高斯混合模型与EM算法图文详解
目录
- 一、前言
- 二、高斯混合模型(GMM)
- 三、最大似然估计
- 总结而言:
- 四、EM算法
- 五、EM算法的简单理解方式
- 六、EM算法推导
- 总结而言
- 总结
一、前言
高斯混合模型(Gaussian Mixture Model)简称GMM,是一种业界广泛使用的聚类算法。它是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多种不同的分布的情况。高斯混合模型使用了期望最大(Expectation Maximization, 简称EM)算法进行训练,故此我们在了解GMM之后,也需要了解如何通过EM算法训练(求解)GMM。
二、高斯混合模型(GMM)
在了解高斯混合模型之前,我们先了解一下这种模型的具体参数模型-高斯分布。高斯分布又称正态分布,是一种在自然界中大量存在的,最为常见的分布形式。

如上图,这是一个关于身高的生态分布曲线,关于175-180对称,中间高两边低,相信大家在高中已经很了解了,这里就不再阐述。
现在,我们引用《统计学习方法》-李航 书中的定义,如下图:

根据定义,我们可以理解为,GMM是多个高斯分布的加权和,并且权重α之和等于1。这里不难理解,因为GMM最终反映出的是一个概率,而整个模型的概率之和为1,所以权重之和即为1。高斯混合模型实则不难理解,接下来我们介绍GMM的训练(求解)方法。
PS.从数学角度看,对于一个概率模型的求解,即为求其最大值。从深度学习角度看,我们希望降低这个概率模型的损失函数,也就是希望训练模型,获得最大值。训练和求解是不同专业,但相同目标的术语。
三、最大似然估计
想要了解EM算法,我们首先需要了解最大似然估计这个概念。我们通过一个简单的例子来解释一下。
假设,我们需要调查学校男女生的身高分布。我们用抽样的思想,在校园里随机抽取了100男生和100女生,共计200个人(身高样本数据)。我们假设整个学校的身高分布服从于高斯分布。但是这个高斯分布的均值u和方差∂2我们不知道,这两个参数就是我们需要估计的值。记作θ=[u, ∂]T。
由于每个样本都是独立地从p(x|θ)中抽取的,并且所有的样本都服从于同一个高斯分布p(x|θ)。那么我们从整个学校中,那么我抽到男生A(的身高)的概率是p(xA|θ),抽到男生B的概率是p(xB|θ)。而恰好抽取出这100个男生的概率,就是每个男生的概率乘积。用下式表示:

这个概率反映了,在概率密度函数的参数是θ时,得到X这组样本的概率。在公式中,x已知,而θ是未知,所以它是θ的函数。这个函数放映的是在不同的参数θ取值下,取得当前这个样本集的可能性,因此称为参数θ相对于样本集X的似然函数(likehood function)。记为L(θ)。
我们先穿插一个小例子,来阐述似然的概念。
某位同学与一位猎人一起外出打猎,一只野兔从前方窜过。只听一声枪响,野兔应声到下,如果要你推测,这一发命中的子弹是谁打的?你就会想,只发一枪便打中,由于猎人命中的概率一般大于这位同学命中的概率,看来这一枪是猎人射中的。
这个例子所作的推断就体现了极大似然法的基本思想,我们并不知道具体是谁打的兔子,但是我们可以估计到一个看似正确的参数。回到男生身高的例子中。在整个学校中我们一次抽到这100个男生(样本),而不是其他的人,那么我们可以认为这100个男生(样本)出现的概率最大,用上面的似然函数L(θ)来表示。
所以,我们就只需要找到一个参数θ,其对应的似然函数L(θ)最大,也就是说抽到这100个男生(的身高)概率最大。这个叫做θ的最大似然估计量,记为:
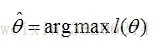
因为L(θ)是一个连乘函数,我们为了便于分析,可以定义对数似然函数,运用对数的运算规则,把连乘转变为连加:

PS.这种数学方法在MFCC中我们曾经用过,可以回溯一下上一篇文章。
此时,我们要求θ,只需要使θ的似然函数L(θ)极大化,然后极大值对应的θ就是我们的估计。在数学中求一个函数的最值问题,即为求导,使导数为0,解方程式即可(前提是函数L(θ)连续可微)。在深度学习中,θ是包含多个参数的向量,运用高等数学中的求偏导,固定其中一个变量的思想,即可求出极致点,解方程。
总结而言:
最大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
求最大似然函数估计值的一般步骤:
- 写出似然函数;
- 对似然函数取对数,并整理;(化乘为加)
- 求导数,令导数为0,得到似然方程;
- 解似然方程,得到的参数即为所求。
四、EM算法
期望最大(Expectation Maximization, 简称EM)算法,称为机器学习十大算法之一。它是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
现在,我们重新回到男女生身高分布的例子。我们通过抽取100个男生身高,并假设身高分布服从于高斯分布,我们通过最大化其似然函数,可以求的高斯分布的参数θ=[u, ∂]T了,对女生同理。但是,假如这200人,我们只能统计到其身高数据,但是没有男女信息(其实就是面对200个样本,抽取得到的每个样本都不知道是从哪个分布抽取的,这对于深度学习的样本分类很常见)。这个时候,我们需要对样本进行两个东西的猜测或者估计了。
EM算法就可以解决这个问题。假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
在男女生身高分布的例子中,我们运用EM算法的思想。首先随便猜一下男生的高斯分布参数:均值和方差。假设均值是1.7米,方差是0.1米,然后计算出每个人更可能属于第一个还是第二个正态分布中。这是第一步,Expectation。在分开了两类之后,我们可以通过之前用的最大似然,通过这两部分,重新估算第一个和第二个分布的高斯分布参数:均值和方差。这是第二步,Maximization。然后更新这两个分布的参数。这是可以根据更新的分布,重新调整E(Expectation)步骤...如此往复,迭代到参数基本不再发生变化。
这里原作者提到了一个数学思维,很受启发,转给大家看一眼(比较鸡汤和啰嗦,大家可以跳过)
这时候你就不服了,说你老迭代迭代的,你咋知道新的参数的估计就比原来的好啊?为什么这种方法行得通呢?有没有失效的时候呢?什么时候失效呢?用到这个方法需要注意什么问题呢?呵呵,一下子抛出那么多问题,搞得我适应不过来了,不过这证明了你有很好的搞研究的潜质啊。呵呵,其实这些问题就是数学家需要解决的问题。在数学上是可以稳当的证明的或者得出结论的。那咱们用数学来把上面的问题重新描述下。(在这里可以知道,不管多么复杂或者简单的物理世界的思想,都需要通过数学工具进行建模抽象才得以使用并发挥其强大的作用,而且,这里面蕴含的数学往往能带给你更多想象不到的东西,这就是数学的精妙所在啊)
五、EM算法的简单理解方式
在提出EM算法的推导过程之前,先提出中形象的理解方式,便于大家理解整个EM算法,如果只是实现深度学习模型,个人认为可以不需要去看后面的算法推导,看这个就足够了。
坐标上升法(Coordinate ascent):

图中的直线式迭代优化的途径,可以看到每一步都会向最优值靠近,而每一步前进的路线都平行于坐标轴。那么我们可以将其理解为两个未知数的方程求解。俩个未知数求解的方式,其实是固定其中一个未知数,求另一个未知数的偏导数,之后再反过来固定后者,求前者的偏导数。EM算法的思想,其实也是如此。使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。对应到EM上,E步:固定θ,优化Q;M步:固定Q,优化θ;交替将极值推向最大。
六、EM算法推导
现在很多深度学习框架可以简单调用EM算法,实际上这一段大家可以不用看,直接跳过看最后的总结即可。但是如果你希望了解一些内部的逻辑,可以看一下这一段推导过程。
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本(右上角为样本序号)。但每个样本i对应的类别z(i)是未知的(相当于聚类),也即隐含变量。故我们需要估计概率模型p(x,z)的参数θ(在文中可理解为高斯分布),但是由于里面包含隐含变量z,所以很难用最大似然求解,但如果z知道了,那我们就很容易求解了。
首先放出似然函数公式,我们接下来对公式进行化简:

对于参数估计,我们本质上的思路是想获得一个使似然函数最大化的参数θ,现在多出一个未知变量z,公式(1)。那么我们的目标就转变为:找到适合的θ和z让L(θ)最大。
对于多个未知数的方程分别对未知的θ和z分别求偏导,再设偏导为0,即可解方程。
因为(1)式是和的对数,当我们在求导的时候,形式会很复杂。
这里我们需要做一个数学转化。我们对和的部分,乘以一个相等的函数,得到(2)式,利用Jensen不等式的性质,将(2)式转化为(3)式。(Jensen不等式数学推到比较复杂,知道结果即可)
Note:
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X])
特别地,如果f是严格凸函数,当且仅当X是常量时,上式取等号。参考链接: https://blog.csdn.net/zouxy09/article/details/8537620
至此,上面的式(2)和式(3)不等式可以写成:似然函数L(θ)>=J(z,Q),那么我们可以通过不断的最大化这个下界J(z,Q)函数,来使得L(θ)不断提高,最终达到它的最大值。
现在,我们推导出了在固定参数θ后,使下界拉升的Q(z)的计算公式就是后验概率,解决了Q(z)如何选择的问题。这一步就是E步,建立L(θ)的下界。接下来的M步,就是在给定Q(z)后,调整θ,去极大化L(θ)的下界J(在固定Q(z)后,下界还可以调整的更大)。
总结而言
EM算法是一种从不完全数据或有数据丢失的数据集(存在隐藏变量)中,求解概率模型参数的最大似然估计方法。
EM的算法流程:
1>初始化分布参数θ;
重复2>, 3>直到收敛:
2>E步骤(Expectation):根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:

3>M步骤(Maximization):将似然函数最大化以获得新的参数值:
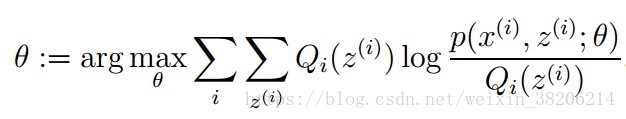
这个不断迭代的过程,最终会让E、M步骤收敛,得到使似然函数L(θ)最大化的参数θ。
在L(θ)的收敛证明:

总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

EM算法的python实现的方法步骤
前言:前一篇文章大概说了EM算法的整个理解以及一些相关的公式神马的,那些数学公式啥的看完真的是忘完了,那就来用代码记忆记忆吧!接下来将会对python版本的EM算法进行一些分析. EM的python实现和解析 引入问题(双硬币问题) 假设有两枚硬币A.B,以相同的概率随机选择一个硬币,进行如下的抛硬币实验:共做5次实验,每次实验独立的抛十次,结果如图中a所示,例如某次实验产生了H.T.T.T.H.H.T.H.T.H,H代表正面朝上. 假设试验数据记录员可能是实习生,业务不一定熟悉,造成a和b两种
-
python em算法的实现
''' 数据集:伪造数据集(两个高斯分布混合) 数据集长度:1000 ------------------------------ 运行结果: ---------------------------- the Parameters set is: alpha0:0.3, mu0:0.7, sigmod0:-2.0, alpha1:0.5, mu1:0.5, sigmod1:1.0 ---------------------------- the Parameters predict is: al
-
Python实现EM算法实例代码
EM算法实例 通过实例可以快速了解EM算法的基本思想,具体推导请点文末链接.图a是让我们预热的,图b是EM算法的实例. 这是一个抛硬币的例子,H表示正面向上,T表示反面向上,参数θ表示正面朝上的概率.硬币有两个,A和B,硬币是有偏的.本次实验总共做了5组,每组随机选一个硬币,连续抛10次.如果知道每次抛的是哪个硬币,那么计算参数θ就非常简单了,如 下图所示: 如果不知道每次抛的是哪个硬币呢?那么,我们就需要用EM算法,基本步骤为: 1.给θ_AθA和θ_BθB一个初始值: 2.(E-
-
Java虚拟机类加载器之双亲委派机制模型案例
1. 双亲委派模型是什么? 当某个类加载器需要加载某个.class字节码文件时,它首先把这个任务委托给它的上级类加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类. 2. 双亲委派模型的工作原理? 1.如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去执行: 2.如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器:(每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶
-
django模型查询操作的实现
目录 1.创建对象 2.保存ForeignKey和ManyToManyField字段 3.检索对象 跨越多值的关系查询 使用F表达式引用模型的字段: 4.缓存和查询集 5.使用Q对象进行复杂查询 6.比较对象 7.删除对象 8.复制模型实例 9.批量更新对象 10.关系的对象 反向查询: 11.使用原生SQL语句 一旦创建好了数据模型,Django就会自动为我们提供一个数据库抽象API,允许创建.检索.更新和删除对象操作 下面的示例都是通过下面参考模型来对模型字段进行操作说明: from dja
-
高斯混合模型与EM算法图文详解
目录 一.前言 二.高斯混合模型(GMM) 三.最大似然估计 总结而言: 四.EM算法 五.EM算法的简单理解方式 六.EM算法推导 总结而言 总结 一.前言 高斯混合模型(Gaussian Mixture Model)简称GMM,是一种业界广泛使用的聚类算法.它是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多种不同的分布的情况.高斯混合模型使用了期望最大(Expectation Maximization, 简称EM)算法进行训练,故此我们在
-
通俗易懂的C++前缀和与差分算法图文详解
目录 1.前缀和 2.前缀和算法有什么好处? 3.二维前缀和 4.差分 5.一维差分 6.二维差分 1.前缀和 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的逆运算.合理的使用前缀和与差分,可以将某些复杂的问题简单化. 2.前缀和算法有什么好处? 先来了解这样一个问题: 输入一个长度为n的整数序列.接下来再输入m个询问,每个询问输入一对l, r.对于每个询问,输出原序列中从第l个数到第r个数的和. 我们很容易想出暴力解法,遍历区间求和. 代码如下: in
-
vue2从数据变化到视图变化之diff算法图文详解
目录 引言 1.isUndef(oldStartVnode) 2.isUndef(oldEndVnode) 3.sameVnode(oldStartVnode, newStartVnode) 4.sameVnode(oldEndVnode, newEndVnode) 5.sameVnode(oldStartVnode, newEndVnode) 6.sameVnode(oldEndVnode, newStartVnode) 7.如果以上都不满足 小结 引言 vue数据的渲染会引入视图的重新渲染.
-
Python代码实现粒子群算法图文详解
目录 1.引言 2.算法的具体描述: 2.1原理 2.2标准粒子群算法流程 3.代码案例 3.1问题 3.2绘图 3.3计算适应度 3.4更新速度 3.5更新粒子位置 3.6主要算法过程 结果 总结 1.引言 粒子群优化算法起源于对鸟群觅食活动的分析.鸟群在觅食的时候通常会毫无征兆的聚拢,分散,以及改变飞行的轨迹,但是在不同个体之间会十分默契的保持距离.所以粒子群优化算法模拟鸟类觅食的过程,将待求解问题的搜索空间看作是鸟类飞行的空间,将每只鸟抽象成一个没有质量和大小的粒子,用这个粒子来表示待求解
-
java排序算法图文详解
目录 一.直接插入排序 二. 希尔排序 三.冒泡排序 四.快速排序 五.选择排序(Selection Sort) 六.堆排序 一.堆排序的基本思想是: 二.代码示例 七.归并排序 总结 一.直接插入排序 基本思想: 将一个记录插入到已排序的有序表中,使插入后的表仍然有序 对初始关键字{49 38 65 97 76 13 27 49}进行直接插入排序 package Sort; //插入排序 public class InsertSort { public static void main(Str
-
图文详解感知机算法原理及Python实现
目录 写在前面 1.什么是线性模型 2.感知机概述 3.手推感知机原理 4.Python实现 4.1 创建感知机类 4.2 更新权重与偏置 4.3 判断误分类点 4.4 训练感知机 4.5 动图可视化 5.总结 写在前面 机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用.“深”在详细推导算法模型背后的数学原理:“广”在分析多个机器学习模型:决策树.支持向量机.贝叶斯与马尔科夫决策.强化学习等. 本期目标:实现这样一个效果 1.什么是线性模型 线性模型的假设形式是属性权重.偏置与属性
-
图文详解牛顿迭代算法原理及Python实现
目录 1.引例 2.牛顿迭代算法求根 3.牛顿迭代优化 4 代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何计算函数零点x0 在数学上我们如何处理这个问题? 最简单的办法是解方程f(x)=0,在代数学上还有著名的零点判定定理 如果函数y=f(x)在区间[a,b]上的图象是连续不断的一条曲线,并且有f(a)⋅f(b)<0,那么函数y=f(x)在区间(a,b)内有零点,即至少存在一个c∈(a,b),使得f(c)=0,这个c也就是方程f(x)=0的根. 然而,数学上的方法并不一定
-
IIS7.0 Windows Server 2008 R2 下配置证书服务器和HTTPS方式访问网站的教程图文详解
配置环境 Windows版本:Windows Server 2008 R2 Enterprise Service Pack 1 系统类型: 64 位操作系统 了解HTTPS 为什么需要 HTTPS ? 在我们浏览网站时,多数网站的URL都是以HTTP开头,HTTP协议我们比较熟悉,信息通过明文传输; 使用HTTP协议有它的优点,它与服务器间传输数据更快速准确; 但是HTTP明显是不安全的,我们也可以注意到,当我们在使用邮件或者是在线支付时,都是使用HTTPS; HTTPS传输数据需要使用证书并对
-
图文详解Android属性动画
Android中的动画分为视图动画(View Animation).属性动画(Property Animation)以及Drawable动画.从Android 3.0(API Level 11)开始,Android开始支持属性动画,本文主要讲解如何使用属性动画.关于视图动画可以参见博文<Android四大视图动画图文详解>. 一.概述 视图动画局限比较大,如下所述: 1.视图动画只能使用在View上面. 2.视图动画并没有真正改变View相应的属性值,这导致了UI效果与实际View状态存在差异
-
SSH原理及两种登录方法图文详解
SSH(Secure Shell)是一套协议标准,可以用来实现两台机器之间的安全登录以及安全的数据传送,其保证数据安全的原理是非对称加密. 传统的对称加密使用的是一套秘钥,数据的加密以及解密用的都是这一套秘钥,可想而知所有的客户端以及服务端都需要保存这套秘钥,泄露的风险很高,而一旦秘钥便泄露便保证不了数据安全. 非对称加密解决的就是这个问题,它包含两套秘钥 - 公钥以及私钥,其中公钥用来加密,私钥用来解密,并且通过公钥计算不出私钥,因此私钥谨慎保存在服务端,而公钥可以随便传递,即使泄露也无风险.