Go http请求排队处理实战示例
目录
- 一、http请求的顺序处理方式
- 二、http请求的异步处理方式--排队处理
- 工作单元
- 队列
- 消费者协程
- 完整代码
- 总结
一、http请求的顺序处理方式
在高并发场景下,为了降低系统压力,都会使用一种让请求排队处理的机制。本文就介绍在Go中是如何实现的。
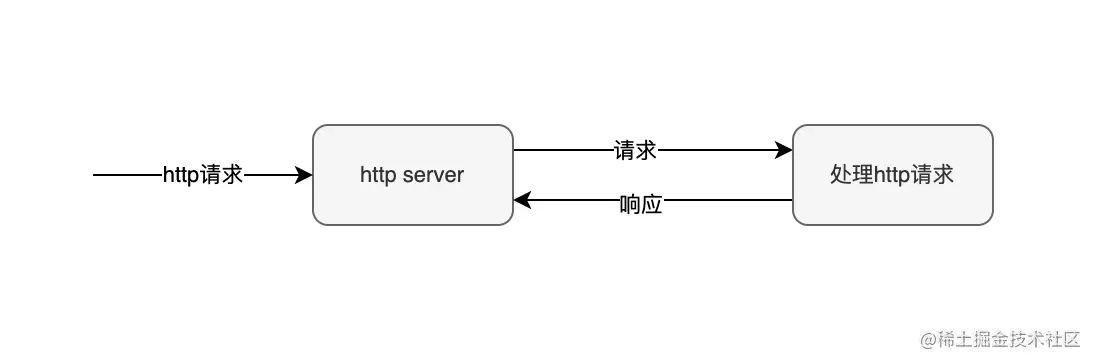
首先,我们看下正常的请求处理逻辑。 客户端发送请求,web server接收请求,然后就是处理请求,最后响应给客户端这样一个顺序的逻辑。如下图所示:
代码实现如下:
package main
import (
"fmt"
"net/http"
)
func main() {
myHandler := MyHandler{}
http.Handle("/", &myHandler)
http.ListenAndServe(":8080", nil)
}
type MyHandler struct {
}
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello Go"))
}
在浏览器中输入 http://localhost:8080/,就能在页面上显示出“Hello Go”的页面来。
通常情况下,大家在开发web系统的时候,一般都是这么处理请求。接下来我们看在高并发下如何实现让请求进行排队处理。
二、http请求的异步处理方式--排队处理
让http请求进入到队列,我们也称为异步处理方式。其基本思想就是将接收到的请求的上下文(即request和response)以及处理逻辑包装成一个工作单元,然后将其放到队列,然后该工作单元等待消费的工作线程处理该job,处理完成后再返回给客户端。 流程如下图:
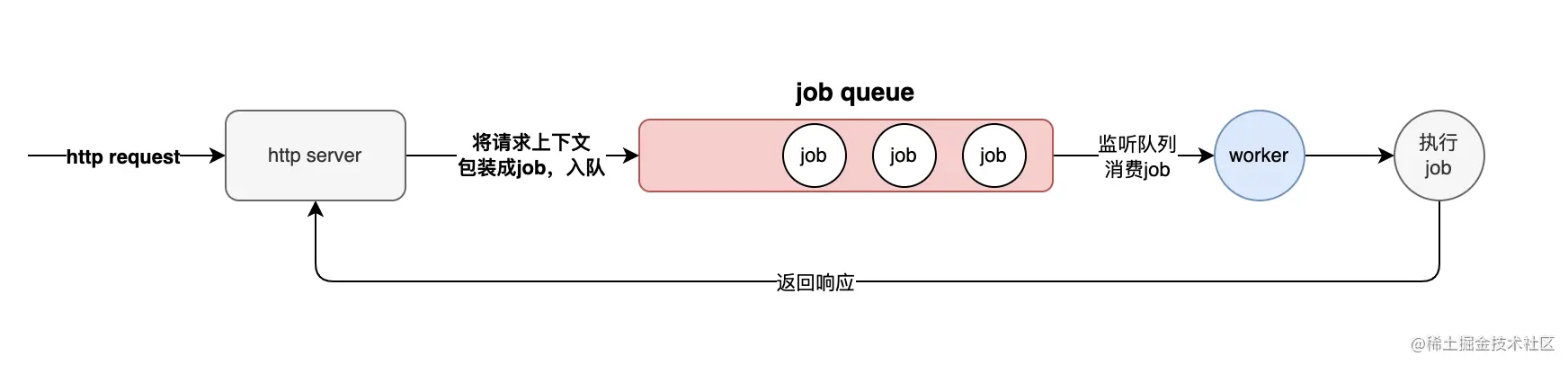
该实现中会有三个关键的元素:工作执行单元、队列、消费者。下面我们逐一看下各自的职责及实现。
工作单元
该工作单元主要是封装请求的上下文信息(request和response)、请求的处理逻辑以及该工作单元是否被执行完成的状态。
请求的处理逻辑实际上就是原来在顺序处理流程中的具体函数,如果是mvc模式的话就是controller里的一个具体的action。
在Go中实现通信的方式一般是使用通道。所以,在工作单元中有一个通道,当该工作单元执行完具体的处理逻辑后,就往该通道中写入一个消息,以通知主协程该次请求已完成,可以返回给客户端了。
所以,一个http请求的处理逻辑看起来就像是下面这样:
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
将w和r包装成工作单元job
将job入队
等待job执行完成
本次请求处理完毕
}
下面我们看下工作单元的具体实现,这里我们将其定义为一个Job结构体:
type Job struct {
DoneChan chan struct{}
handleJob func(j FlowJob) error //具体的处理逻辑
}
Job结构体中有一个handleJob,其类型是一个函数,即处理请求的逻辑部分。DoneChan通道用来让该单元进行阻塞等待,并当handleJob执行完毕后发送消息通知的。
下面我们再看看该Job的相关行为:
// 消费者从队列中取出该job时 执行具体的处理逻辑
func (job *Job) Execute() error {
fmt.Println("job start to execute ")
return job.handleJob(job)
}
// 执行完Execute后,调用该函数以通知主线程中等待的job
func (job *Job) Done() {
job.DoneChan <- struct{}{}
close(job.DoneChan)
}
// 工作单元等待自己被消费
func (job *Job) WaitDone() {
select {
case <-job.DoneChan:
return
}
}
队列
队列主要是用来存储工作单元的。是处理请求的主协程和消费协程之间的纽带。队列具有列表、容量、当前元素个数等关键元素组成。如下:
type JobQueue struct {
mu sync.Mutex
noticeChan chan struct{}
queue *list.List
size int
capacity int
}
其行为主要有入队、出队、移除等操作。定义如下:
// 初始化队列
func NewJobQueue(cap int) *JobQueue {
return &JobQueue{
capacity: cap,
queue: list.New(),
noticeChan: make(chan struct{}, 1),
}
}
// 工作单元入队
func (q *JobQueue) PushJob(job *Job) {
q.mu.Lock()
defer q.mu.Unlock()
q.size++
if q.size > q.capacity {
q.RemoveLeastJob()
}
q.queue.PushBack(job)
q.noticeChan <- struct{}{}
}
// 工作单元出队
func (q *JobQueue) PopJob() *Job {
q.mu.Lock()
defer q.mu.Unlock()
if q.size == 0 {
return nil
}
q.size--
return q.queue.Remove(q.queue.Front()).(*Job)
}
// 移除队列中的最后一个元素。
// 一般在容量满时,有新job加入时,会移除等待最久的一个job
func (q *JobQueue) RemoveLeastJob() {
if q.queue.Len() != 0 {
back := q.queue.Back()
abandonJob := back.Value.(*Job)
abandonJob.Done()
q.queue.Remove(back)
}
}
// 消费线程监听队列的该通道,查看是否有新的job需要消费
func (q *JobQueue) waitJob() <-chan struct{} {
return q.noticeChan
}
这里我们主要解释一下入队的操作流程:
- 1 首先是队列的元素个数size++
- 2 判断size是否超过最大容量capacity
- 3 若超过最大容量,则将队列中最后一个元素移除。因为该元素等待时间最长,认为是超时的情况。
- 4 将新接收的工作单元放入到队尾。
- 5 往noticeChan通道中写入一个消息,以便通知消费协程处理Job。
由以上可知,noticeChan是队列和消费者协程之间的纽带。下面我们来看看消费者的实现。
消费者协程
消费者协程的职责是监听队列,并从队列中获取工作单元,执行工作单元的具体处理逻辑。在实际应用中,可以根据系统的承载能力启用多个消费协程。在本文中,为了方便讲解,我们只启用一个消费协程。
我们定义一个WorkerManager结构体,负责管理具体的消费协程。该WorkerManager有一个属性是工作队列,所有启动的消费协程都需要从该工作队列中获取工作单元。代码实现如下:
type WorkerManager struct {
jobQueue *JobQueue
}
func NewWorkerManager(jobQueue *JobQueue) *WorkerManager {
return &WorkerManager{
jobQueue: jobQueue,
}
}
func (m *WorkerManager) createWorker() error {
go func() {
fmt.Println("start the worker success")
var job FlowJob
for {
select {
case <-m.jobQueue.waitJob():
fmt.Println("get a job from job queue")
job = m.jobQueue.PopJob()
fmt.Println("start to execute job")
job.Execute()
fmt.Print("execute job done")
job.Done()
}
}
}()
return nil
}
在代码中我们可以看到,createWorker中的逻辑实际是一个for循环,然后通过select监听队列的noticeChan通道,当获取到工作单元时,就执行工作单元中的handleJob方法。执行完后,通过job.Done()方法通知在主协程中还等待的job。这样整个流程就形成了闭环。
完整代码
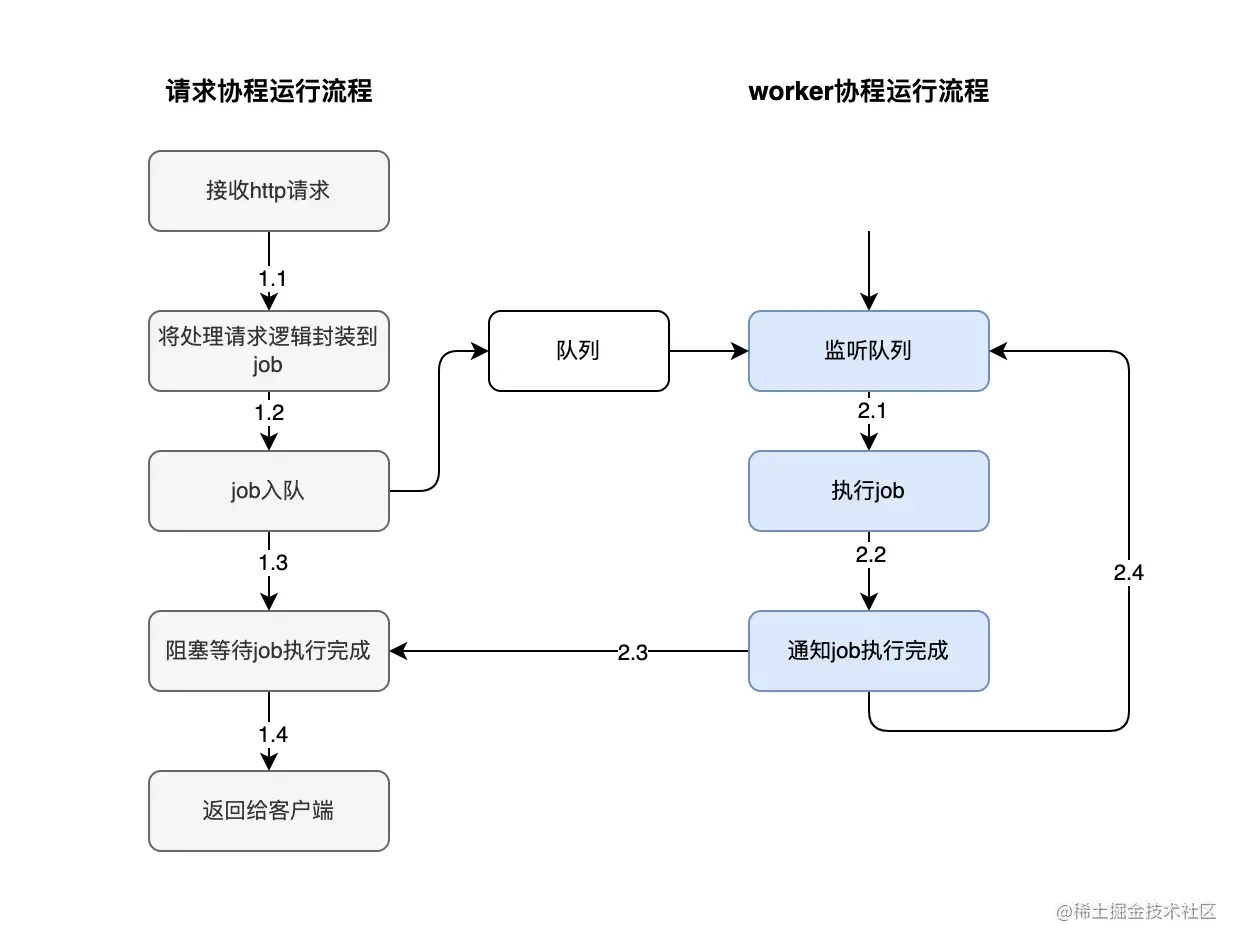
我们现在看下整体的处理流程,如下图:
现在我们写一个测试demo。在这里我们定义了一个全局的flowControl结构体,以作为队列和工作协程的管理。代码如下:
package main
import (
"container/list"
"fmt"
"net/http"
"sync"
)
func main() {
flowControl := NewFlowControl()
myHandler := MyHandler{
flowControl: flowControl,
}
http.Handle("/", &myHandler)
http.ListenAndServe(":8080", nil)
}
type MyHandler struct {
flowControl *FlowControl
}
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Println("recieve http request")
job := &Job{
DoneChan: make(chan struct{}, 1),
handleJob: func(job *Job) error {
w.Header().Set("Content-Type", "application/json")
w.Write([]byte("Hello World"))
return nil
},
}
h.flowControl.CommitJob(job)
fmt.Println("commit job to job queue success")
job.WaitDone()
}
type FlowControl struct {
jobQueue *JobQueue
wm *WorkerManager
}
func NewFlowControl() *FlowControl {
jobQueue := NewJobQueue(10)
fmt.Println("init job queue success")
m := NewWorkerManager(jobQueue)
m.createWorker()
fmt.Println("init worker success")
control := &FlowControl{
jobQueue: jobQueue,
wm: m,
}
fmt.Println("init flowcontrol success")
return control
}
func (c *FlowControl) CommitJob(job *Job) {
c.jobQueue.PushJob(job)
fmt.Println("commit job success")
}
之前有一篇文章是优先级队列,实际上就是该队列的高级实现版本,可以将不同的请求按优先级分配到不同的队列中。有兴趣的同学可参考:Go实战 单队列到优先级队列的实现
总结
通过将请求的上下文信息封装到一个工作单元中,并将其放入到队列中,然后通过消息通道的方式阻塞等待消费者执行完毕。同时在队列中通过设置队列的容量以解决请求过多而给系统造成压力的问题。
以上就是Go http请求排队处理实战的详细内容,更多关于Go http请求排队的资料请关注我们其它相关文章!
相关推荐
-
golang高性能的http请求 fasthttp详解
fasthttp是golang下的一个http框架,顾名思义,与原生的http实现相比,它的特点在于快,按照官网的说法,它的客户端和服务端性能比原生有了十倍的提升. 它的高性能主要源自于"复用",通过服务协程和内存变量的复用,节省了大量资源分配的成本. fasthttp 据说是目前golang性能最好的http库,相对于自带的net/http,性能说是有10倍的提升,具体介绍可以看看官方介绍:valyala/fasthttp 1,首先安装fasthttp go get -u githu
-

解决Goland中利用HTTPClient发送请求超时返回EOF错误DEBUG
今天解决了一个疑难杂症,起因是之前代理某内部API接口,请求先是出现卡顿,超时后报EOF错误. 但奇怪的是线上测试环境确是没问题的. Google了一下,有人说可能是由于重复请求次数过多导致,应该设置req.Close属性为true,这样不会反复利用一次连接. 尝试该操作后依然无法解决问题,遂求助同事璟文. 经过大牛的一番调查后,发现时TCP超时,连接断了.至于原因,是由于Goland设置了代理...Orz 不过经历这次事件我也学到了利用MAC自带的活动监视器,来查看网络行为,璟文是看到了接口的
-
Go类型安全的HTTP请求示例详解
目录 前言 Go 原生写法 httpc 实现 更多能力 前言 对 Gopher 来说,虽然我们基本都是在写代码让别人来请求,但是有时候,我们也需要去请求第三方提供的 RESTful 接口,这个时候,我们才能感受到前端同学拼接 HTTP 请求参数的痛苦. 比如,我们要发起类似这样一个请求,看起来很简单,实际写起来还是比较繁琐的. POST /articles/5/update?device=ios HTTP/1.1 Host: go-zero.dev Authorization: Bearer <
-
详解golang开发中http请求redirect的问题
这两天在开发项目的时候遇到了一个问题,请求了一个URL,它会302到另一个地址,本意上只是想检查这个URL是否会做3XX的redirect跳转,结果每次reqeust都会返回最后一跳的结果.后来就看了下源码,了解下请求跳转的机制 实现代码 看下实现的简单代码 func main() { client := &http.Client{} url := "http://www.qq.com" reqest, err := http.NewRequest("GET"
-
golang http请求封装代码
在GOPATH 中创建 utils 文件夹 放置这两个文件 http.go package utils import ( "crypto/tls" "encoding/json" "errors" "fmt" "io/ioutil" "net/http" "net/url" "strings" "sync" ) var ( GE
-
Golang请求fasthttp实践
目录 基础API演示 高性能API演示 测试服务 Golang单元测试 测试报告 原计划学完Golang语言HTTP客户端实践之后,就可以继续了,没想到才疏学浅,在搜资料的时候发现除了Golang SDK自带的net/http,还有一个更牛的HttpClient实现github.com/valyala/fasthttp,据说性能是net/http的10倍,我想可能是有点夸张了,后期我会进行测试,以正视听. 在github.com/valyala/fasthttp用到了对象池,为了在高性能测试中减
-
Go http请求排队处理实战示例
目录 一.http请求的顺序处理方式 二.http请求的异步处理方式--排队处理 工作单元 队列 消费者协程 完整代码 总结 一.http请求的顺序处理方式 在高并发场景下,为了降低系统压力,都会使用一种让请求排队处理的机制.本文就介绍在Go中是如何实现的. 首先,我们看下正常的请求处理逻辑. 客户端发送请求,web server接收请求,然后就是处理请求,最后响应给客户端这样一个顺序的逻辑.如下图所示: 代码实现如下: package main import ( "fmt" &quo
-
Redis 抽奖大转盘的实战示例
目录 1. 项目介绍 2. 项目演示 3. 表结构 4. 项目搭建 4.1 依赖 4.2 YML配置 4.3 代码生成 4.4 Redis 配置 4.5 常量管理 4.6 业务代码 4.7 总结 5. 项目地址 1. 项目介绍 这是一个基于Spring boot + Mybatis Plus + Redis 的简单案例. 主要是将活动内容.奖品信息.记录信息等缓存到Redis中,然后所有的抽奖过程全部从Redis中做数据的操作. 大致内容很简单,具体操作下面慢慢分析. 2. 项目演示 话不多说,
-
Spring WebClient实战示例
目录 WebClient实战 服务端性能对比 Spring WebFlux Spring MVC 客户端性能比较 webclient resttemplate(不带连接池) resttemplate(带连接池) webclient连接池 webclient 的HTTP API 小结 WebClient实战 本文代码地址:https://github.com/bigbirditedu/webclient Spring Webflux 是 Spring Framework 5.0 的新特性,是随着当
-
SpringBoot Security从入门到实战示例教程
目录 前言 入门 测试接口 增加依赖 自定义配置 配置密码加密方式 配置AuthenticationManagerBuilder 认证用户.角色权限 配置HttpSecurity Url访问权限 自定义successHandler 自定义failureHandler 自定义未认证处理 自定义权限不足处理 自定义注销登录 前后端分离场景 提供登录接口 自定义认证过滤器 鉴权 1.注解鉴权 2.自定义Bean动态鉴权 3.扩展默认方法自定义扩展根对象SecurityExpressionRoot 登出
-
node强缓存和协商缓存实战示例
目录 前言 什么是浏览器缓存 优点 强缓存 Expires Cache-Control 协商缓存 ETag.If-None-Match node实践 koa启动服务 创建项目 koa代码 原生koa实现简易静态资源服务 强缓存验证 设置Expire 协商缓存验证 小结 总结 前言 浏览器缓存是性能优化非常重要的一个方案,合理地使用缓存可以提高用户体验,还能节省服务器的开销.掌握好缓存的原理和并合理地使用无论对前端还是运维都是相当重要的. 什么是浏览器缓存 浏览器缓存(http 缓存) 是指浏览器
-
Dapr+NestJs编写Pub及Sub装饰器实战示例
目录 系列 Dapr JavaScript SDK 安装 结构 实战 Demo 源码 准备环境和项目结构 注入 Dapr 赖项 配置 Dapr 组件(rabbitMQ) API/Gateway 服务 内部监听微服务 @DaprPubSubscribe 装饰器 运行应用程序 Dapr 是一个可移植的.事件驱动的运行时,它使任何开发人员能够轻松构建出弹性的.无状态和有状态的应用程序,并可运行在云平台或边缘计算中,它同时也支持多种编程语言和开发框架.Dapr 确保开发人员专注于编写业务逻辑,不必分神解
-
Redhat持久化日志实战示例详解
目录 持久化日志 实战练习:收集信息 持久化日志 默认情况下,Red Hat Enterprise Linux 7将系统日志存储在/run/log/journal中,该日志存储在tmpfs(临时文件系统)上.这意味着在重新启动时,所有存储的信息都将丢失.如果目录/var/log/journal存在,日志将存储在那里,从而在重新引导后启用持久日志. 可以通过使用以下步骤来启用持久性日志: mkdir/var/log/journal chown root:systemd-journal /var/l
-
Vue ELement Table技巧表格业务需求实战示例
目录 前言 常见业务 需求:合并行 思路分析 需求合并列 思路分析 前言 在我们日常开发中,表格业务基本是必不可少的,对于老手来说确实简单,家常便饭罢了,但是对于新手小白如何最快上手搞定需求呢?本文从思路开始着手,帮你快速搞定表格. 常见业务 需求:合并行 1. 合并条码一样的两行 2. 触摸高亮关闭,表格颜色重一点 思路分析 调取element Table的回调 通过给table传入span-method方法可以实现合并行或列,方法的参数是一个对象,里面包含当前行row.当前列column.当
-
goroutine 泄漏和避免泄漏实战示例
目录 goroutine 泄漏和避免泄漏的最佳实践 什么是goroutine泄漏? 原因分析 伪代码 有什么方法可以解决这个问题? goroutine 泄漏和避免泄漏的最佳实践 Go的奇妙之处在于,我们可以使用goroutines和channel轻松地执行并发任务.如果在生产环境中使用goroutines和channel,但是不了解它们的行为方式,会造成一些严重的影响. 好吧,我们就面临着这样的影响,我们在goroutines中出现了泄漏,导致应用服务器随着时间的推移而膨胀,消耗了大量的CPU和
-
javascript请求servlet实现ajax示例(分享)
ajax请求是一种无刷新式的用户体验,可以发送GET和POST两种异步请求,现记录如下: GET请求: function sendRequestByGet(){ //定义异步请求对象 var xmlReq; //检测浏览器是否直接支持ajax if(window.XMLHttpRequest){//直接支持ajax xmlReq=new XMLHttpRequest(); }else{//不直接支持ajax xmlReq=new ActiveObject('Microsoft.XMLHTTP')