java 数据结构并查集详解
目录
- 一、概述
- 二、实现
- 2.1 Quick Find实现
- 2.2 Quick Union实现
- 三、优化
- 3.1基于size的优化
- 3.2基于rank优化
- 3.2.1路径压缩(Path Compression )
- 3.2.2路径分裂(Path Spliting)
- 3.2.3路径减半(Path Halving)
一、概述
并查集:一种树型数据结构,用于解决一些不相交集合的合并及查询问题。例如:有n个村庄,查询2个村庄之间是否有连接的路,连接2个村庄
两大核心:
查找 (Find) : 查找元素所在的集合
合并 (Union) : 将两个元素所在集合合并为一个集合
二、实现
并查集有两种常见的实现思路
快查(Quick Find)
- 查找(Find)的时间复杂度:O(1)
- 合并(Union)的时间复杂度:O(n)
快并(Quick Union)
- 查找(Find)的时间复杂度:O(logn)可以优化至O(a(n))a(n)< 5
- 合并(Union)的时间复杂度:O(logn)可以优化至O(a(n))a(n)< 5
使用数组实现树型结构,数组下标为元素,数组存储的值为父节点的值
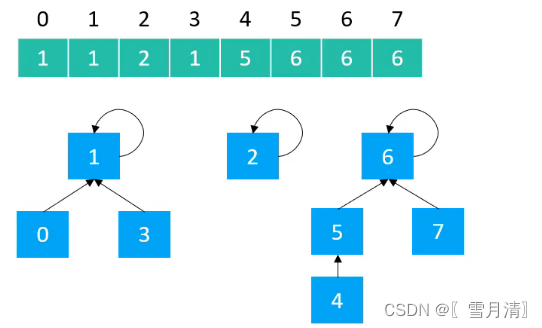
创建抽象类Union Find
public abstract class UnionFind {
int[] parents;
/**
* 初始化并查集
* @param capacity
*/
public UnionFind(int capacity){
if(capacity < 0) {
throw new IllegalArgumentException("capacity must be >=0");
}
//初始时每一个元素父节点(根结点)是自己
parents = new int[capacity];
for(int i = 0; i < parents.length;i++) {
parents[i] = i;
}
}
/**
* 检查v1 v2 是否属于同一个集合
*/
public boolean isSame(int v1,int v2) {
return find(v1) == find(v2);
}
/**
* 查找v所属的集合 (根节点)
*/
public abstract int find(int v);
/**
* 合并v1 v2 所属的集合
*/
public abstract void union(int v1, int v2);
// 范围检查
public void rangeCheck(int v) {
if(v<0 || v > parents.length)
throw new IllegalArgumentException("v is out of capacity");
}
}
2.1 Quick Find实现
以Quick Find实现的并查集,树的高度最高为2,每个节点的父节点就是根节点
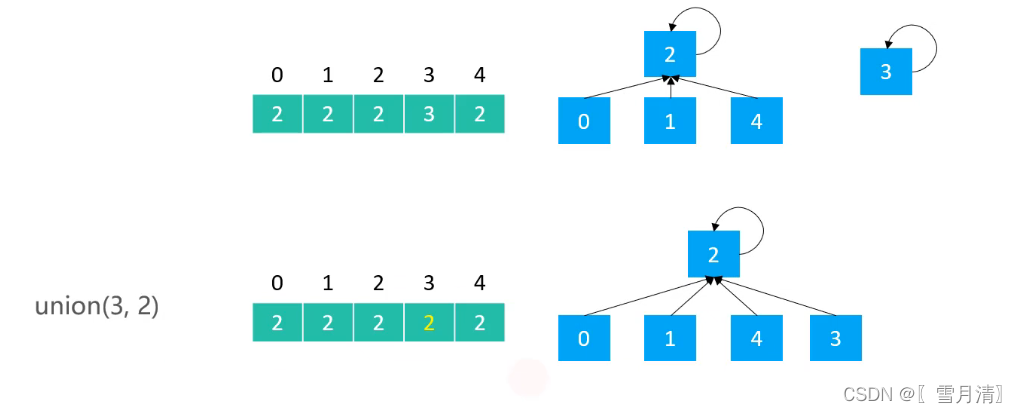
public class UnionFind_QF extends UnionFind {
public UnionFind_QF(int capacity) {
super(capacity);
}
// 查
@Override
public int find(int v) {
rangeCheck(v);
return parents[v];
}
// 并 将v1所在集合并到v2所在集合上
@Override
public void union(int v1, int v2) {
// 查找v1 v2 的父(根)节点
int p1= find(v1);
int p2 = find(v2);
if(p1 == p2) return;
//将所有以v1的根节点为根节点的元素全部并到v2所在集合上 即父节点改为v2的父节点
for(int i = 0; i< parents.length; i++) {
if(parents[i] == p1) {
parents[i] = p2;
}
}
}
}
2.2 Quick Union实现
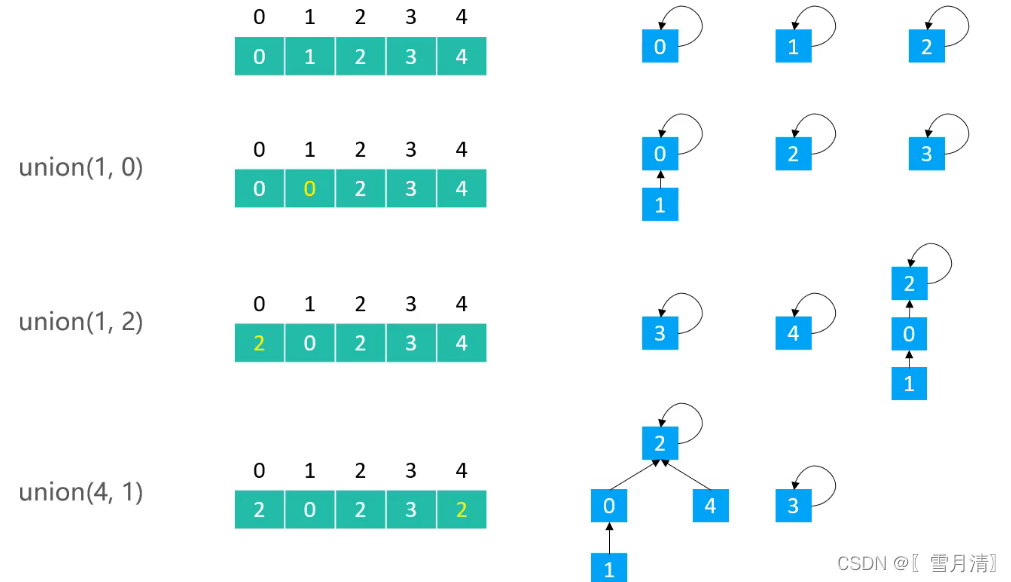
public class UnionFind_QU extends UnionFind {
public UnionFind_QU(int capacity) {
super(capacity);
}
//查某一个元素的根节点
@Override
public int find(int v) {
//检查下标是否越界
rangeCheck(v);
// 一直循环查找节点的根节点
while (v != parents[v]) {
v = parents[v];
}
return v;
}
//V1 并到 v2 中
@Override
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if(p1 == p2) return;
//将v1 根节点 的 父节点 修改为 v2的根结点 完成合并
parents[p1] = p2;
}
}
三、优化
并查集常用快并来实现,但是快并有时会出现树不平衡的情况
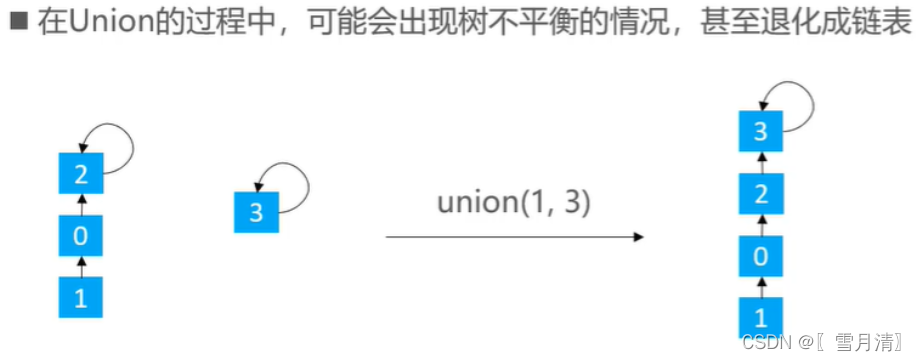
有两种优化思路:rank优化,size优化
3.1基于size的优化
核心思想:元素少的树 嫁接到 元素多的树
public class UniondFind_QU_S extends UnionFind{
// 创建sizes 数组记录 以元素(下标)为根结点的元素(节点)个数
private int[] sizes;
public UniondFind_QU_S(int capacity) {
super(capacity);
sizes = new int[capacity];
//初始都为 1
for(int i = 0;i < sizes.length;i++) {
sizes[i] = 1;
}
}
@Override
public int find(int v) {
rangeCheck(v);
while (v != parents[v]) {
v = parents[v];
}
return v;
}
@Override
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if(p1 == p2) return;
//如果以p1为根结点的元素个数 小于 以p2为根结点的元素个数 p1并到p2上,并且更新p2为根结点的元素个数
if(sizes[p1] < sizes[p2]) {
parents[p1] = p2;
sizes[p2] += sizes[p1];
// 反之 则p2 并到 p1 上,更新p1为根结点的元素个数
}else {
parents[p2] = p1;
sizes[p1] += sizes[p2];
}
}
}
基于size优化还有可能会导致树不平衡
3.2基于rank优化
核心思想:矮的树 嫁接到 高的树
public class UnionFind_QU_R extends UnionFind_QU {
// 创建rank数组 ranks[i] 代表以i为根节点的树的高度
private int[] ranks;
public UnionFind_QU_R(int capacity) {
super(capacity);
ranks = new int[capacity];
for(int i = 0;i < ranks.length;i++) {
ranks[i] = 1;
}
}
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if(p1 == p2) return;
// p1 并到 p2 上 p2为根 树的高度不变
if(ranks[p1] < ranks[p2]) {
parents[p1] = p2;
// p2 并到 p1 上 p1为根 树的高度不变
} else if(ranks[p1] > ranks[p2]) {
parents[p2] = p1;
}else {
// 高度相同 p1 并到 p2上,p2为根 树的高度+1
parents[p1] = p2;
ranks[p2] += 1;
}
}
}
基于rank优化,随着Union次数的增多,树的高度依然会越来越高 导致find操作变慢
有三种思路可以继续优化 :路径压缩、路径分裂、路径减半
3.2.1路径压缩(Path Compression )
在find时使路径上的所有节点都指向根节点,从而降低树的高度
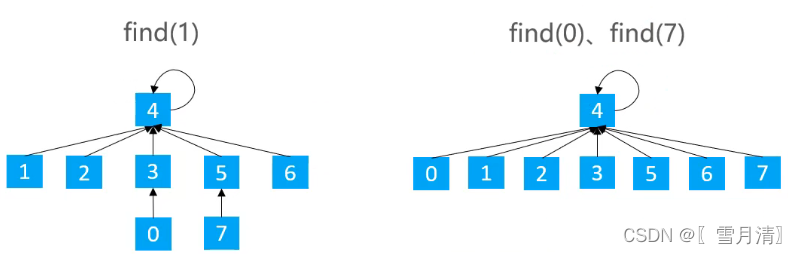
/**
* Quick Union -基于rank的优化 -路径压缩
*
*/
public class UnionFind_QU_R_PC extends UnionFind_QU_R {
public UnionFind_QU_R_PC(int capacity) {
super(capacity);
}
@Override
public int find(int v) {
rangeCheck(v);
if(parents[v] != v) {
//递归 使得从当前v 到根节点 之间的 所有节点的 父节点都改为根节点
parents[v] = find(parents[v]);
}
return parents[v];
}
}
虽然能降低树的高度,但是实现成本稍高
3.2.2路径分裂(Path Spliting)
使路径上的每个节点都指向其祖父节点
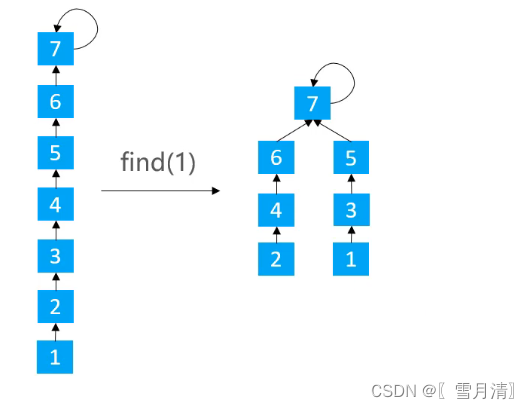
/**
* Quick Union -基于rank的优化 -路径分裂
*
*/
public class UnionFind_QU_R_PS extends UnionFind_QU_R {
public UnionFind_QU_R_PS(int capacity) {
super(capacity);
}
@Override
public int find(int v) {
rangeCheck(v);
while(v != parents[v]) {
int p = parents[v];
parents[v] = parents[parents[v]];
v = p;
}
return v;
}
}
3.2.3路径减半(Path Halving)
使路径上每隔一个节点就指向其祖父节点
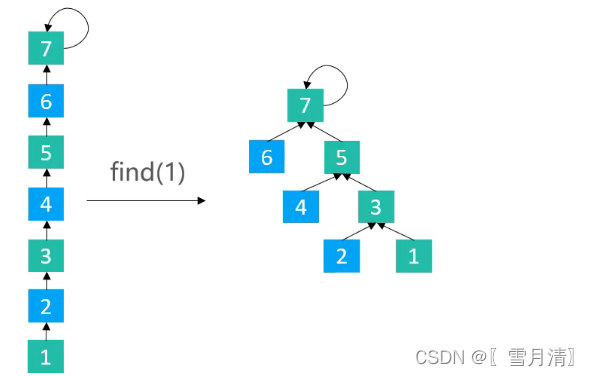
/**
* Quick Union -基于rank的优化 -路径减半
*
*/
public class UnionFind_QU_R_PH extends UnionFind_QU_R {
public UnionFind_QU_R_PH(int capacity) {
super(capacity);
}
public int find(int v) {
rangeCheck(v);
while(v != parents[v]) {
parents[v] = parents[parents[v]];
v = parents[v];
}
return v;
}
}
使用Quick Union + 基于rank的优化 + 路径分裂 或 路径减半
可以保证每个操作的均摊时间复杂度为O(a(n)) , a(n) < 5
到此这篇关于java 数据结构并查集详解的文章就介绍到这了,更多相关java 并查集内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

java编程实现并查集的路径压缩代码详解
首先看两张路径压缩的图片: 并查集(Union-find Sets)是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图.求最小生成树的 Kruskal 算法和求最近公共祖先(Least Common Ancestors, LCA)等. 使用并查集时,首先会存在一组不相交的动态集合 S={S 1 ,S 2 ,⋯,S k } ,一般都会使用一个整数表示集合中的一个元素. 每个集合可能包含一个或多个元素,并选出集合中的某个元素作为代表.每个集合中具体包含
-
Java数据结构之并查集的实现
目录 代码解析 代码应用 实际应用 并查集就是将原本不在一个集合里面的内容合并到一个集合中. 在实际的场景中用处不多. 除了出现在你需要同时去几个集合里面查询,避免出现查询很多次,从而放在一起查询的情况. 下面简单实现一个例子,我们来举例说明一下什么是并查集,以及究竟并查集解决了什么问题. 代码解析 package com.chaojilaji.book.andcheck; public class AndCheckSet { public static Integer getFather(in
-
Java实现快速并查集
在一些应用的问题中,需将n个不同的元素划分成一组不相交的集合.开始时,每个元素自成一格单元素集合,然后按一定顺序将属于同一组的元素的集合合并.其间要反复用到查询某个元素属于哪个集合的运算.适合于描述这类问题的抽象数据类型称为并查集. 1. 并查集的概述 并查集的数学模型是一组不相交的动态集合的集合S={A,B,C,...},它支持以下的运算: (1)union(A,B):将集合A和B合并,其结果取名为A或B: (2)find(x):找出包含元素x的集合,并返回该集合的名字. 在并查集中需要两个类
-
详解Java实现数据结构之并查集
一.什么是并查集 对于一种数据结构,肯定是有自己的应用场景和特性,那么并查集是处理什么问题的呢? 并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的合并及查询问题,常常在使用中以森林来表示.在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受:即使在空
-
Java实现并查集示例详解
目录 题目 思路 find实现 join的实现 整体代码 题目 题目背景 若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系. 思路 对于该题而言,考察的是并查集,也就是小怪兽逐个找上级领导的思路,指导找到最终的Boss停止下来,如果两个怪兽要打架,需要问一问他们的上级领导,领导再问领导,逐级向上,最终发现它们属于同一个Boss的部署的话就不能再打架了,这道题同样的思路,如果斗罗大陆的一开始白沉香不知道唐三是亲戚的话,他们就
-
Java实现并查集
本文实例为大家分享了Java实现并查集的具体代码,供大家参考,具体内容如下 自下而上的树结构 接口 /** * @author Nino */ public interface UF { int size(); /** * 看两个元素是否相连 * @param p * @param q * @return */ boolean isConnected(int p, int q); /** * 将两个元素合并在一起,变成一个集合中的元素 * @param p * @param q */ void
-
java并查集算法带你领略热血江湖
目录 一.什么是并查集 二.深入理解并查集 三.实现并查集 四.真题训练 五.路径压缩优化 六.总结 你好,我是小黄,一名独角兽企业的Java开发工程师. 校招收获数十个offer,年薪均20W~40W. 感谢茫茫人海中我们能够相遇, 俗话说:当你的才华和能力,不足以支撑你的梦想的时候,请静下心来学习, 希望优秀的你可以和我一起学习,一起努力,实现属于自己的梦想. 一.什么是并查集 并查集被很多OIer认为是最简洁而优雅的数据结构之一,主要用于处理一些不相交集合的合并问题,并支持两种操作: 合并
-
Java数据机构中关于并查集的详解
目录 概念 实现 初始化并查集 判断是不是同一个组 查找当前节点的代表节点 合并操作 本期文章源码:GitHub 一文彻底搞懂<并查集>! 概念 并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题(即所谓的并.查).比如说,我们可以用并查集来判断一个森林中有几棵树.某个节点是否属于某棵树等. 具体的用法,我们会以下一篇文章<图的相关算法>中,有一个克鲁斯卡尔算法,用于生成最小生成树,会用到并查集. 并查集的主要作用是求连通分支数(如果一个图中所有点都存在可达关系(直
-
Java使用HashMap实现并查集
并查集的定义: 并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.这一类问题近几年来反复出现在信息学的国际国内赛题中,其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述. 并查集是一种树型的数
-
java 数据结构并查集详解
目录 一.概述 二.实现 2.1 Quick Find实现 2.2 Quick Union实现 三.优化 3.1基于size的优化 3.2基于rank优化 3.2.1路径压缩(Path Compression ) 3.2.2路径分裂(Path Spliting) 3.2.3路径减半(Path Halving) 一.概述 并查集:一种树型数据结构,用于解决一些不相交集合的合并及查询问题.例如:有n个村庄,查询2个村庄之间是否有连接的路,连接2个村庄 两大核心: 查找 (Find) : 查找元素所在
-
Java数据结构之散列表详解
目录 介绍 1 散列表概述 1.1 散列表概述 1.2 散列冲突(hash collision) 2 散列函数的选择 2.1 散列函数的要求 2.2 散列函数构造方法 3 散列冲突的解决 3.1 分离链接法 3.2 开放定址法 3.3 再散列法 4 散列表的简单实现 4.1 测试 介绍 本文详细介绍了散列表的概念.散列函数的选择.散列冲突的解决办法,并且最后提供了一种散列表的Java代码实现. 数组的特点是寻址容易,插入和删除困难:而链表的特点是寻址困难,插入和删除容易.而对于tree结构,它们
-
Java数据结构之KMP算法详解以及代码实现
目录 暴力匹配算法(Brute-Force,BF) 概念和原理 next数组 KMP匹配 KMP全匹配 总结 我们此前学了前缀树Trie的实现原理以及Java代码的实现.Trie树很好,但是它只能基于前缀匹配实现功能.但是如果我们的需求是:一个已知字符串中查找子串,并且子串并不一定符合前缀匹配,那么此时Trie树就无能为力了. 实际上这种字符串匹配的需求,在开发中非常常见,例如判断一个字符串是否包括某些子串,然后进行分别的处理. 暴力匹配算法(Brute-Force,BF) 这是最常见的算法字符
-
Java数据结构之单链表详解
一.图示 二.链表的概念及结构 链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 . 实际中链表的结构非常多样,以下情况组合起来就有8种链表结构: 单向.双向 带头.不带头 循环.非循环 今天,我们实现的是一个 单向 无头 非循环的链表. 下面是此链表的结构组成. 三.单链表的实现 (1)定义一个节点类型 我们创建一个 ListNode 的类作为节点类型,那么我们如何定义成员属性呢? 通过上面的结构分析,我们需要定义两个成员变量 val --作为该节点的
-
Java数据结构顺序表用法详解
目录 1.什么是顺序表 2.顺序表的基本功能和结构 3.顺序表基本功能的实现和解析 1.判断线性表是否为空 2.获取指定位置的元素 3.向线性表表添加元素 4.在位置i处插入元素 5.删除指定位置的元素,并返回该元素 6.查找t第一次出现的位置 7.手动扩容方法 1.什么是顺序表 在程序中,经常需要将一组(通常是同为某个类型的)数据元素作为整体管理和使用,需要创建这种元素组,用变量记录它们,传进传出函数等.一组数据中包含的元素个数可能发生变化(可以增加或删除元素). 对于这种需求,最简单的解决方
-
Java数据结构之线段树详解
目录 介绍 代码实现 线段树构建 区间查询 更新 总结 介绍 线段树(又名区间树)也是一种二叉树,每个节点的值等于左右孩子节点值的和,线段树示例图如下 以求和为例,根节点表示区间0-5的和,左孩子表示区间0-2的和,右孩子表示区间3-5的和,依次类推. 代码实现 /** * 使用数组实现线段树 */ public class SegmentTree<E> { private Node[] data; private int size; private Merger<E> merge
-
Java数据结构之堆(优先队列)详解
目录 堆的性质 堆的分类 堆的向下调整 堆的建立 堆得向上调整 堆的常用操作 入队列 出队列 获取队首元素 TopK 问题 例子 数组排序 堆的性质 堆逻辑上是一棵完全二叉树,堆物理上是保存在数组中 . 总结:一颗完全二叉树以层序遍历方式放入数组中存储,这种方式的主要用法就是堆的表示. 并且 如果已知父亲(parent) 的下标, 则: 左孩子(left) 下标 = 2 * parent + 1; 右孩子(right) 下标 = 2 * parent + 2; 已知孩子(不区分左右)(child
-
Java数据结构之对象比较详解
目录 1. PriorityQueue中插入对象 2. 元素的比较 2.1 基本类型的比较 2.2 对象比较的问题 3. 对象的比较 3.1 覆写基类的equals 3.2 基于Comparble接口类的比较 3.3 基于比较器比较 3.4 三种方式的对比 4.集合框架中PriorityQueue的比较方式 本篇博客主要内容: Java中对象的比较 集合框架中PriorityQueue的比较方式 模拟实现PriorityQueue 1. PriorityQueue中插入对象 优先级队列在插入元素
-
Java数据结构之栈的详解
目录 栈的抽象定义 顺序栈-----------使用数组表示栈空间 总结 栈是先进后出的特殊线性表,只允许在表的末端进行插入和删除,后面将介绍两种实现栈的方式,分别是基于数组的实现.基于链表的实现. 栈的抽象定义 class Mystack { public: Mystack() {} virtual void push(int &x) = 0; virtual bool pop(int &x) = 0; virtual bool Top(int &x) const = 0; vi
-
Java数据结构之链表的增删查改详解
一.链表的概念和结构 1.1 链表的概念 简单来说链表是物理上不一定连续,但是逻辑上一定连续的一种数据结构 1.2 链表的分类 实际中链表的结构非常多样,以下情况组合起来就有8种链表结构. 单向和双向,带头和不带头,循环和非循环.排列组合和会有8种. 但我这只是实现两种比较难的链表,理解之后其它6种就比较简单了 1.单向不带头非循环链表 2.双向不带头非循环链表 二.单向不带头非循环链表 2.1 创建节点类型 我们创建了一个 ListNode 类为节点类型,里面有两个成员变量,val用来存储数值