python按列索引提取文件夹内所有excel指定列汇总(示例代码)
目录
- 前言
- 一、情景描述
- 二、python汇总
- 总结
前言
一、情景描述
情景一:
文件夹内有很多excel数据,包含的数据格式一样,我们需要提取每个文件中指定的几列数据汇总到一个文件中(因为是按列索引提取,所以列的顺序可以不一样)
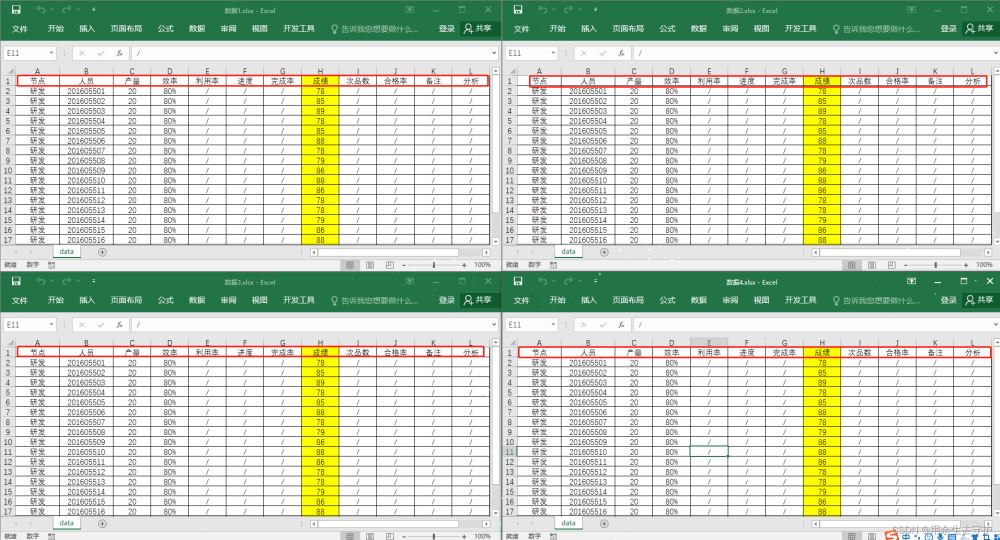
汇总后:
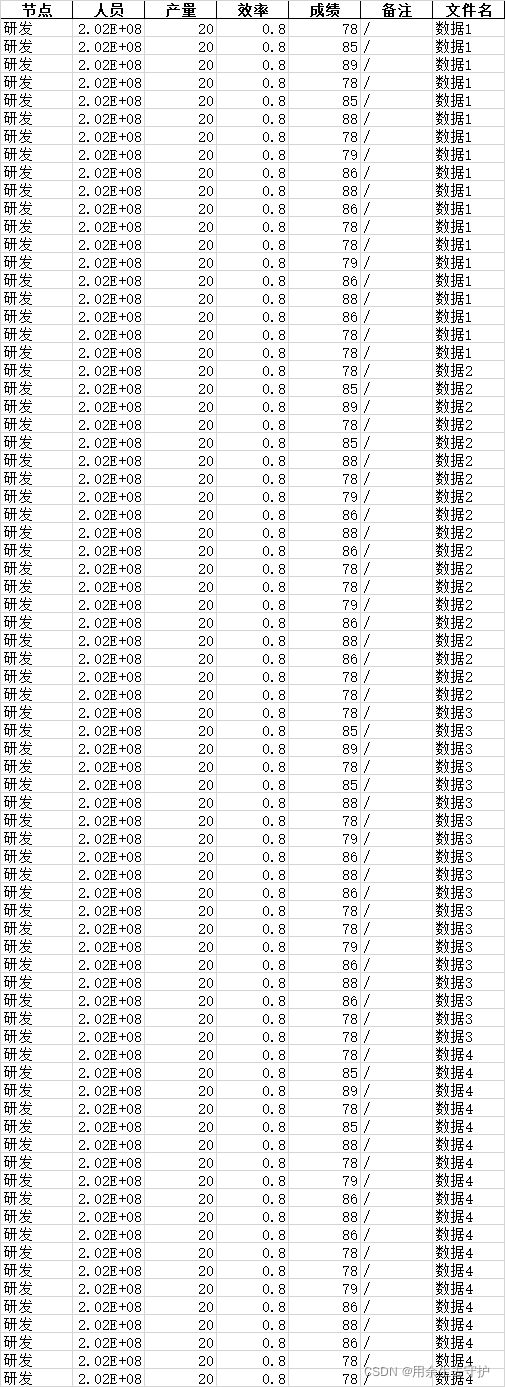
二、python汇总
注意事项:
- 文件所在文件夹内只能有运行文件.py,和需要汇总的文件,不能有其它文件夹,否则会出现运行错误;
- 运行第二遍时需要将第一遍运行得到的结果文件res.xlsx删除,否则也会出现运行错误;
代码如下(示例):
# -*- coding:utf-8 –*-
import os
import pandas as pd
# 输入参数为excel表格所在目录
def to_one_excel(dir):
dfs = []
# 遍历文件目录,将所有表格表示为pandas中的DataFrame对象
# for root_dir, sub_dir, files in os.walk(r'' + dir): # 第一个为起始路径,第二个为起始路径下的文件夹,第三个是起始路径下的文件。
for root_dir, sub_dir, files in os.walk(dir): # 第一个为起始路径,第二个为起始路径下的文件夹,第三个是起始路径下的文件。
for file in files:
if file.endswith('xlsx'):
# 构造绝对路径
file_name = os.path.join(root_dir, file)
# df = pd.read_excel(file_name)
df_1 = list(pd.read_excel(file_name, nrows=1)) # 读取excel第一行数据并放进列表
# excel第一行数据返回列表
print(file_name)
print(type(df_1))
print(df_1)
# 根据第一行列名获取每个文件中需要列的列索引,返回索引数值
suo_yin_1 = df_1.index("人员")
suo_yin_2 = df_1.index("效率")
suo_yin_3 = df_1.index("成绩")
suo_yin_4 = df_1.index("产量")
suo_yin_5 = df_1.index("节点")
suo_yin_6 = df_1.index("备注")
# 读取文件内容 usecols=[1, 3, 4] 读取第1,3,4列
df = pd.read_excel(file_name, usecols=[suo_yin_1, suo_yin_2, suo_yin_3, suo_yin_4, suo_yin_5, suo_yin_6], sheet_name='data')
# pf = pd.read_excel('xxx.xls', usecols=[1, 3, 4], sheet_name='data')
# print(pf)
# 追加一列数据,将每个文件的名字追加进该文件的数据中,确定每条数据属于哪个文件
excel_name = file.replace(".xlsx", "") # 提取每个excel文件的名称,去掉.xlsx后缀
df["文件名"] = excel_name # 新建列名为“文件名”,列数据为excel文件名
dfs.append(df) # 将新建文件名列追加进汇总excel中
# 行合并
df_concated = pd.concat(dfs)
# 构造输出目录的绝对路径
out_path = os.path.join(dir, 'res.xlsx')
# 输出到excel表格中,并删除pandas默认的index列
df_concated.to_excel(out_path, sheet_name='Sheet1', index=None)
# 调用并执行函数
to_one_excel(r'E:\py\python3.7\test\test96')
总结
分享:
固守旧我、维持现状的最大好处就是避免改变,这就像陷入一个负能量循环圈,你越害怕去改变,就越不会有动力去改变。
到此这篇关于python按列索引提取文件夹内所有excel指定列汇总的文章就介绍到这了,更多相关python提取excel指定列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python读取excel指定列生成指定sql脚本的方法
需求 最近公司干活,收到一个需求,说是让手动将数据库查出来的信息复制粘贴到excel中,在用excel中写好的公式将指定的两列数据用update这样的语句替换掉. 例如: 有个A库,其中有两个A.01和A.02字段,需要将这两个字段替换到下面的sql语句中, update A set A.01 = 'excel第一列的值' where A.02 = 'excel第二列的值' 虽然excel中公式写好了,但是还需要将总计的那行复制粘贴到txt文档中,所以索性太麻烦,果断用Python写了一个自动化
-
python读取excel指定列数据并写入到新的excel方法
如下所示: #encoding=utf-8 import xlrd from xlwt import * #------------------读数据--------------------------------- fileName="C:\\Users\\st\\Desktop\\test\\20170221131701.xlsx" bk=xlrd.open_workbook(fileName) shxrange=range(bk.nsheets) try: sh=bk.sheet
-

python按列索引提取文件夹内所有excel指定列汇总(示例代码)
目录 前言 一.情景描述 二.python汇总 总结 前言 一.情景描述 情景一:文件夹内有很多excel数据,包含的数据格式一样,我们需要提取每个文件中指定的几列数据汇总到一个文件中(因为是按列索引提取,所以列的顺序可以不一样) 汇总后: 二.python汇总 注意事项: 文件所在文件夹内只能有运行文件.py,和需要汇总的文件,不能有其它文件夹,否则会出现运行错误: 运行第二遍时需要将第一遍运行得到的结果文件res.xlsx删除,否则也会出现运行错误: 代码如下(示例): # -*- codi
-
python判断文件夹内是否存在指定后缀文件的实例
该代码主要是基于python实现判断指定文件夹下是否存在指定后缀的文件.代码如下: import os Your_Dir='你的文件夹/' Files=os.listdir(Your_Dir) for k in range(len(Files)): # 提取文件夹内所有文件的后缀 Files[k]=os.path.splitext(Files[k])[1] Str2=['.wav','.mp3','.mp4'] if len(list(set(Str2).intersection(set(Fil
-
基于linux命令提取文件夹内特定文件路径
最近需要实现自动化搜寻特定文件夹下的特定文件,并且需要分别保存文件路径与文件名.算然使用python的walk能够实现,但是感觉复杂了些.于是想看看linux自带的命令是否能完成这项工作. 环境 需要查找的目录结构如下 . |____test | |____test2.txt | |____test.py | |____test.txt | |____regex.py |____MongoDB | |____.gitignore | |____cnt_fail.py | |____db 目标一:
-
Python提取转移文件夹内所有.jpg文件并查看每一帧的方法
python里面可以将路径里面的\替换成/避免转义. os.walk方法可以将目标路径下文件的root,dirs,files提取出来.后面对每个文件进行操作. 切片操作[:]判断是否为.jpg或.JPG文件. shutil的copy方法将文件从旧路径复制到新路径. glob的glob方法提取目标文件夹的所有图片,对每张图片进行显示保存等操作. 详细代码及注释如下: import os import shutil import glob import cv2 path = 'C:/Users/de
-
python压缩文件夹内所有文件为zip文件的方法
本文实例讲述了python压缩文件夹内所有文件为zip文件的方法.分享给大家供大家参考.具体如下: 用这段代码可以用来打包自己的文件夹为zip,我就用这段代码来备份 import zipfile z = zipfile.ZipFile('my-archive.zip', 'w', zipfile.ZIP_DEFLATED) startdir = "/home/johnf" for dirpath, dirnames, filenames in os.walk(startdir): fo
-
python 实现对文件夹内的文件排序编号
使用时,需更改rootdir, 即文件保存的路径,以及要保存的格式,例如'.jpg' 如果排序前后文件格式一样,建议先随便换个格式,然后再换回来,也就是程序运行两次,第一次随便换个格式,第二次换成想要的格式. #!usr/bin/env python import os import os.path rootdir = "C:\\Users\\IronMan\\Desktop\\launch\\" files = os.listdir(rootdir) b=0 for name in
-
Python 新建文件夹与复制文件夹内所有内容的方法
在指定路径下新建一个文件夹: import os def newfile(path): path=path.strip() path=path.rstrip("\\") # 判断路径是否存在 isExists=os.path.exists(path) # 不存在 if not isExists: # 创建目录操作函数 os.makedirs(path) print(path+' 创建成功') return True #存在 else: print(path+' 目录已存在') retu
-
Python判断一个文件夹内哪些文件是图片的实例
如下所示: def is_img(ext): ext = ext.lower() if ext == '.jpg': return True elif ext == '.png': return True elif ext == '.jpeg': return True elif ext == '.bmp': return True else: return False 调用时 for x in os.listdir(directory): if is_img(osp.splitext(x)[1
-
Python导入父文件夹中模块并读取当前文件夹内的资源
在某些特殊情况下,我们的 Python 脚本需要调用父目录下的其他模块.例如: 在编写 GNE 的测试用例时,有一个脚本 generate_new_cases.py放在 tests文件夹中.而 tests 文件夹与 gne 文件夹放在同一个位置.其中 gne 文件夹是一个包.我现在需要从generate_new_cases.py 文件中导入 gne 里面的一个类GeneralNewsExtractor. 为了简化问题,我单独写了一个演示的样例.它的文件结构与每个文件中的内容如下: 现在,我直接在
-
使用Python 统计文件夹内所有pdf页数的小工具
1.首先安装 PyPDF2 库: pip install PyPDF2 2.然后保存下面文件(已带注释,具体实现请自己思考) import os import PyPDF2 #获取文件夹内所有pdf文件,以及打印文件数量 def GetFileInfo(path, fileType=()): fileList = [] # root 表示当前正在访问的文件夹路径 # dirs 是 list , 表示该文件夹中所有的目录的名字(不包括子目录) # files 是 list , 表示内容是该文件夹中