利用PyTorch实现爬山算法
目录
- 0. 前言
- 1. 使用 PyTorch 实现爬山算法
- 1.1 爬山算法简介
- 1.2 使用爬山算法进行 CartPole 游戏
- 2. 改进爬山算法
0. 前言
在随机搜索策略中,每个回合都是独立的。因此,随机搜索中的所有回合都可以并行运行,最终选择能够得到最佳性能的权重。我们还通过绘制总奖励随回合增加的变化情况进行验证,可以看到奖励并没有上升的趋势。在本节中,我们将实现爬山算法 (hill-climbing algorithm),以将在一个回合中学习到的知识转移到下一个回合中。
1. 使用 PyTorch 实现爬山算法
1.1 爬山算法简介
在爬山算法中,我们同样从随机选择的权重开始。但是,对于每个回合,我们都会为权重添加一些噪声数据。如果总奖励有所改善,我们将使用新的权重来更新原权重;否则,将保持原权重。通过这种方法,随着回合的增加,权重也会逐步修改,而不是在每个回合中随机改变。
1.2 使用爬山算法进行 CartPole 游戏
接下来,我们使用 PyTorch 实现爬山算法。首先,导入所需的包,创建一个 CartPole 环境实例,并计算状态空间和动作空间的尺寸。重用 run_episode 函数,其会根据给定权重,模拟一个回合后返回总奖励:
import gym
import torch
from matplotlib import pyplot as plt
env = gym.make('CartPole-v0')
n_state = env.observation_space.shape[0]
print(n_state)
n_action = env.action_space.n
print(n_action)
def run_episode(env, weight):
state = env.reset()
total_reward = 0
is_done = False
while not is_done:
state = torch.from_numpy(state).float()
action = torch.argmax(torch.matmul(state, weight))
state, reward, is_done, _ = env.step(action.item())
total_reward += reward
return total_reward
模拟 1000 个回合,并初始化变量用于跟踪最佳的总奖励以及相应的权重。同时,初始化一个空列表用于记录每个回合的总奖励:
n_episode = 1000 best_total_reward = 0 best_weight = torch.randn(n_state, n_action) total_rewards = []
正如以上所述,我们在每个回合中为权重添加一些噪音,为了使噪声不会覆盖原权重,我们还将对噪声进行缩放,使用 0.01 作为噪声缩放因子:
noise_scale = 0.01
然后,就可以运行 run_episode 函数进行模拟。
随机选择初始权重之后,在每个回合中执行以下操作:
- 为权重增加随机噪音
- 智能体根据线性映射采取动作
- 回合终止并返回总奖励
- 如果当前奖励大于到目前为止获得的最佳奖励,更新最佳奖励和权重;否则,最佳奖励和权重将保持不变
- 记录每回合的总奖励
for e in range(n_episode):
weight = best_weight + noise_scale * torch.rand(n_state, n_action)
total_reward = run_episode(env, weight)
if total_reward >= best_total_reward:
best_total_reward = total_reward
best_weight = weight
total_rewards.append(total_reward)
print('Episode {}: {}'.format(e + 1, total_reward))
计算使用爬山算法所获得的平均总奖励:
print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))
# Average total reward over 1000 episode: 62.421
2. 改进爬山算法
为了评估使用爬山算法的训练效果,多次重复训练过程,使用循环语句多次执行爬山算法,可以观察到平均总奖励的波动变化较大:
for i in range(10):
best_total_reward = 0
best_weight = torch.randn(n_state, n_action)
total_rewards = []
for e in range(n_episode):
weight = best_weight + noise_scale * torch.rand(n_state, n_action)
total_reward = run_episode(env, weight)
if total_reward >= best_total_reward:
best_total_reward = total_reward
best_weight = weight
total_rewards.append(total_reward)
# print('Episode {}: {}'.format(e + 1, total_reward))
print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))
以下是我们运行10次后得到的结果:
Average total reward over 1000 episode: 200.0
Average total reward over 1000 episode: 9.846
Average total reward over 1000 episode: 82.1
Average total reward over 1000 episode: 9.198
Average total reward over 1000 episode: 9.491
Average total reward over 1000 episode: 9.073
Average total reward over 1000 episode: 149.421
Average total reward over 1000 episode: 49.584
Average total reward over 1000 episode: 8.827
Average total reward over 1000 episode: 9.369
产生如此差异的原因是什么呢?如果初始权重较差,则添加的少量噪声只会小范围改变权重,且对改善性能几乎没有影响,导致算法收敛性能不佳。另一方面,如果初始权重较为合适,则添加大量噪声可能会大幅度改变权重,使得权重偏离最佳权重并破坏算法性能。为了使爬山算法的训练更稳定,我们可以使用自适应噪声缩放因子,类似于梯度下降中的自适应学习率,随着模型性能的提升改变噪声缩放因子的大小。
为了使噪声具有自适应性,执行以下操作:
- 指定初始噪声缩放因子
- 如果回合中的模型性能有所改善,则减小噪声缩放因子,本节中,每次将噪声缩放因子减小为原来的一半,同时设置缩放因子最小值为
0.0001 - 而如果回合中中的模型性能下降,则增大噪声缩放因子,本节中,每次将噪声缩放因子增大为原来的
2倍,同时设置缩放因子最大值为2
noise_scale = 0.01
best_total_reward = 0
best_weight = torch.randn(n_state, n_action)
total_rewards = []
for e in range(n_episode):
weight = best_weight + noise_scale * torch.rand(n_state, n_action)
total_reward = run_episode(env, weight)
if total_reward >= best_total_reward:
best_total_reward = total_reward
best_weight = weight
noise_scale = max(noise_scale/2, 1e-4)
else:
noise_scale = min(noise_scale*2, 2)
total_rewards.append(total_reward)
print('Episode {}: {}'.format(e + 1, total_reward))
可以看到,奖励随着回合的增加而增加。训练过程中,当一个回合中可以运行 200 个步骤时,模型的性能可以得到保持,平均总奖励也得到了极大的提升:
print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))
# Average total reward over 1000 episode: 196.28
接下来,为了更加直观的观察,我们绘制每个回合的总奖励的变化情况,如下所示,可以看到总奖励有明显的上升趋势,然后稳定在最大值处:
plt.plot(total_rewards, label='search')
plt.xlabel('episode')
plt.ylabel('total_reward')
plt.legend()
plt.show()
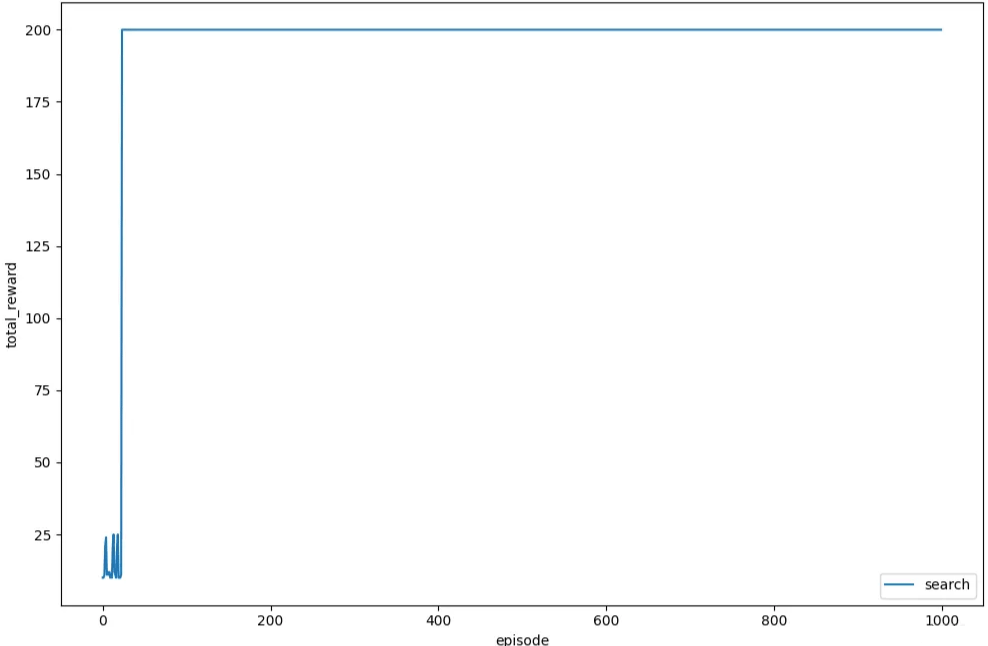
多次运行训练过程过程,可以发现与采用恒定噪声缩放因子进行学习相比,自适应噪声缩放因子可以得到稳定的训练结果。
接下来,我们测试所得到的模型策略在 1000 个新回合中的性能表现:
n_episode_eval = 1000
total_rewards_eval = []
for episode in range(n_episode_eval):
total_reward = run_episode(env, best_weight)
print('Episode {}: {}'.format(episode+1, total_reward))
total_rewards_eval.append(total_reward)
print('Average total reward over {} episode: {}'.format(n_episode_eval, sum(total_rewards_eval)/n_episode_eval))
# Average total reward over 1000 episode: 199.98
可以看到在测试阶段的平均总奖励接近 200,即 CartPole 环境中可以获得的最高奖励。通过多次运行评估,可以获得非常一致的结果。
到此这篇关于利用PyTorch实现爬山算法的文章就介绍到这了,更多相关PyTorch爬山算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

PyTorch策略梯度算法详情
目录 0. 前言 1. 策略梯度算法 2. 使用策略梯度算法解决CartPole问题 0. 前言 本节中,我们使用策略梯度算法解决 CartPole 问题.虽然在这个简单问题中,使用随机搜索策略和爬山算法就足够了.但是,我们可以使用这个简单问题来更专注的学习策略梯度算法,并在之后的学习中使用此算法解决更加复杂的问题. 1. 策略梯度算法 策略梯度算法通过记录回合中的所有时间步并基于回合结束时与这些时间步相关联的奖励来更新权重训练智能体.使智能体遍历整个回合然后基于获得的奖励更新策略的技术称为蒙特
-
PyTorch实现FedProx联邦学习算法
目录 I. 前言 III. FedProx 1. 模型定义 2. 服务器端 3. 客户端更新 IV. 完整代码 I. 前言 FedProx的原理请见:FedAvg联邦学习FedProx异质网络优化实验总结 联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的. 数据集为某城市十个地区的风电功率,我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型. III. FedProx 算法伪代码: 1. 模型定义 客户端的模
-
pytorch 液态算法实现瘦脸效果
论文:Interactive Image Warping(1993年Andreas Gustafsson) 算法思路: 假设当前点为(x,y),手动指定变形区域的中心点为C(cx,cy),变形区域半径为r,手动调整变形终点(从中心点到某个位置M)为M(mx,my),变形程度为strength,当前点对应变形后的目标位置为U.变形规律如下, 圆内所有像素均沿着变形向量的方向发生偏移 距离圆心越近,变形程度越大 距离圆周越近,变形程度越小,当像素点位于圆周时,该像素不变形 圆外像素不发生偏移 其中,
-
利用Pytorch实现简单的线性回归算法
最近听了张江老师的深度学习课程,用Pytorch实现神经网络预测,之前做Titanic生存率预测的时候稍微了解过Tensorflow,听说Tensorflow能做的Pyorch都可以做,而且更方便快捷,自己尝试了一下代码的逻辑确实比较简单. Pytorch涉及的基本数据类型是tensor(张量)和Autograd(自动微分变量),对于这些概念我也是一知半解,tensor和向量,矩阵等概念都有交叉的部分,下次有时间好好补一下数学的基础知识,不过现阶段的任务主要是应用,学习掌握思维和方法即可,就不再
-
PyTorch实现联邦学习的基本算法FedAvg
目录 I. 前言 II. 数据介绍 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 IV. 代码实现 1. 初始化 2. 服务器端 3. 客户端 4. 测试 V. 实验及结果 VI. 源码及数据 I. 前言 在之前的一篇博客联邦学习基本算法FedAvg的代码实现中利用numpy手搭神经网络实现了FedAvg,手搭的神经网络效果已经很好了,不过这还是属于自己造轮子,建议优先使用PyTorch来实现. II. 数据介绍 联邦学习中存在多个客户端,每个客户端都有自己的数据集
-
Python强化练习之PyTorch opp算法实现月球登陆器
目录 概述 强化学习算法种类 PPO 算法 Actor-Critic 算法 Gym LunarLander-v2 启动登陆器 PPO 算法实现月球登录器 PPO main 输出结果 概述 从今天开始我们会开启一个新的篇章, 带领大家来一起学习 (卷进) 强化学习 (Reinforcement Learning). 强化学习基于环境, 分析数据采取行动, 从而最大化未来收益. 强化学习算法种类 On-policy vs Off-policy: On-policy: 训练数据由当前 agent 不断
-
pytorch 膨胀算法实现大眼效果
目录 算法思路: 应用场景: 代码实现: 实验效果: 论文:Interactive Image Warping(1993年Andreas Gustafsson) 算法思路: 以眼睛中心为中心点,对眼睛区域向外放大,就实现了大眼的效果.大眼的基本公式如下, 假设眼睛中心点为O(x,y),大眼区域半径为Radius,当前点位为A(x1,y1),对其进行改进,加入大眼程度控制变量Intensity,其中Intensity的取值范围为0-100. 其中,dis表示AO的欧式距离,k表示缩放比例因子,
-
利用PyTorch实现爬山算法
目录 0. 前言 1. 使用 PyTorch 实现爬山算法 1.1 爬山算法简介 1.2 使用爬山算法进行 CartPole 游戏 2. 改进爬山算法 0. 前言 在随机搜索策略中,每个回合都是独立的.因此,随机搜索中的所有回合都可以并行运行,最终选择能够得到最佳性能的权重.我们还通过绘制总奖励随回合增加的变化情况进行验证,可以看到奖励并没有上升的趋势.在本节中,我们将实现爬山算法 (hill-climbing algorithm),以将在一个回合中学习到的知识转移到下一个回合中. 1. 使用
-
Python实现随机爬山算法
随机爬山是一种优化算法.它利用随机性作为搜索过程的一部分.这使得该算法适用于非线性目标函数,而其他局部搜索算法不能很好地运行.它也是一种局部搜索算法,这意味着它修改了单个解决方案并搜索搜索空间的相对局部区域,直到找到局部最优值为止.这意味着它适用于单峰优化问题或在应用全局优化算法后使用. 在本教程中,您将发现用于函数优化的爬山优化算法完成本教程后,您将知道: 爬山是用于功能优化的随机局部搜索算法. 如何在Python中从头开始实现爬山算法. 如何应用爬山算法并检查算法结果. 教程概述 本教程分为
-
爬山算法简介和Python实现实例
一.爬山法简介 爬山法(climbing method)是一种优化算法,其一般从一个随机的解开始,然后逐步找到一个最优解(局部最优). 假定所求问题有多个参数,我们在通过爬山法逐步获得最优解的过程中可以依次分别将某个参数的值增加或者减少一个单位.例如某个问题的解需要使用3个整数类型的参数x1.x2.x3,开始时将这三个参数设值为(2,2,-2),将x1增加/减少1,得到两个解(1,2,-2), (3, 2,-2):将x2增加/减少1,得到两个解(2,3, -2),(2,1, -2):将x3增加/
-
Python利用正则表达式实现计算器算法思路解析
(1)不使用eval()等系统自带的计算方法 (2)实现四则混合运算.括号优先级解析 思路: 1.字符串预处理,将所有空格去除 2.判断是否存在括号运算,若存在进行第3步,若不存在则直接进入第4步 3.利用正则表达式获取最底层括号内的四则运算表达式 4.将四则运算表达式进行预处理:表达式开头有负数时,在表达式前加上一个0 5.利用re.split().re.findall()方法,通过加减符号,对四则运算进行拆分为乘除运算式和数字,并保留对应的位置下标. 6.利用re.split().re.fi
-
python实现爬山算法的思路详解
问题 找图中函数在区间[5,8]的最大值 重点思路 爬山算法会收敛到局部最优,解决办法是初始值在定义域上随机取乱数100次,总不可能100次都那么倒霉. 实现 import numpy as np import matplotlib.pyplot as plt import math # 搜索步长 DELTA = 0.01 # 定义域x从5到8闭区间 BOUND = [5,8] # 随机取乱数100次 GENERATION = 100 def F(x): return math.sin(x*x)
-
利用python实现PSO算法优化二元函数
python实现PSO算法优化二元函数,具体代码如下所示: import numpy as np import random import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D #----------------------PSO参数设置--------------------------------- class PSO(): def __init__(self,pN,dim,max_iter): #初
-
利用pytorch实现对CIFAR-10数据集的分类
步骤如下: 1.使用torchvision加载并预处理CIFAR-10数据集. 2.定义网络 3.定义损失函数和优化器 4.训练网络并更新网络参数 5.测试网络 运行环境: windows+python3.6.3+pycharm+pytorch0.3.0 import torchvision as tv import torchvision.transforms as transforms import torch as t from torchvision.transforms import
-
利用PyTorch实现VGG16教程
我就废话不多说了,大家还是直接看代码吧~ import torch import torch.nn as nn import torch.nn.functional as F class VGG16(nn.Module): def __init__(self): super(VGG16, self).__init__() # 3 * 224 * 224 self.conv1_1 = nn.Conv2d(3, 64, 3) # 64 * 222 * 222 self.conv1_2 = nn.Co