pytorch 中autograd.grad()函数的用法说明
我们在用神经网络求解PDE时, 经常要用到输出值对输入变量(不是Weights和Biases)求导; 在训练WGAN-GP 时, 也会用到网络对输入变量的求导。
以上两种需求, 均可以用pytorch 中的autograd.grad() 函数实现。
autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False)
outputs: 求导的因变量(需要求导的函数)
inputs: 求导的自变量
grad_outputs: 如果 outputs为标量,则grad_outputs=None,也就是说,可以不用写; 如果outputs 是向量,则此参数必须写,不写将会报如下错误:

那么此参数究竟代表着什么呢?
先假设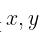 为一维向量, 即可设自变量因变量分别为
为一维向量, 即可设自变量因变量分别为 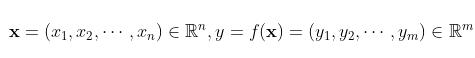 , 其对应的 Jacobi 矩阵为
, 其对应的 Jacobi 矩阵为

grad_outputs 是一个shape 与 outputs 一致的向量, 即
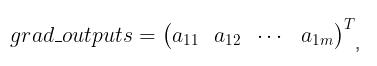
在给定grad_outputs 之后,真正返回的梯度为
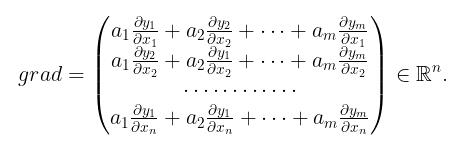
为方便下文叙述我们引入记号 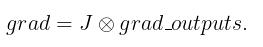
其次假设 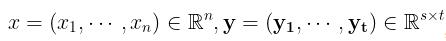 ,第i个列向量对应的Jacobi矩阵为
,第i个列向量对应的Jacobi矩阵为
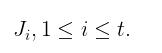
此时的grad_outputs 为(维度与outputs一致)
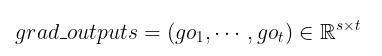
由第一种情况, 我们有
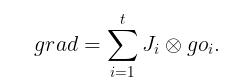
也就是说对输出变量的列向量求导,再经过权重累加。
若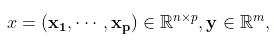 沿用第一种情况记号
沿用第一种情况记号
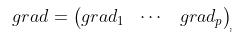 , 其中每一个
, 其中每一个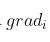 均由第一种方法得出,
均由第一种方法得出,
即对输入变量列向量求导,之后按照原先顺序排列即可。
retain_graph: True 则保留计算图, False则释放计算图
create_graph: 若要计算高阶导数,则必须选为True
allow_unused: 允许输入变量不进入计算
下面我们看一下具体的例子:
import torch from torch import autograd x = torch.rand(3, 4) x.requires_grad_()
观察 x 为

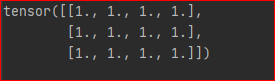
不妨设 y 是 x 所有元素的和, 因为 y是标量,故计算导数不需要设置grad_outputs
y = torch.sum(x) grads = autograd.grad(outputs=y, inputs=x)[0] print(grads)
结果为
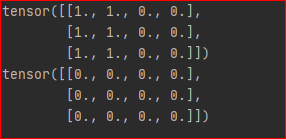
若y是向量
y = x[:,0] +x[:,1] # 设置输出权重为1 grad = autograd.grad(outputs=y, inputs=x, grad_outputs=torch.ones_like(y))[0] print(grad) # 设置输出权重为0 grad = autograd.grad(outputs=y, inputs=x, grad_outputs=torch.zeros_like(y))[0] print(grad)
结果为
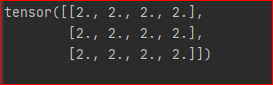
最后, 我们通过设置 create_graph=True 来计算二阶导数
y = x ** 2 grad = autograd.grad(outputs=y, inputs=x, grad_outputs=torch.ones_like(y), create_graph=True)[0] grad2 = autograd.grad(outputs=grad, inputs=x, grad_outputs=torch.ones_like(grad))[0] print(grad2)
结果为
综上,我们便搞清楚了它的求导机制。
补充:pytorch学习笔记:自动微分机制(backward、torch.autograd.grad)
一、前言
神经网络通常依赖反向传播求梯度来更新网络参数,求梯度过程通常是一件非常复杂而容易出错的事情。
而深度学习框架可以帮助我们自动地完成这种求梯度运算。
Pytorch一般通过反向传播 backward方法 实现这种求梯度计算。该方法求得的梯度将存在对应自变量张量的grad属性下。
除此之外,也能够调用torch.autograd.grad函数来实现求梯度计算。
这就是Pytorch的自动微分机制。
二、利用backward方法求导数
backward方法通常在一个标量张量上调用,该方法求得的梯度将存在对应自变量张量的grad属性下。如果调用的张量非标量,则要传入一个和它同形状的gradient参数张量。相当于用该gradient参数张量与调用张量作向量点乘,得到的标量结果再反向传播。
1, 标量的反向传播
import numpy as np import torch # f(x) = a*x**2 + b*x + c的导数 x = torch.tensor(0.0,requires_grad = True) # x需要被求导 a = torch.tensor(1.0) b = torch.tensor(-2.0) c = torch.tensor(1.0) y = a*torch.pow(x,2) + b*x + c y.backward() dy_dx = x.grad print(dy_dx)
输出:
tensor(-2.)
2, 非标量的反向传播
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c
x = torch.tensor([[0.0,0.0],[1.0,2.0]],requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
print("x:\n",x)
print("y:\n",y)
y.backward(gradient = gradient)
x_grad = x.grad
print("x_grad:\n",x_grad)
输出:
x:
tensor([[0., 0.],
[1., 2.]], requires_grad=True)
y:
tensor([[1., 1.],
[0., 1.]], grad_fn=<AddBackward0>)
x_grad:
tensor([[-2., -2.],
[ 0., 2.]])
3, 非标量的反向传播可以用标量的反向传播实现
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c
x = torch.tensor([[0.0,0.0],[1.0,2.0]],requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
z = torch.sum(y*gradient)
print("x:",x)
print("y:",y)
z.backward()
x_grad = x.grad
print("x_grad:\n",x_grad)
输出:
x: tensor([[0., 0.],
[1., 2.]], requires_grad=True)
y: tensor([[1., 1.],
[0., 1.]], grad_fn=<AddBackward0>)
x_grad:
tensor([[-2., -2.],
[ 0., 2.]])
三、利用autograd.grad方法求导数
import numpy as np import torch # f(x) = a*x**2 + b*x + c的导数 x = torch.tensor(0.0,requires_grad = True) # x需要被求导 a = torch.tensor(1.0) b = torch.tensor(-2.0) c = torch.tensor(1.0) y = a*torch.pow(x,2) + b*x + c # create_graph 设置为 True 将允许创建更高阶的导数 dy_dx = torch.autograd.grad(y,x,create_graph=True)[0] print(dy_dx.data) # 求二阶导数 dy2_dx2 = torch.autograd.grad(dy_dx,x)[0] print(dy2_dx2.data)
输出:
tensor(-2.)
tensor(2.)
import numpy as np
import torch
x1 = torch.tensor(1.0,requires_grad = True) # x需要被求导
x2 = torch.tensor(2.0,requires_grad = True)
y1 = x1*x2
y2 = x1+x2
# 允许同时对多个自变量求导数
(dy1_dx1,dy1_dx2) = torch.autograd.grad(outputs=y1,
inputs = [x1,x2],retain_graph = True)
print(dy1_dx1,dy1_dx2)
# 如果有多个因变量,相当于把多个因变量的梯度结果求和
(dy12_dx1,dy12_dx2) = torch.autograd.grad(outputs=[y1,y2],
inputs = [x1,x2])
print(dy12_dx1,dy12_dx2)
输出:
tensor(2.) tensor(1.)
tensor(3.) tensor(2.)
四、利用自动微分和优化器求最小值
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的最小值
x = torch.tensor(0.0,requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
optimizer = torch.optim.SGD(params=[x],lr = 0.01)
def f(x):
result = a*torch.pow(x,2) + b*x + c
return(result)
for i in range(500):
optimizer.zero_grad()
y = f(x)
y.backward()
optimizer.step()
print("y=",f(x).data,";","x=",x.data)
输出:
y= tensor(0.) ; x= tensor(1.0000)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

浅谈Pytorch中autograd的若干(踩坑)总结
关于Variable和Tensor 旧版本的Pytorch中,Variable是对Tensor的一个封装:在Pytorch大于v0.4的版本后,Varible和Tensor合并了,意味着Tensor可以像旧版本的Variable那样运行,当然新版本中Variable封装仍旧可以用,但是对Varieble操作返回的将是一个Tensor. import torch as t from torch.autograd import Variable a = t.ones(3,requires_grad=
-
PyTorch中model.zero_grad()和optimizer.zero_grad()用法
废话不多说,直接上代码吧~ model.zero_grad() optimizer.zero_grad() 首先,这两种方式都是把模型中参数的梯度设为0 当optimizer = optim.Optimizer(net.parameters())时,二者等效,其中Optimizer可以是Adam.SGD等优化器 def zero_grad(self): """Sets gradients of all model parameters to zero.""
-
浅谈Pytorch中的自动求导函数backward()所需参数的含义
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿. 对标量自动求导 首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的. import torch from torch.autograd import Variable a = Variable(torch.Te
-
pytorch 中autograd.grad()函数的用法说明
我们在用神经网络求解PDE时, 经常要用到输出值对输入变量(不是Weights和Biases)求导: 在训练WGAN-GP 时, 也会用到网络对输入变量的求导. 以上两种需求, 均可以用pytorch 中的autograd.grad() 函数实现. autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False
-
pytorch中的 .view()函数的用法介绍
目录 一.普通用法(手动调整size) 二.特殊用法:参数-1(自动调整size) 一.普通用法 (手动调整size) view()相当于reshape.resize,重新调整Tensor的形状. import torch a1 = torch.arange(0,16) print(a1) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]) a2 = a1.view(8, 2) a3 = a1.vi
-
php中正则替换函数ereg_replace用法实例
本文实例讲述了php中正则替换函数ereg_replace用法.分享给大家供大家参考.具体如下: 下面的实例是利用php 正则替换函数 ereg_replace来把指定的字符替换成我想需要的字符实例,代码如下: 复制代码 代码如下: $num = 'www.jb51.net'; $string = "this string has four words. <br>"; $string = ereg_replace ('four', $num, $string); echo
-
JavaScript中字符串分割函数split用法实例
本文实例讲述了JavaScript中字符串分割函数split用法.分享给大家供大家参考.具体如下: 先来看下面这段代码: <script type="text/javascript"> var str="How are you doing today?" document.write(str.split(" ") + "<br />") document.write(str.split("&q
-
ES6中Array.includes()函数的用法
在ES5,Array已经提供了indexOf用来查找某个元素的位置,如果不存在就返回-1,但是这个函数在判断数组是否包含某个元素时有两个小不足,第一个是它会返回-1和元素的位置来表示是否包含,在定位方面是没问题,就是不够语义化.另一个问题是不能判断是否有NaN的元素. const arr1 = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', NaN] console.log('%s', arr1.indexOf(NaN)) 结果:
-
python中去空格函数的用法
本文简单介绍了Python中去空格函数的用法,这是一个很实用的函数,希望对大家的Python程序设计有所帮助.具体分析如下: 在Python中字符串处理函数里有三个去空格的函数: strip 同时去掉左右两边的空格 lstrip 去掉左边的空格 rstrip 去掉右边的空格 具体示例如下: >>>a=" gho stwwl " >>>a.lstrip() 'gho stwwl ' >>>a.rstrip() ' gho stwwl'
-
ES6中Array.copyWithin()函数的用法实例详解
ES6为Array增加了copyWithin函数,用于操作当前数组自身,用来把某些个位置的元素复制并覆盖到其他位置上去. Array.prototype.copyWithin(target, start = 0, end = this.length) 该函数有三个参数. target:目的起始位置. start:复制源的起始位置,可以省略,可以是负数. end:复制源的结束位置,可以省略,可以是负数,实际结束位置是end-1. 例: 把第3个元素(从0开始)到第5个元素,复制并覆盖到以第1个位置
-
thinkphp中字符截取函数msubstr()用法分析
本文实例讲述了thinkphp中字符截取函数msubstr()用法.分享给大家供大家参考,具体如下: ThinkPHP有一个内置字符截取函数msubstr()如下: msubstr($str, $start=0, $length, $charset="utf-8", $suffix=true) $str:要截取的字符串 $start=0:开始位置,默认从0开始 $length:截取长度 $charset="utf-8":字符编码,默认UTF-8 $suffix=tr
-
浅谈OpenCV中的新函数connectedComponentsWithStats用法
主要内容:对比新旧函数,用于过滤原始图像中轮廓分析后较小的区域,留下较大区域. 关键字:connectedComponentsWithStats 在以前,常用的方法是"是先调用 cv::findContours() 函数(传入cv::RETR_CCOMP 标志),随后在得到的连通区域上循环调用 cv::drawContours() " 比如,我在GOCVHelper中这样进行了实现 //寻找最大的轮廓 VP FindBigestContour(Mat src){ int imax =