解决Tensorflow占用GPU显存问题
我使用Pytorch进行模型训练时发现真正模型本身对于显存的占用并不明显,但是对应的转换为tensorflow后(权重也进行了转换),发现Python-tensorflow在使用时默认吃掉所有显存,并且不手动终结程序的话显存并不释放(我有两个序贯的模型,前面一个跑完后并不释放占用显存)(https://github.com/tensorflow/tensorflow/issues/1727),这一点对于后续的工作有很大的影响。
后面发现python-tensorflow限制显存有两种方法:
1. 设置显卡的使用率
这种方法在学习和工作中比较好用,学习时可提高显卡使用效率,工作时可方便的获得GPU显存消耗极限,用以提供显卡购买时的参数,现将代码展示如下:
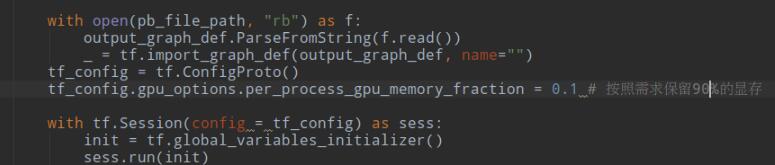
这里的0.1 表示使用显存总量的的10%
2. 设置显卡按需使用(这个本人并没有专门测试,只是从tensorflow论坛上获得)
gpu_options = tf.GPUOptions(allow_growth=True) sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
以上这篇解决Tensorflow占用GPU显存问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Tensorflow设置显存自适应,显存比例的操作
Tensorfow框架下,在模型运行时,设置对显存的占用. 1. 按比例 config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.4 # 根据自己的需求确定 session = tf.Session(config=config, ...) 2. 自适应 config = tf.ConfigProto() config.gpu_options.allow_growth = True sessi
-
TensorFlow 显存使用机制详解
默认情况下,TensorFlow 会映射进程可见的所有 GPU 的几乎所有 GPU 内存(取决于 CUDA_VISIBLE_DEVICES).通过减少内存碎片,可以更有效地使用设备上相对宝贵的 GPU 内存资源. 在某些情况下,最理想的是进程只分配可用内存的一个子集,或者仅根据进程需要增加内存使用量. TensorFlow 在 Session 上提供两个 Config 选项来进行控制. (1) : 自主申请所用的内存空间 第一个是 allow_growth 选项,它试图根据运行时的需要来分配 G
-
解决Tensorflow占用GPU显存问题
我使用Pytorch进行模型训练时发现真正模型本身对于显存的占用并不明显,但是对应的转换为tensorflow后(权重也进行了转换),发现Python-tensorflow在使用时默认吃掉所有显存,并且不手动终结程序的话显存并不释放(我有两个序贯的模型,前面一个跑完后并不释放占用显存)(https://github.com/tensorflow/tensorflow/issues/1727),这一点对于后续的工作有很大的影响. 后面发现python-tensorflow限制显存有两种方法: 1.
-
Pytorch GPU显存充足却显示out of memory的解决方式
今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorch版本的问题,原来我的pytorch版本是0.4.1,于是我就把这个版本卸载,然后安装了pytorch1.1.0,程序就可以神奇的运行了,不会再有OOM的提示了.虽然具体原因还不知道为何,这里还是先mark一下,具体过程如下: 卸载旧版本pytorch: conda uninstall pyt
-
pytorch程序异常后删除占用的显存操作
1-删除模型变量 del model_define 2-清空CUDA cache torch.cuda.empty_cache() 3-步骤2(异步)需要一定时间,设置时延 time.sleep(5) 完整代码如下: del styler torch.cuda.empty_cache() time.sleep(5) 以上这篇pytorch程序异常后删除占用的显存操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Keras - GPU ID 和显存占用设定步骤
初步尝试 Keras (基于 Tensorflow 后端)深度框架时, 发现其对于 GPU 的使用比较神奇, 默认竟然是全部占满显存, 1080Ti 跑个小分类问题, 就一下子满了. 而且是服务器上的两张 1080Ti. 服务器上的多张 GPU 都占满, 有点浪费性能. 因此, 需要类似于 Caffe 等框架的可以设定 GPU ID 和显存自动按需分配. 实际中发现, Keras 还可以限制 GPU 显存占用量. 这里涉及到的内容有: GPU ID 设定 GPU 显存占用按需分配 GPU 显存占
-
解决TensorFlow程序无限制占用GPU的方法
今天遇到一个奇怪的现象,使用tensorflow-gpu的时候,出现内存超额~~如果我训练什么大型数据也就算了,关键我就写了一个y=W*x-显示如下图所示: 程序如下: import tensorflow as tf w = tf.Variable([[1.0,2.0]]) b = tf.Variable([[2.],[3.]]) y = tf.multiply(w,b) init_op = tf.global_variables_initializer() with tf.Session()
-
Tensorflow与Keras自适应使用显存方式
Tensorflow支持基于cuda内核与cudnn的GPU加速,Keras出现较晚,为Tensorflow的高层框架,由于Keras使用的方便性与很好的延展性,之后更是作为Tensorflow的官方指定第三方支持开源框架. 但两者在使用GPU时都有一个特点,就是默认为全占满模式.在训练的情况下,特别是分步训练时会导致显存溢出,导致程序崩溃. 可以使用自适应配置来调整显存的使用情况. 一.Tensorflow 1.指定显卡 代码中加入 import os os.environ["CUDA_VIS
-
python中显存回收问题解决方法
目录 1.技术背景 2.问题复现 3.解决思路 4.总结概要 1.技术背景 笔者在执行一个Jax的任务中,又发现了一个奇怪的问题,就是明明只分配了很小的矩阵空间,但是在多次的任务执行之后,显存突然就爆了.而且此时已经按照Jax的官方说明配置了XLA_PYTHON_CLIENT_PREALLOCATE这个参数为false,也就是不进行显存的预分配(默认会分配90%的显存空间以供使用).然后在网上找到了一些类似的问题,比如参考链接中的1.2.3.4,都是在一些操作后发现未释放显存,这里提供一个实例问
-
浅谈多卡服务器下隐藏部分 GPU 和 TensorFlow 的显存使用设置
服务器有多张显卡,一般是组里共用,分配好显卡和任务就体现公德了.除了在代码中指定使用的 GPU 编号,还可以直接设置可见 GPU 编号,使程序/用户只对部分 GPU 可见. 操作很简单,使用环境变量 CUDA_VISIBLE_DEVICES 即可. 具体来说,如果使用单卡运行 Python 脚本,则可输入 CUDA_VISIBLE_DEVICES=1 python my_script.py 脚本将只使用 GPU1. 在 .py 脚本和 Notebook 中设置,则 import os os.en
-
解决TensorFlow GPU版出现OOM错误的问题
问题: 在使用mask_rcnn预测自己的数据集时,会出现下面错误: ResourceExhaustedError: OOM when allocating tensor with shape[1,512,1120,1120] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[{{node rpn_model/rpn_conv_shared/convolution}} =
随机推荐
- 每天一篇javascript学习小结(基础知识)
- 基于Vue2实现的仿手机QQ单页面应用功能(接入聊天机器人 )
- VBS读网页的代码
- Java中的匿名内部类小结
- PHP使用静态方法的几个注意事项
- python paramiko模块学习分享
- Python实现小数转化为百分数的格式化输出方法示例
- 详解C#中通过委托来实现回调函数功能的方法
- nodejs的require模块(文件模块/核心模块)及路径介绍
- 最新版本PHP 7 vs HHVM 多角度比较
- php用户密码加密算法分析【Discuz加密算法】
- 用注册表更改DNS的代码分享
- 基于jquery的拖动布局插件
- Jquery焦点图实例代码
- Ubuntu下nginx编译安装参数配置
- 墙中自有墙中墙首Vista防火墙详解(上)第1/4页
- java8中parallelStream性能测试及结果分析
- bing Map 在vue项目中的使用详解
- javascript将非数值转换为数值
- mall整合SpringTask实现定时任务的方法示例