Tensorflow 多线程与多进程数据加载实例
在项目中遇到需要处理超级大量的数据集,无法载入内存的问题就不用说了,单线程分批读取和处理(虽然这个处理也只是特别简单的首尾相连的操作)也会使瓶颈出现在CPU性能上,所以研究了一下多线程和多进程的数据读取和预处理,都是通过调用dataset api实现
1. 多线程数据读取
第一种方法是可以直接从csv里读取数据,但返回值是tensor,需要在sess里run一下才能返回真实值,无法实现真正的并行处理,但如果直接用csv文件或其他什么文件存了特征值,可以直接读取后进行训练,可使用这种方法.
import tensorflow as tf
#这里是返回的数据类型,具体内容无所谓,类型对应就好了,比如我这个,就是一个四维的向量,前三维是字符串类型 最后一维是int类型
record_defaults = [[""], [""], [""], [0]]
def decode_csv(line):
parsed_line = tf.decode_csv(line, record_defaults)
label = parsed_line[-1] # label
del parsed_line[-1] # delete the last element from the list
features = tf.stack(parsed_line) # Stack features so that you can later vectorize forward prop., etc.
#label = tf.stack(label) #NOT needed. Only if more than 1 column makes the label...
batch_to_return = features, label
return batch_to_return
filenames = tf.placeholder(tf.string, shape=[None])
dataset5 = tf.data.Dataset.from_tensor_slices(filenames)
#在这里设置线程数目
dataset5 = dataset5.flat_map(lambda filename: tf.data.TextLineDataset(filename).skip(1).map(decode_csv,num_parallel_calls=15))
dataset5 = dataset5.shuffle(buffer_size=1000)
dataset5 = dataset5.batch(32) #batch_size
iterator5 = dataset5.make_initializable_iterator()
next_element5 = iterator5.get_next()
#这里是需要加载的文件名
training_filenames = ["train.csv"]
validation_filenames = ["vali.csv"]
with tf.Session() as sess:
for _ in range(2):
#通过文件名初始化迭代器
sess.run(iterator5.initializer, feed_dict={filenames: training_filenames})
while True:
try:
#这里获得真实值
features, labels = sess.run(next_element5)
# Train...
# print("(train) features: ")
# print(features)
# print("(train) labels: ")
# print(labels)
except tf.errors.OutOfRangeError:
print("Out of range error triggered (looped through training set 1 time)")
break
# Validate (cost, accuracy) on train set
print("\nDone with the first iterator\n")
sess.run(iterator5.initializer, feed_dict={filenames: validation_filenames})
while True:
try:
features, labels = sess.run(next_element5)
# Validate (cost, accuracy) on dev set
# print("(dev) features: ")
# print(features)
# print("(dev) labels: ")
# print(labels)
except tf.errors.OutOfRangeError:
print("Out of range error triggered (looped through dev set 1 time only)")
break
第二种方法,基于生成器,可以进行预处理操作了,sess里run出来的结果可以直接进行输入训练,但需要自己写一个生成器,我使用的测试代码如下:
import tensorflow as tf
import random
import threading
import numpy as np
from data import load_image,load_wave
class SequenceData():
def __init__(self, path, batch_size=32):
self.path = path
self.batch_size = batch_size
f = open(path)
self.datas = f.readlines()
self.L = len(self.datas)
self.index = random.sample(range(self.L), self.L)
def __len__(self):
return self.L - self.batch_size
def __getitem__(self, idx):
batch_indexs = self.index[idx:(idx+self.batch_size)]
batch_datas = [self.datas[k] for k in batch_indexs]
img1s,img2s,audios,labels = self.data_generation(batch_datas)
return img1s,img2s,audios,labels
def gen(self):
for i in range(100000):
t = self.__getitem__(i)
yield t
def data_generation(self, batch_datas):
#预处理操作,数据在参数里
return img1s,img2s,audios,labels
#这里的type要和实际返回的数据类型对应,如果在自己的处理代码里已经考虑的batchszie,那这里的batch设为1即可
dataset = tf.data.Dataset().batch(1).from_generator(SequenceData('train.csv').gen,
output_types= (tf.float32,tf.float32,tf.float32,tf.int64))
dataset = dataset.map(lambda x,y,z,w : (x,y,z,w), num_parallel_calls=32).prefetch(buffer_size=1000)
X, y,z,w = dataset.make_one_shot_iterator().get_next()
with tf.Session() as sess:
for _ in range(100000):
a,b,c,d = sess.run([X,y,z,w])
print(a.shape)
不过python的多线程并不是真正的多线程,虽然看起来我是启动了32线程,但运行时的CPU占用如下所示:
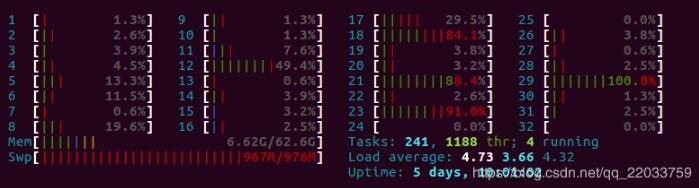
还剩这么多核心空着,然后就是第三个版本了,使用了queue来缓存数据,训练需要数据时直接从queue中进行读取,是一个到多进程的过度版本(vscode没法debug多进程,坑啊,还以为代码写错了,在vscode里多进程直接就没法运行),在初始化时启动多个线程进行数据的预处理:
import tensorflow as tf
import random
import threading
import numpy as np
from data import load_image,load_wave
from queue import Queue
class SequenceData():
def __init__(self, path, batch_size=32):
self.path = path
self.batch_size = batch_size
f = open(path)
self.datas = f.readlines()
self.L = len(self.datas)
self.index = random.sample(range(self.L), self.L)
self.queue = Queue(maxsize=20)
for i in range(32):
threading.Thread(target=self.f).start()
def __len__(self):
return self.L - self.batch_size
def __getitem__(self, idx):
batch_indexs = self.index[idx:(idx+self.batch_size)]
batch_datas = [self.datas[k] for k in batch_indexs]
img1s,img2s,audios,labels = self.data_generation(batch_datas)
return img1s,img2s,audios,labels
def f(self):
for i in range(int(self.__len__()/self.batch_size)):
t = self.__getitem__(i)
self.queue.put(t)
def gen(self):
while 1:
yield self.queue.get()
def data_generation(self, batch_datas):
#数据预处理操作
return img1s,img2s,audios,labels
#这里的type要和实际返回的数据类型对应,如果在自己的处理代码里已经考虑的batchszie,那这里的batch设为1即可
dataset = tf.data.Dataset().batch(1).from_generator(SequenceData('train.csv').gen,
output_types= (tf.float32,tf.float32,tf.float32,tf.int64))
dataset = dataset.map(lambda x,y,z,w : (x,y,z,w), num_parallel_calls=1).prefetch(buffer_size=1000)
X, y,z,w = dataset.make_one_shot_iterator().get_next()
with tf.Session() as sess:
for _ in range(100000):
a,b,c,d = sess.run([X,y,z,w])
print(a.shape)
2. 多进程数据读取
这里的代码和多线程的第三个版本非常类似,修改为启动进程和进程类里的Queue即可,但千万不要在vscode里直接debug!在vscode里直接f5运行进程并不能启动.
from __future__ import unicode_literals
from functools import reduce
import tensorflow as tf
import numpy as np
import warnings
import argparse
import skimage.io
import skimage.transform
import skimage
import scipy.io.wavfile
from multiprocessing import Process,Queue
class SequenceData():
def __init__(self, path, batch_size=32):
self.path = path
self.batch_size = batch_size
f = open(path)
self.datas = f.readlines()
self.L = len(self.datas)
self.index = random.sample(range(self.L), self.L)
self.queue = Queue(maxsize=30)
self.Process_num=32
for i in range(self.Process_num):
print(i,'start')
ii = int(self.__len__()/self.Process_num)
t = Process(target=self.f,args=(i*ii,(i+1)*ii))
t.start()
def __len__(self):
return self.L - self.batch_size
def __getitem__(self, idx):
batch_indexs = self.index[idx:(idx+self.batch_size)]
batch_datas = [self.datas[k] for k in batch_indexs]
img1s,img2s,audios,labels = self.data_generation(batch_datas)
return img1s,img2s,audios,labels
def f(self,i_l,i_h):
for i in range(i_l,i_h):
t = self.__getitem__(i)
self.queue.put(t)
def gen(self):
while 1:
t = self.queue.get()
yield t[0],t[1],t[2],t[3]
def data_generation(self, batch_datas):
#数据预处理操作
return img1s,img2s,audios,labels
epochs = 2
data_g = SequenceData('train_1.csv',batch_size=48)
dataset = tf.data.Dataset().batch(1).from_generator(data_g.gen,
output_types= (tf.float32,tf.float32,tf.float32,tf.float32))
X, y,z,w = dataset.make_one_shot_iterator().get_next()
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(epochs):
for j in range(int(len(data_g)/(data_g.batch_size))):
face1,face2,voice, labels = sess.run([X,y,z,w])
print(face1.shape)
然后,最后实现的效果

以上这篇Tensorflow 多线程与多进程数据加载实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Tensorflow 实现分批量读取数据
之前的博客里使用tf读取数据都是每次fetch一条记录,实际上大部分时候需要fetch到一个batch的小批量数据,在tf中这一操作的明显变化就是tensor的rank发生了变化,我目前使用的人脸数据集是灰度图像,因此大小是92*112的,所以最开始fetch拿到的图像数据集经过reshape之后就是一个rank为2的tensor,大小是92*112的(如果考虑通道,也可以reshape为rank为3的,即92*112*1). 如果加入batch,比如batch大小为5,那么拿到的tensor的
-
使用Tensorflow将自己的数据分割成batch训练实例
学习神经网络的时候,网上的数据集已经分割成了batch,训练的时候直接使用batch.next()就可以获取batch,但是有的时候需要使用自己的数据集,然而自己的数据集不是batch形式,就需要将其转换为batch形式,本文将介绍一个将数据打包成batch的方法. 一.tf.slice_input_producer() 首先需要讲解两个函数,第一个函数是 :tf.slice_input_producer(),这个函数的作用是从输入的tensor_list按要求抽取一个tensor放入文件名队列
-
tensorflow使用range_input_producer多线程读取数据实例
先放关键代码: i = tf.train.range_input_producer(NUM_EXPOCHES, num_epochs=1, shuffle=False).dequeue() inputs = tf.slice(array, [i * BATCH_SIZE], [BATCH_SIZE]) 原理解析: 第一行会产生一个队列,队列包含0到NUM_EXPOCHES-1的元素,如果num_epochs有指定,则每个元素只产生num_epochs次,否则循环产生.shuffle指定是否打乱顺
-
tensorflow实现对张量数据的切片操作方式
如下所示: import tensorflow as tf a=tf.constant([[[1,2,3,4],[4,5,6,7],[7,8,9,10]], [[11,12,13,14],[20,21,22,23],[15,16,17,18]]]) print(a.shape) b,c=tf.split(a,2,0) #参数1.张量 2.获得的切片数 3.切片的维度 将两个切片分别赋值给b,c print(b.shape) print(c.shape with tf.Session() as s
-
tensorflow mnist 数据加载实现并画图效果
关于 TensorFlow TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor).它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等.TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度
-
tensorflow tf.train.batch之数据批量读取方式
在进行大量数据训练神经网络的时候,可能需要批量读取数据.于是参考了这篇文章的代码,结果发现数据一直批量循环输出,不会在数据的末尾自动停止. 然后发现这篇博文说slice_input_producer()这个函数有一个形参num_epochs,通过设置它的值就可以控制全部数据循环输出几次. 于是我设置之后出现以下的报错: tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninit
-
tensorflow之并行读入数据详解
最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考. 并行读入数据主要分 1. 创建文件名列表 2. 创建文件名队列 3. 创建Reader和Decoder 4. 创建样例列表 5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要批列表来分批进行数据的组织,提取) 其具体流程如下: 一. 文件名列表: 文件名列表是一个list类型的数据,里面的内容是需要用的数据文件名.可以使用常规的python语法入:[file1
-
利用Tensorflow的队列多线程读取数据方式
在tensorflow中,有三种方式输入数据 1. 利用feed_dict送入numpy数组 2. 利用队列从文件中直接读取数据 3. 预加载数据 其中第一种方式很常用,在tensorflow的MNIST训练源码中可以看到,通过feed_dict={},可以将任意数据送入tensor中. 第二种方式相比于第一种,速度更快,可以利用多线程的优势把数据送入队列,再以batch的方式出队,并且在这个过程中可以很方便地对图像进行随机裁剪.翻转.改变对比度等预处理,同时可以选择是否对数据随机打乱,可以说是
-
Tensorflow 多线程与多进程数据加载实例
在项目中遇到需要处理超级大量的数据集,无法载入内存的问题就不用说了,单线程分批读取和处理(虽然这个处理也只是特别简单的首尾相连的操作)也会使瓶颈出现在CPU性能上,所以研究了一下多线程和多进程的数据读取和预处理,都是通过调用dataset api实现 1. 多线程数据读取 第一种方法是可以直接从csv里读取数据,但返回值是tensor,需要在sess里run一下才能返回真实值,无法实现真正的并行处理,但如果直接用csv文件或其他什么文件存了特征值,可以直接读取后进行训练,可使用这种方法. imp
-
python用pandas数据加载、存储与文件格式的实例
数据加载.存储与文件格式 pandas提供了一些用于将表格型数据读取为DataFrame对象的函数.其中read_csv和read_talbe用得最多 pandas中的解析函数: 函数 说明 read_csv 从文件.URL.文件型对象中加载带分隔符的数据,默认分隔符为逗号 read_table 从文件.URL.文件型对象中加载带分隔符的数据.默认分隔符为制表符("\t") read_fwf 读取定宽列格式数据(也就是说,没有分隔符) read_clipboard 读取剪贴板中的数据,
-

Python实现实时增量数据加载工具的解决方案
目录 创建增量ID记录表 数据库连接类 增量数据服务客户端 结果测试 本次主要分享结合单例模式实际应用案例:实现实时增量数据加载工具的解决方案.最关键的是实现一个可进行添加.修改.删除等操作的增量ID记录表. 单例模式:提供全局访问点,确保类有且只有一个特定类型的对象.通常用于以下场景:日志记录或数据库操作等,避免对用一资源请求冲突. 创建增量ID记录表 import sqlite3 import datetime import pymssql import pandas as pd impor
-
C#使用Jquery zTree实现树状结构显示 异步数据加载
C#使用Jquery zTree实现树状结构显示_异步数据加载 JQuery-Ztree下载地址:https://github.com/zTree/zTree_v3 JQuery-Ztree数结构演示页面: http://www.treejs.cn/v3/demo.php#_101 关于zTree的详细解释请看演示页面,还有zTree帮助Demo. 下面简要讲解下本人用到的其中一个实例(直接上关键代码了): 异步加载节点数据: A-前台: <link href="zTree_v3-mas
-
jQuery zTree树插件动态加载实例代码
需求: 由于项目中家谱图数据量超大,而一般加载方式是通过,页面加载时 zTree.init方法进行数据加载,将所有数据一次性加载到页面中.而在项目中家谱级别又非常广而深,成千上万级,因此一次加载,完全加载不出来.于是需要进行优化为动态加载(增量加载)的方式,以便数据加载,提高体验度. 解决断路: 这应该好办,只要找到父节点单击事件,然后进行数据加载,结点附加即可.时间紧,任务重,完全没给研究的时间.只能硬着上,随便搜索一个"zTree动态加载",出是出来了,标题也对,可里面的代码根本没
-
Android自定义加载控件实现数据加载动画
本文实例为大家分享了Android自定义加载控件,第一次小人跑动的加载效果眼前一亮,相比传统的PrograssBar高大上不止一点,于是走起,自定义了控件LoadingView去实现动态效果,可直接在xml中使用,具体实现如下 package com.*****.*****.widget; import android.content.Context; import android.graphics.drawable.AnimationDrawable; import android.util.
-
vue在使用ECharts时的异步更新和数据加载详解
前言 最近在学习eCharts,学习到了异步更新和数据加载这一块,觉着有必要总结一下,方法以后的时候参考学习,在开始本文之前,对eCharts不熟悉的朋友们可以参考下这篇文章:http://www.jb51.net/article/128790.htm 下面话不多说了,来一起看看详细的介绍吧. 使用方法 使用Echarts首先得先把Echarts.js引进来(放在文件的入口html文件里面) <script src="public/js/echarts.common.min.js&quo
-
原生ajax写的上拉加载实例
上拉加载的思路 1 上拉加载是要把屏幕拉到最底部的时候触发ajax事件请求数据 2.所有要获取屏幕的高度 文档的高度 和滚动的高度 下面的代码是已经做好了兼容的可以直接拿来用 Javascript: alert(document.body.clientWidth); //网页可见区域宽(body) alert(document.body.clientHeight); //网页可见区域高(body) alert(document.body.offsetWidth); //网页可见区域宽(body)
-
Vue3异步数据加载组件suspense的使用方法
目录 前言 创建组件 总结 前言 Vue3 增加了很多让人眼前一亮的特征,suspense 组件就是其中之一,对处理异步请求数据非常实用,本文通过简单的实例介绍其使用方法,如对其有兴趣,可以参阅官方文档. 通常组件在正确呈现之前需要执行某种异步请求是很常见的,通常是通过设计一种机制开发人员按照机制处理这个问题,有很多很好的方法实现这个需求. 例如,从一个 API 异步获取数据,并希望在获取响应数据解析完时显示一些信息,如 loading 效果,在Vue3中可以使用 suspense 组件来执行这