浅谈Selenium+Webdriver 常用的元素定位方式
假设页面源代码如下:
<input type="text"name="wd" id="kw1" class="input_wd" maxlength="100"style="width:474px;"autocomplete="off">
通过id定位元素:find_element_by_id(“id_vaule”):
browser=webdriver.Firefox()
browser.find_element_by_id("kw1")
通过name定位元素:find_element_by_name(“name_vaule”)
browser.find_element_by_name("wd")
通过tag_name定位元素:find_element_by_tag_name(“tag_name_vaule”)
browser.find_element_by_tag_name("input")#tag_name指标签名称
通过class_name定位元素:find_element_by_class_name(“class_name”)
browser.find_element_by_class_name("input_wd")
通过css定位元素:find_element_by_css_selector();用css定位是比较灵活的
browser.find_element_by_css_selector("input[id=\"kw1\"]")
browser.find_element_by_css_selector("input.input_wd)
browser.find_element_by_css_selector("#kw1)
通过xpath定位元素:find_element_by_xpath(“xpath”)
XPath(XML Path Language)是一种在XML文档中定位元素的语言,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设页面源代码如下:
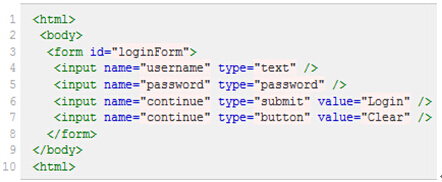
注:元素的xpath绝对路径可通过firebug直接查询,绝对路径以单/开头,从文档的根节点开始解析(如:/html/body/table/tbody/tr[2]/td[2]/div/div[1]/div/div[2]/div[4]/div[3]/div[1]/a[1]),相对路径则以//开头,从文档的任意节点开始解析。

相对路径的引用写法:
| 表达式 | 描述 |
|---|---|
| //input | 选取所有input元素 |
| //form[1]/input | 选取第一个form元素内的所有直接子input元素 |
| //form[1]//input | 选取第一个form元素内的所有子input元素,不论嵌套了多少层 |
| //form[1]/input[last()] | 选取第一个form元素内的所有直接子input元素中的最后一个 |
| //form[@id='loginForm'] | 选取id属性值为loginForm的form元素 |
| //input[@name='continue'][@type='button'] | 选取name属性值为continue且type属性值为button的input元素 |
| //form[@id^='loginForm']/input[4] | 选取id以loginForm开头的form元素下第4个input元素 |
| browser.find_element_by_xpath(“//td[contains(text(),'下单编号')]”) | 选取text文本为下单编号的td |
通过link定位:find_element_by_link_text(“text_vaule”)或者find_element_by_partial_link_text()
适用于页面中出现的文字链接
browser.find_element_by_link_text("登录").click() #点击登录链接
browser.find_element_by_partial_link_text("登").click()#只用了链接中的部分文字
参考资料:
[1]XPath教程
[2]Selenium Webdriver元素定位的八种常用方式
到此这篇关于浅谈Selenium+Webdriver 常用的元素定位方式的文章就介绍到这了,更多相关Selenium Webdriver元素定位内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Selenium Webdriver元素定位的八种常用方式(小结)
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方式共八种,现分别介绍如下. 1. By.name() 假设我们要测试的页面源码如下: <button id="gbqfba" aria-label="Google Search" name="btnK" class="gbqfba"><
-
详解Selenium 元素定位和WebDriver常用方法
一.定位元素的8种方式 1.方法介绍 定位一个元素 定位多个元素 含义 find_element_by_id() find_elements_by_id() 通过元素id定位 find_element_by_name() find_elements_by_name() 通过元素name定位 find_element_by_xpath() find_elements_by_xpath() 通过xpath表达式定位 find_element_by_link_text() find_elements_
-
浅谈Selenium+Webdriver 常用的元素定位方式
假设页面源代码如下: <input type="text"name="wd" id="kw1" class="input_wd" maxlength="100"style="width:474px;"autocomplete="off"> 通过id定位元素:find_element_by_id("id_vaule"): browser=
-
浅谈Selenium 控制浏览器的常用方法
1.自定义浏览器窗口大小或全屏 from selenium import webdriver import time driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 自定义窗口大小 driver.set_window_size(100, 200)#参数数字为像素点 print('现在是自定义大小展示') time.sleep(5)#睡5秒 显示一下效果 #全屏展示 driver.maximize_window(
-
浅谈selenium如何应对网页内容需要鼠标滚动加载的问题
相信大家在selenium爬取网页的时候都遇到过这样的问题:就是网页内容需要用鼠标滚动加载剩余内容,而不是一次全部加载出网页的全部内容,这个时候如果要模拟翻页的时候就必须加载出全部的内容,不然定位元素会找不到,出现报错. 这里提供两种方法供大家参考 一,通过selenium模拟浏览器,然后设置浏览器高度足够长,最后延时使之能够将页面的内容都能够加载出来 import time from selenium import webdriver driver = webdriver.Firefox()
-
详解Selenium中元素定位方式
目录 八大元素定位方式 通过元素 id 定位 通过元素 name 定位 通过元素 class name 定位 通过 link text 与 partial link text 定位 通过 css selector 选择器定位 通过 Xpath 定位 通过 tag_name 定位 测试对象的定位和操作是我们利用 selenium 编写自动化脚本和 webdriver 的核心内容,其中 “操作” 这一部分又是建立在 “selenium” 元素定位的基础之上的.所以对元素对象的定位就显得越发的重要,接
-
浅谈Java中常用数据结构的实现类 Collection和Map
线性表,链表,哈希表是常用的数据结构,在进行Java开发时,JDK已经为我们提供了一系列相应的类来实现基本的数据结构.这些类均在java.util包中.本文试图通过简单的描述,向读者阐述各个类的作用以及如何正确使用这些类. Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map ├Hashtable ├HashMap └WeakHashMap Collection接口 Collection是最基本的集合接口,一个C
-
Python脚本Selenium及页面Web元素定位详解
目录 Selenium特点 八种定位方式 1.driver.find_element_by_xpath(value) 2.driver.find_element_by_css_selector(value) 3.driver.find_element_by_id(value) 4.driver.find_element_by_name(value) 5.driver.find_element_by_class_name(value) 6.driver.find_element_by_tag_na
-
浅谈CI脚本异常退出问题定位
背景 在CI脚本中,使用类似如下脚本进行项目编译的计时,但在执行过程中,有时会出现CI脚本(命名为ci.sh)未完全执行的情况: #!/bin/bash -e sleep_time=$1 start_time=`date "+%s"` # do sth, this sleep would simulate project compilation sleep $sleep_time end_time=`date "+%s"` process_time=`expr \(
-
浅谈几种常用的JS类定义方法
// 方法1 对象直接量 var obj1 = { v1 : "", get_v1 : function() { return this.v1; }, set_v1 : function(v) { this.v1 = v; } }; // 方法2 定义函数对象 var Obj = function() { var v1 = ""; this.get_v1 = function() { return this.v1; }; this.set_v1 = function
-
浅谈fastjson的常用使用方法
如下所示: package Demo; import java.util.ArrayList; import java.util.Collection; import java.util.Date; import java.util.HashMap; import java.util.List; import java.util.Vector; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONArray; imp
-
浅谈Django中的QueryDict元素为数组的坑
一般在Django的视图函数中使用request.POST来获取请求体,request.POST是QueryDict类,通常作为dict来使用. 正常如下图 但是昨天在使用的时候遇到一个错误,提示从QueryDict里面pop出来的值类型为list. 一脸懵逼 在命令行敲代码,发现了这个坑, 如下图 可以看到,pop出来的值被放在的一个list里面.关键这个不同版本之间,行为还有所不同,就是因为在开发机器上一切正常,到了测试服务器就出问题才被发现的. 知道了问题,解决起来也简单,直接调用Quer