Java实现堆排序和图解
目录
- 堆排序基本介绍
- 堆排序基本思想
- 堆排序图解
- 步骤一
- 步骤二
- 代码实现
- 总结
堆排序基本介绍
1、堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。
2、堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系。
3、每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
4、大顶堆举例说明

大顶堆特点:arr[i] >= arr[2*i+1] && arr[i] >= arr[2*i+2] // i 对应第几个节点,i从0开始编号
5、小顶堆举例说明

小顶堆:arr[i] <= arr[2*i+1] && arr[i] <= arr[2*i+2] // i 对应第几个节点,i从0开始编号
6、一般升序采用大顶堆,降序采用小顶堆
堆排序基本思想
1、将待排序序列构造成一个大顶堆
2、此时,整个序列的最大值就是堆顶的根节点。
3、将其与末尾元素进行交换,此时末尾就为最大值。
4、然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
可以看到在构建大顶堆的过程中,元素的个数逐渐减少,最后就得到一个有序序列了.
堆排序图解
步骤一
构造初始堆。将给定无序序列构造成一个大顶堆
1、假设给定无序序列结构如下
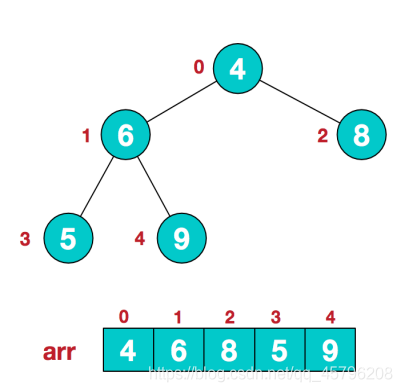
2、此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。

3、找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换

4、这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。

此时,我们就将一个无序序列构造成了一个大顶堆。
步骤二
将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
1、将堆顶元素9和末尾元素4进行交换

2、重新调整结构,使其继续满足堆定义

3、再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.

4、后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序

代码实现
public static void headSort(int[] arr){
//构建初始堆,将给定无序序列构造成一个大顶堆
for (int i = arr.length / 2 - 1; i >= 0; i--) {
adjust(arr,i,arr.length);
}
//将堆顶元素与末尾元素进行交换,使末尾元素最大,然后继续调整堆
for (int i = arr.length - 1; i > 0; i--) {
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
adjust(arr,0,i);
}
}
/**
*
* @param arr 待排序数组
* @param i 最后一个非叶子节点
* @param length
*/
public static void adjust(int[] arr,int i,int length){
int temp = arr[i];
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if((k + 1) < length && arr[k] < arr[k + 1])
k++;
if(arr[k] > temp){
arr[i] = arr[k];
i = k;
}else
break;
}
arr[i] = temp;
}
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Java 堆排序实例(大顶堆、小顶堆)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法.堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点. 堆排序的平均时间复杂度为Ο(nlogn) . 算法步骤: 1. 创建一个堆H[0..n-1] 2. 把堆首(最大值)和堆尾互换 3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置 4. 重复步骤2,直到堆的尺寸为1 堆: 堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
-
JAVA堆排序算法的讲解
预备知识 堆排序 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序.首先简单了解下堆结构. 堆 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如下图: 同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子 该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是: 大顶
-
java堆排序原理与实现方法分析
本文实例讲述了java堆排序原理与实现方法.分享给大家供大家参考,具体如下: 堆是一个数组,被看成一个近似完全二叉树. 举例说明: 堆的性质: 1.已知元素在数组中的序号为i 其父节点的序号为 i/2的整数 其左孩子节点的序号为2*i 其右孩子节点的序号为2*i+1 2.堆分为最大堆和最小堆 在最大堆中,要保证父节点的值大于等于其孩子节点的值 在最小堆中,要保证父节点的值小于等于其孩子节点的值 java实现堆排序 public class MyHeapSort { public void Hea
-
Java实现堆排序(大根堆)的示例代码
堆排序是一种树形选择排序方法,它的特点是:在排序的过程中,将array[0,...,n-1]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子结点之间的内在关系,在当前无序区中选择关键字最大(最小)的元素. 1. 若array[0,...,n-1]表示一颗完全二叉树的顺序存储模式,则双亲节点指针和孩子结点指针之间的内在关系如下: 任意一节点指针 i:父节点:i==0 ? null : (i-1)/2 左孩子:2*i + 1 右孩子:2*i + 2 2. 堆的定义:n个关键字序列a
-
java堆排序概念原理介绍
堆排序介绍: 堆排序可以分为两个阶段.在堆的构造阶段,我们将原始数组重新组织安排进一个堆中:然后在下沉排序阶段,我们从堆中按顺序取出所有元素并得到排序结果. 1.堆的构造,一个有效的方法是从右到左使用sink()下沉函数构造子堆.数组的每个位置都有一个子堆的根节点,sink()对于这些子堆也适用,如果一个节点的两个子节点都已经是堆了,那么在该节点上调用sink()方法可以把他们合并成一个堆.我们可以跳过大小为1的子堆,因为大小为1的不需要sink()也就是下沉操作,有关下沉和上浮操作可以参考我写
-
Java实现堆排序和图解
目录 堆排序基本介绍 堆排序基本思想 堆排序图解 步骤一 步骤二 代码实现 总结 堆排序基本介绍 1.堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序. 2.堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系. 3.每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆 4.大顶堆举例说明 大顶堆特点:arr[i]
-
IntelliJ IDEA 中使用jRebel进行 Java 热部署教程图解
jrebel JRebel是一套JavaEE开发工具.JRebel允许开发团队在有限的时间内完成更多的任务修正更多的问题,发布更高质量的软件产品. JRebel是收费软件,用户可以在JRebel官方站点下载30天的评估版本. Jrebel 可快速实现热部署,节省了大量重启时间,提高了个人开发效率. Rebel是一款JAVA虚拟机插件,它使得JAVA程序员能在不进行重部署的情况下,即时看到代码的改变对一个应用程序带来的影响.JRebel使你能即时分别看到代码.类和资源的变化,你可以一个个地上传而不
-
JAVA内存溢出解决方案图解
这篇文章主要介绍了JAVA内存溢出解决方案图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.在apache-tomcat-7.0.70\bin\catalina.bat(Linux 系统则在catalina.sh) 文件下的 echo Using CATALINA_BASE: "%CATALINA_BASE%" 上面插入以下代码 set JAVA_OPTS=%JAVA_OPTS% -server -XX:PermSize=256
-
java实现堆排序以及时间复杂度的分析
完全二叉树:从上到下,从左到右,每层的节点都是满的,最下边一层所有的节点都是连续集中在最左边. 二叉树的特点就是左子节点是父节点索引值的2倍加一,右子节点是父节点索引值的2倍加二 堆分为两种:大顶堆和小顶堆 大顶堆:在完全二叉树基础上,每个节点的值都大于或等于其左右子节点的值 小顶堆:在完全二叉树基础上,每个节点的值都大于或等于其左右子节点的值 堆排序就是根据先构建好的大顶堆或小顶堆进行排序的. 怎么构建大顶堆: 假如一个数组是:int[] arr
-
Java数据结构最清晰图解二叉树前 中 后序遍历
目录 一,前言 二,树 ①概念 ②树的基础概念 三,二叉树 ①概念 ②两种特殊的二叉树 ③二叉树的性质 四,二叉树遍历 ①二叉树的遍历 ②前序遍历 ③中序遍历 ④后序遍历 五,完整代码 一,前言 二叉树是数据结构中重要的一部分,它的前中后序遍历始终贯穿我们学习二叉树的过程,所以掌握二叉树三种遍历是十分重要的.本篇主要是图解+代码Debug分析,概念的部分讲非常少,重中之重是图解和代码Debug分析,我可以保证你看完此篇博客对于二叉树的前中后序遍历有一个新的认识!!废话不多说,让我们学起来吧!!
-
Java实现堆排序(Heapsort)实例代码
复制代码 代码如下: import java.util.Arrays; public class HeapSort { public static void heapSort(DataWraper[] data){ System.out.println("开始排序"); int arrayLength=data.length; //循环建堆 for(int i=0;i<arrayLength-1;i++){
-
java教程之java程序编译运行图解(java程序运行)
首先我们在桌面,开始->运行->键入cmd 回车,进入windows命令行.进入如图所示的画面: 可知,当前默认目录为C盘Users文件夹下的Administrator文件夹.一般而言,我们习惯改变当前目录.由于windows有磁盘分区,若要跳到其他磁盘,例如E盘,有几种方法: 1.输入命令: pushd 路径(此命令可将当前目录设为所希望的任一个已存在的路径) 2.输入命令: e: 转移到e盘,然后再输入 cd 转移到所希望的已知路径. 如图: 希望在windows命令行下使用javac.
-
Java数据结构之双向链表图解
双向链表(Doubly linked list) 什么是双向链表? 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱.所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点. 双向链表与单向链表的主要区别: 查找方向 : 单向链表的查找方向只能是一个方向,而双向链表可以向前或者向后查找.删除: 单向链表的删除需要借助辅助指针,先找到要删除节点的前驱,然后进行删除. temp.next = temp.next