2)) img_unpool = max_unpool(img_unpool, indices) |
组合池化
组合池化同时利用最大值池化与均值池化两种的优势而引申的一种池化策略。常见组合策略有两种:Cat与Add。其代码描述如下:
def add_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return 0.5 * (x_avg + x_max)
def cat_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return torch.cat([x_avg, x_max], 1)
|
正则化层
Transformer相关Normalization方式
BatchNorm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) |
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为batch_size × num_features [× width],和之前输入卷积层的channel位的维度数目相同 eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。 momentum: 动态均值和动态方差所使用的动量。默认为0.1。 affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。 track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差; |
# With Learnable Parameters m = nn.BatchNorm2d(5) # Without Learnable Parameters m = nn.BatchNorm2d(5, affine=False) inputs = torch.randn(20, 5, 35, 45) output = m(inputs) |
LayerNorm
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True) |
参数:
normalized_shape: 输入尺寸 [× normalized_shape[0] × normalized_shape[1]×…× normalized_shape[−1]] eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。 elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。 |
LayerNorm就是对(2, 2,4), 后面这一部分进行整个的标准化。可以理解为对整个图像进行标准化。
x_test = np.array([[[1,2,-1,1],[3,4,-2,2]],
[[1,2,-1,1],[3,4,-2,2]]])
x_test = torch.from_numpy(x_test).float()
m = nn.LayerNorm(normalized_shape = [2,4])
output = m(x_test)
|
InstanceNorm
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) |
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为batch_size x num_features [x width] eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。 momentum: 动态均值和动态方差所使用的动量。默认为0.1。 affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。 track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差; |
InstanceNorm就是对(2, 2, 4)最后这一部分进行Norm。
x_test = np.array([[[1,2,-1,1],[3,4,-2,2]],
[[1,2,-1,1],[3,4,-2,2]]])
x_test = torch.from_numpy(x_test).float()
m = nn.InstanceNorm1d(num_features=2)
output = m(x_test)
|
GroupNorm
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True) |
参数:
num_groups:需要划分为的groups num_features: 来自期望输入的特征数,该期望输入的大小为batch_size x num_features [x width] eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。 momentum: 动态均值和动态方差所使用的动量。默认为0.1。 affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。 |
当GroupNorm中group的数量是1的时候, 是与上面的LayerNorm是等价的。
x_test = np.array([[[1,2,-1,1],[3,4,-2,2]],
[[1,2,-1,1],[3,4,-2,2]]])
x_test = torch.from_numpy(x_test).float()
# Separate 2 channels into 1 groups (equivalent with LayerNorm)
m = nn.GroupNorm(num_groups=1, num_channels=2, affine=False)
output = m(x_test)
|
当GroupNorm中num_groups的数量等于num_channel的数量,与InstanceNorm等价。
# Separate 2 channels into 2 groups (equivalent with InstanceNorm) m = nn.GroupNorm(num_groups=2, num_channels=2, affine=False) output = m(x_test) |
激活函数
参考资料:GELU 激活函数
Pytorch激活函数及优缺点比较
torch.nn.GELU

bert源码给出的GELU代码pytorch版本表示如下:
def gelu(input_tensor): cdf = 0.5 * (1.0 + torch.erf(input_tensor / torch.sqrt(2.0))) return input_tesnsor*cdf |
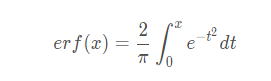
torch.nn.ELU(alpha=1.0,inplace=False)
def elu(x,alpha=1.0,inplace=False):
return max(0,x)+min(0,alpha∗(exp(x)−1))
|
α是超参数,默认为1.0

torch.nn.LeakyReLU(negative_slope=0.01,inplace=False)
def LeakyReLU(x,negative_slope=0.01,inplace=False):
return max(0,x)+negative_slope∗min(0,x)
其中 negative_slope是超参数,控制x为负数时斜率的角度,默认为1e-2

torch.nn.PReLU(num_parameters=1,init=0.25)
def PReLU(x,num_parameters=1,init=0.25):
return max(0,x)+init∗min(0,x)
其中a 是一个可学习的参数,当不带参数调用时,即nn.PReLU(),在所有的输入通道上使用同一个a,当带参数调用时,即nn.PReLU(nChannels),在每一个通道上学习一个单独的a。
注意:当为了获得好的performance学习一个a时,不要使用weight decay。
num_parameters:要学习的a的个数,默认1
init:a的初始值,默认0.25

torch.nn.ReLU(inplace=False)
CNN中最常用ReLu。
def ReLU(x,inplace=False):
return max(0,x)

torch.nn.ReLU6(inplace=False)
def ReLU6(x,inplace=False):
return min(max(0,x),6)

torch.nn.SELU(inplace=False)
def SELU(x,inplace=False):
alpha=1.6732632423543772848170429916717
scale=1.0507009873554804934193349852946
return scale∗(max(0,*x*)+min(0,alpha∗(exp(x)−1)))

torch.nn.CELU(alpha=1.0,inplace=False)
def CELU(x,alpha=1.0,inplace=False):
return max(0,x)+min(0,alpha∗(exp(x/alpha)−1))
其中α 默认为1.0
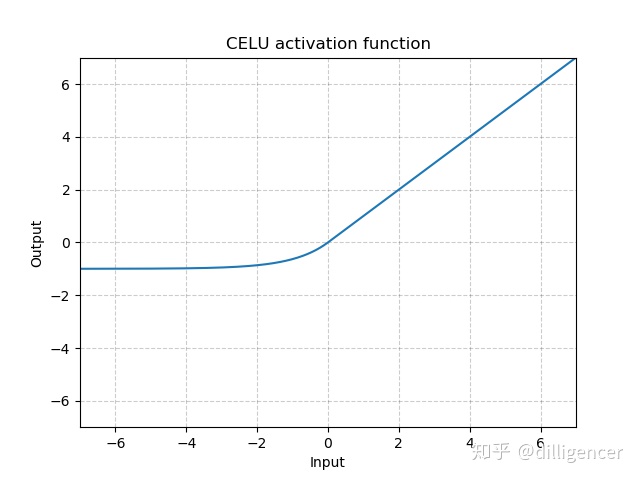
torch.nn.Sigmoid

def Sigmoid(x):
return 1/(np.exp(-x)+1)
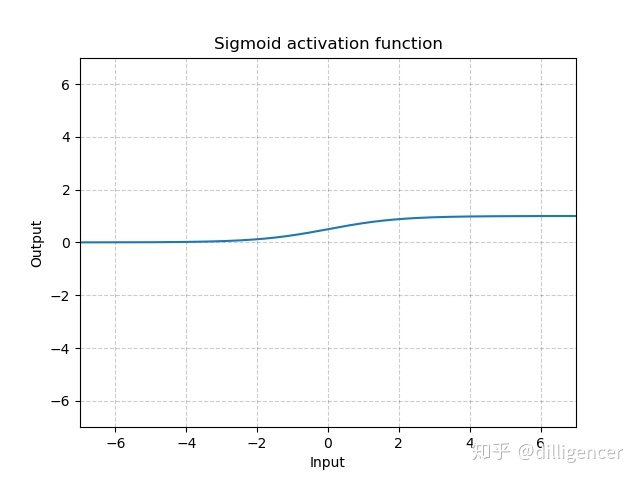
torch.nn.LogSigmoid

def LogSigmoid(x):
return np.log(1/(np.exp(-x)+1))
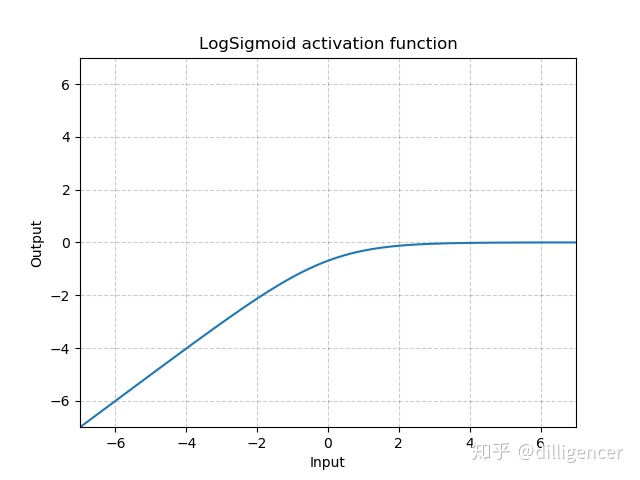
torch.nn.Tanh
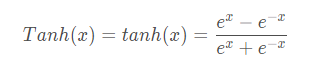
def Tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))

torch.nn.Tanhshrink

def Tanhshrink(x):
return x-(np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))

torch.nn.Softplus(beta=1,threshold=20)

该函数可以看作是ReLu的平滑近似。
def Softplus(x,beta=1,threshold=20):
return np.log(1+np.exp(beta*x))/beta

torch.nn.Softshrink(lambd=0.5)
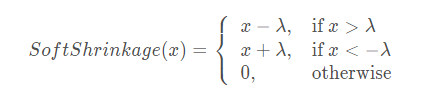
λ的值默认设置为0.5
def Softshrink(x,lambd=0.5):
if x>lambd:return x-lambd
elif x<-lambd:return x+lambd
else:return 0

nn.Softmax
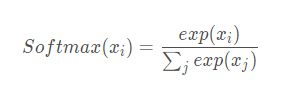
m = nn.Softmax(dim=1) input = torch.randn(2, 3) output = m(input)
参考资料
Pytorch激活函数及优缺点比较
PyTorch快速入门教程二(线性回归以及logistic回归)
Pytorch全连接网络
pytorch系列之nn.Sequential讲解
以上就是Pytorch模型定义与深度学习自查手册的详细内容,更多关于Pytorch深度学习模型定义的资料请关注我们其它相关文章!
相关推荐
-

PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
PyTorch模型保存与加载实例详解
目录 一个简单的例子 保存/加载 state_dict(推荐) 保存/加载整个模型 保存加载用于推理的常规Checkpoint/或继续训练 保存多个模型到一个文件 使用其他模型来预热当前模型 跨设备保存与加载模型 总结 torch.save:保存序列化的对象到磁盘,使用了Python的pickle进行序列化,模型.张量.所有对象的字典. torch.load:使用了pickle的unpacking将pickled的对象反序列化到内存中. torch.nn.Module.load_state_di
-
教你用PyTorch部署模型的方法
目录 导读 使用Docker安装 Handlers 导出你的模型 用模型进行服务 总结 导读 演示了使用PyTorch最近发布的新工具torchserve来进行PyTorch模型的部署. 最近,PyTorch推出了名为torchserve.的新生产框架来为模型提供服务.我们看一下今天的roadmap: 1.使用Docker安装 2.导出模型 3.定义handler 4.保存模型 为了展示torchserve,我们将提供一个经过全面训练的ResNet34进行图像分类的服务. 使用Docker安装
-
如何将pytorch模型部署到安卓上的方法示例
目录 模型转化 安卓部署 新建项目 导入包 页面文件 模型推理 这篇文章演示如何将训练好的pytorch模型部署到安卓设备上.我也是刚开始学安卓,代码写的简单. 环境: pytorch版本:1.10.0 模型转化 pytorch_android支持的模型是.pt模型,我们训练出来的模型是.pth.所以需要转化才可以用.先看官网上给的转化方式: import torch import torchvision from torch.utils.mobile_optimizer import opti
-
pytorch常用函数定义及resnet模型修改实例
目录 模型定义常用函数 利用nn.Parameter()设计新的层 nn.Sequential nn.ModuleList() nn.ModuleDict() nn.Flatten 模型修改案例 修改模型层 添加外部输入 模型定义常用函数 利用nn.Parameter()设计新的层 import torch from torch import nn class MyLinear(nn.Module): def __init__(self, in_features, out_features):
-
Pytorch模型定义与深度学习自查手册
目录 定义神经网络 权重初始化 方法1:net.apply(weights_init) 方法2:在网络初始化的时候进行参数初始化 常用的操作 利用nn.Parameter()设计新的层 nn.Flatten nn.Sequential 常用的层 全连接层nn.Linear() torch.nn.Dropout 卷积torch.nn.ConvNd() 池化 最大池化torch.nn.MaxPoolNd() 均值池化torch.nn.AvgPoolNd() 反池化 最大值反池化nn.MaxUnpoo
-
Pytorch模型迁移和迁移学习,导入部分模型参数的操作
1. 利用resnet18做迁移学习 import torch from torchvision import models if __name__ == "__main__": # device = torch.device("cuda" if torch.cuda.is_available() else "cpu") device = 'cpu' print("-----device:{}".format(device))
-
Pytorch模型微调fine-tune详解
目录 2.1.为什么要微调 2.2.需要微调的情况 2.4.参数冻结---指定训练模型的部分层 2.5.参数冻结的方式 2.5.1.冻结方式1 2.5.2.冻结方式2 2.5.2.冻结方式3 2.6.修改模型参数 2.7.修改模型结构 随着深度学习的发展,在大模型的训练上都是在一些较大数据集上进行训练的,比如Imagenet-1k,Imagenet-11k,甚至是ImageNet-21k等.但我们在实际应用中,我们自己的数据集可能比较小,只有几千张照片,这时从头训练具有几千万参数的大型神经网络是
-
pytorch模型转onnx模型的方法详解
目录 学习目标 学习大纲 学习内容 1 . pytorch 转 onnx 2 . 运行onnx模型 3.onnx模型输出与pytorch模型比对 总结 学习目标 1.掌握pytorch模型转换到onnx模型 2.顺利运行onnx模型 3.比对onnx模型和pytorch模型的输出结果 学习大纲 pytorch模型转换onnx模型 运行onnx模型 onnx模型输出与pytorch模型比对 学习内容 前提条件:需要安装onnx 和 onnxruntime,可以通过 pip install onnx
-
pyTorch深度学习softmax实现解析
目录 用PyTorch实现linear模型 模拟数据集 定义模型 加载数据集 optimizer 模型训练 softmax回归模型 Fashion-MNIST cross_entropy 模型的实现 利用PyTorch简易实现softmax 用PyTorch实现linear模型 模拟数据集 num_inputs = 2 #feature number num_examples = 1000 #训练样本个数 true_w = torch.tensor([[2],[-3.4]]) #真实的权重值 t
-
Python深度学习pyTorch权重衰减与L2范数正则化解析
下面进行一个高维线性实验 假设我们的真实方程是: 假设feature数200,训练样本和测试样本各20个 模拟数据集 num_train,num_test = 10,10 num_features = 200 true_w = torch.ones((num_features,1),dtype=torch.float32) * 0.01 true_b = torch.tensor(0.5) samples = torch.normal(0,1,(num_train+num_test,num_fe
-
Python深度学习理解pytorch神经网络批量归一化
目录 训练深层网络 为什么要批量归一化层呢? 批量归一化层 全连接层 卷积层 预测过程中的批量归一化 使用批量归一化层的LeNet 简明实现 争议 训练深层神经网络是十分困难的,特别是在较短的实践内使他们收敛更加棘手.在本节中,我们将介绍批量归一化(batch normalization),这是一种流行且有效的技术,可持续加速深层网络的收敛速度.在结合之后将介绍的残差快,批量归一化使得研究人员能够训练100层以上的网络. 训练深层网络 为什么要批量归一化层呢? 让我们回顾一下训练神经网络时出现的
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
Python深度学习pytorch实现图像分类数据集
目录 读取数据集 读取小批量 整合所有组件 目前广泛使用的图像分类数据集之一是MNIST数据集.如今,MNIST数据集更像是一个健全的检查,而不是一个基准. 为了提高难度,我们将在接下来的章节中讨论在2017年发布的性质相似但相对复杂的Fashion-MNIST数据集. import torch import torchvision from torch.utils import data from torchvision import transforms from d2l import to