Pytorch训练过程出现nan的解决方式
今天使用shuffleNetV2+,使用自己的数据集,遇到了loss是nan的情况,而且top1精确率出现断崖式上升,这显示是不正常的。
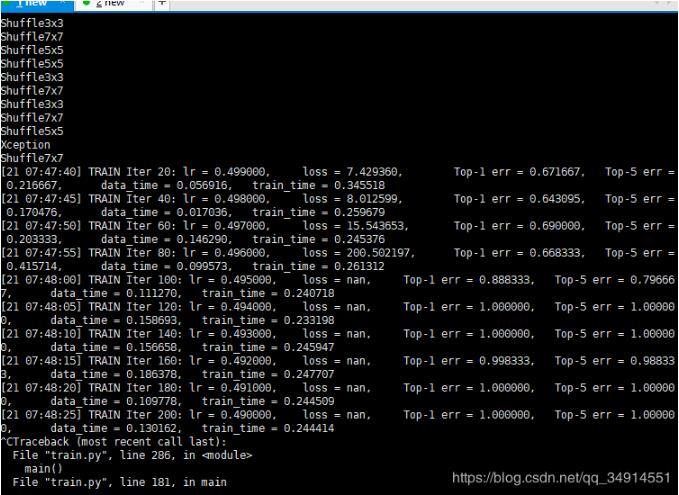
在网上查了下解决方案。我的问题是出在学习率上了。
我自己做的样本数据集比较小,就三类,每类大概三百多张,初始学习率是0.5。后来设置为0.1就解决了。
按照解决方案上写的。出现nan的情况还有以下几种:
学习率太大,但是样本数据集又很小。(我的情况)
自定义的loss除以了一个很小的数字,小到接近0。
数据不干净,数据本身就有nan,可以用numpy.isnan检查。
target,即label是大于等于0的。从1到类别数目-1变化。
以上这篇Pytorch训练过程出现nan的解决方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

详解PyTorch批训练及优化器比较
一.PyTorch批训练 1. 概述 PyTorch提供了一种将数据包装起来进行批训练的工具--DataLoader.使用的时候,只需要将我们的数据首先转换为torch的tensor形式,再转换成torch可以识别的Dataset格式,然后将Dataset放入DataLoader中就可以啦. import torch import torch.utils.data as Data torch.manual_seed(1) # 设定随机数种子 BATCH_SIZE = 5 x = torch.li
-
解决Pytorch 训练与测试时爆显存(out of memory)的问题
Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法. 使用torch.cuda.empty_cache()删除一些不需要的变量代码示例如下: try: output = model(input) except RuntimeError as exception: if "out of memory" in str(exception): print("WARNING: out of
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代
-
解决Pytorch训练过程中loss不下降的问题
在使用Pytorch进行神经网络训练时,有时会遇到训练学习率不下降的问题.出现这种问题的可能原因有很多,包括学习率过小,数据没有进行Normalization等.不过除了这些常规的原因,还有一种难以发现的原因:在计算loss时数据维数不匹配. 下面是我的代码: loss_function = torch.nn.MSE_loss() optimizer.zero_grad() output = model(x_train) loss = loss_function(output, y_train)
-
Pytorch训练过程出现nan的解决方式
今天使用shuffleNetV2+,使用自己的数据集,遇到了loss是nan的情况,而且top1精确率出现断崖式上升,这显示是不正常的. 在网上查了下解决方案.我的问题是出在学习率上了. 我自己做的样本数据集比较小,就三类,每类大概三百多张,初始学习率是0.5.后来设置为0.1就解决了. 按照解决方案上写的.出现nan的情况还有以下几种: 学习率太大,但是样本数据集又很小.(我的情况) 自定义的loss除以了一个很小的数字,小到接近0. 数据不干净,数据本身就有nan,可以用numpy.isna
-
Pytorch训练网络过程中loss突然变为0的解决方案
问题 // loss 突然变成0 python train.py -b=8 INFO: Using device cpu INFO: Network: 1 input channels 7 output channels (classes) Bilinear upscaling INFO: Creating dataset with 868 examples INFO: Starting training: Epochs: 5 Batch size: 8 Learning rate: 0.001
-
Pytorch GPU显存充足却显示out of memory的解决方式
今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorch版本的问题,原来我的pytorch版本是0.4.1,于是我就把这个版本卸载,然后安装了pytorch1.1.0,程序就可以神奇的运行了,不会再有OOM的提示了.虽然具体原因还不知道为何,这里还是先mark一下,具体过程如下: 卸载旧版本pytorch: conda uninstall pyt
-
基于pytorch padding=SAME的解决方式
tensorflow中的conv2有padding='SAME'这个参数.吴恩达讲课中说到当padding=(f-1)/2(f为卷积核大小)时则是SAME策略.但是这个没有考虑到空洞卷积的情况,也没有考虑到strides的情况. 查阅资料后发现网上方法比较麻烦. 手算,实验了一个早上,终于初步解决了问题. 分为两步: 填充多少 中文文档中有计算公式: 输入: 输出: 因为卷积后图片大小同卷积前,所以这里W_out=W_in, H_out=H_in.解一元一次方程即可.结果取ceil. 怎么填充
-
pytorch dataloader 取batch_size时候出现bug的解决方式
1. RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 342 and 281 in dimension 3 at /pytorch/aten/src/TH/generic/THTensorMoreMath.cpp:1333 2. RuntimeError: invalid argument 0: Sizes of tensors must match except i
-
jupyter notebook 使用过程中python莫名崩溃的原因及解决方式
最近在使用 Python notebook时老是出现python崩溃的现象,如下图,诱发的原因是"KERNELBASE.dll",异常代码报"40000015". 折腾半天,发现我启动notebook时是用自定义startup.bat方式方式启动的,bat文件的内容为 start C:\Anaconda3\python.exe "C:/Anaconda3/Scripts/jupyter-notebook-script.py" 平时双击这个bat文
-
Keras load_model 导入错误的解决方式
在使用Keras load_model时,会出现以下报错: ImportError: Failed to import pydot. You must install pydot and graphviz for `pydotprint` to work. 解决办法: $ pip install pydot $ sudo apt-get install graphviz 补充知识:Keras 保存model到指定文件夹和加载load_model指定文件夹中的文件(踩坑) 我们一般保存模型和加载模
-
keras load model时出现Missing Layer错误的解决方式
问题描述:训练结束后,保存model为hdf5和yaml格式的文件 yamlFilename = os.path.join(dir,filename) yamlModel = model.toyaml() with open(yamlFilename, "w") as yamlFile: yamlFile.write(yamlModel) 随后load model with open(chkptFilename,'r') as f: model_yaml = f.read() mode