java面试散列表及树所对应容器类及HashMap冲突解决全面分析
目录
- 性能分析
- HashMap 产生冲突原因及解决方法
- HashMap 解决冲突方法
- jdk7 与 jdk8 中HashMap的区别
- 发生冲突
- 扩容
- 使用建议
散列表 Hashmap、hashtable、concurrentHashMap、hashset;
树: treemap、treeset、hashset
treeset 继承自 treemap,hashset 继承自 hashmap ;
性能分析
Map 是 Java 中的接口,Map.Entry 是 Map 的一个内部接口 Map 提供了一些常用方法,例如 keySet()、entrySet() 方法等;
Entry: key 和 value的组合,即为一个映射项<K,V>
Treemap 底层数据结构是红黑树,元素存储是有序的,因此添加元素需要循环查找 Entry 插入位置、取出元素时需要遍历才能找到合适的 Entry ,比较耗性能;treemap、treeset 对比 hashmap、hashset 优势:前者元素都以有序状态排列
HashMap 产生冲突原因及解决方法
调用hashCode() 计算 hashCode ,两个不同对象可能有相同的 hashCode ,导致冲突产生,
bucket ,哈希表中的数组中可以存储 hashcode 相同对象,每个bucket 都有其指定索引,系统可以根据索引快速访问该 bucket 里存储的元素

HashMap 解决冲突方法
1,开放定址法:通过探测算法,档一个槽位被占用情况下继续查找下一个;
探测算法的三种方式:
- 线性探查
- 二次探查
- 双重散列 采用两个辅助散列函数合成一个:
h1、h2为两个散列函数
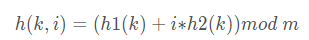
2,链地址法:数组+链表,将hash 值相同对象组织为一个链表放在 hash值对应的 bucket
3,再哈希,准备多个散列函数,当发生冲突时再选择一个散列函数进行散列,原理与双重散列相似
jdk7 与 jdk8 中HashMap的区别
发生冲突
- jdk7 中 hashMap 采用数组+链表。如果过多节点在 hash 时发生碰撞,如果要查找其中一个节点,需要
O(n)的查找时间。 - jdk8 中 hashMap 采用数组+链表/红黑树,出现 hash 冲突时会进行判断,该节点是红黑树还是量表:
如果是链表的话,数据插入链表尾部并判断链表长度是否达到某个阈值(默认阈值为 8 ),如果大于阈值,链表将转化为红黑树,时间复杂度为O(nlogn);
若是红黑树的话, 直接插入红黑树即可;
数据结构红黑树的几个性质,查询效率非常高,10亿数据进行不到30次比较就能查找到目标

1、每个节点要么是黑色、要么是红色;
2、根节点是黑色;
3、每个叶子节点是黑色;
4、每个红色节点的两个子结点一定都是黑色;
5、任意一结点到每个叶子节点的路径都包含相同数量的黑节点;
扩容
JDK7 扩容时,在 resize() 过程中采用头插法,旧数据转移到新数组中,转移操作=正序遍历俩表,在头部依次插入,即链表逆序;多线程下 resize() 容易出现 死循环,在多线程下并发执行 put() 操作,一旦出现扩容情况,容易出现环形链表,在获取数据、遍历链表时出现死循环,即死锁转发太;
JDK 8 在扩容 resize() 时,数据转移时在新链表尾部依次插入,不会出现逆序、环形链表情况,但 jdk 1.8 仍是线程不安全的
使用建议
1,使用出初始值,避免多次扩容的性能消耗;
2,自定义对象作为 key,时需要重写 hashCode 、equals 方法;
3,多线程下, 使用 CurrentHashMap 代替 HashMap;
Reference
1, https://www.jb51.net/article/224721.htm
2, https://www.jianshu.com/p/e136ec79235c
3, https://zhuanlan.zhihu.com/p/59250175
以上就是java面试之散列表及树所对应容器类及HashMap冲突解决的详细内容,更多关于java散列表树所对应容器类HashMap冲突的资料请关注我们其它相关文章!
相关推荐
-
快速解决Hash碰撞冲突的方法小结
Hash碰撞冲突 我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突.如下将介绍如何处理冲突,当然其前提是一致性hash. 1.开放地址法 开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,-,k(k<=m-1) 其中,m为哈希表的表长.di 是产生冲突的时候的增量序列.如果di值可能为1,2,3,-m-1,称线性探测再散列. 如果d
-
学习Java HashMap,看这篇就够了
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步. HashMap 是无序的,即不会记录插入的顺序. HashMap 继承于AbstractMap,实现了 Map.Cloneable.java.io.Serializable 接口. HashMap 的 key 与 value 类型可以相同也可以不同,可以是字符串(Str
-

一文彻底搞定Java哈希表和哈希冲突
一.什么是哈希表? 哈希表也叫散列表,它是基于数组的.这间接带来了一个优点:查找的时间复杂度为 O(1).当然,它的插入时间复杂度也是 O(1).还有一个缺点:数组创建后扩容成本较高. 哈希表中有一个"主流"思想:转换.一个重要的概念是将「键」或「关键字」转换成数组下标.这由"哈希函数"完成. 二.什么是哈希函数? 由上,其作用就是将非 int 的键/关键字转化为 int 的值,使可以用来做数组下标. 比如,HashMap 中就这样实现了哈希函数: static f
-
java集合类HashMap源码解析
Map集合 Map集合存储的是键值对 Map集合的实现类: HashTable.LinkedHashMap.HashMap.TreeMap HashMap 基础了解: 1.键不可以重复,值可以重复: 2.底层使用哈希表实现: 3.线程不安全: 4.允许key为null,但只允许有一条记录为null,value也可以为null,允许多条记录为null: 源码分析 (一)以JDK1.7为例 1.存储结构 数据结构:数组+链表 首先hashmap内部有一个Entry类型的数组table: 通过Entr
-
java教程散列表和树所对应容器类及HashMap解决冲突学习
目录 java中散列表.树所对应的的容器类 jdk7与jdk8中HashMap的区别 HashMap如何解决冲突 HashMap的工作原理 java中散列表.树所对应的的容器类 散列表:hashmap,hashtable,concurrentHashmap 树:hashset,treemap,treeset jdk7与jdk8中HashMap的区别 jdk7中hashMap采用数组+链表,如果过多的节点在hash时发生碰撞,如果要查找其中一个节点,需要O(n)的查找时间. jdk7中hashMa
-
java开放地址法和链地址法解决hash冲突的方法示例
hashMap对各位小伙们来说,没有不知道的了,使用过的人想必或多或少的都了解一点hashMap的底层实现原理,总结来说就是,数组+链表,至于源码的实现,大家可参看源码,今天想说的是hashMap是怎么解决hash冲突的呢? 首先看一张图, 从这张图也大概可以看出来,hashMap维护的是一个数组,数组里面的每个单元又是一个个链表,那么为什么会产生hash冲突呢?这也就是接下来要探讨的问题. 既是数组,必然会有长度,当我们在往数组中插入数据的时候,不管是什么类型的数据,对于数组来说,就是占据了某
-
java面试散列表及树所对应容器类及HashMap冲突解决全面分析
目录 性能分析 HashMap 产生冲突原因及解决方法 HashMap 解决冲突方法 jdk7 与 jdk8 中HashMap的区别 发生冲突 扩容 使用建议 散列表 Hashmap.hashtable.concurrentHashMap.hashset: 树: treemap.treeset.hashset treeset 继承自 treemap,hashset 继承自 hashmap : 性能分析 Map 是 Java 中的接口,Map.Entry 是 Map 的一个内部接口 Map 提供了
-
C#算法之散列表
目录 1.散列函数 正整数 浮点数 字符串 组合键 将 HashCode() 的返回值转化为一个数组索引 自定义的 HashCode 软缓存 2.基于拉链法的散列表 散列表的大小 删除操作 有序性相关的操作 3.基于线性探测法的散列表 删除操作 键簇 线性探测法的性能分析 调整数组大小 拉链法 均摊分析 4.内存的使用 如果所有的键都是小整数,我们可以使用一个数组来实现无序的符号表,将键作为数组的索引而数组中键 i 处存储的就是它对应的值.散列表就是用来处理这种情况,它是简易方法的扩展并能够处理
-
Java数据结构之散列表详解
目录 介绍 1 散列表概述 1.1 散列表概述 1.2 散列冲突(hash collision) 2 散列函数的选择 2.1 散列函数的要求 2.2 散列函数构造方法 3 散列冲突的解决 3.1 分离链接法 3.2 开放定址法 3.3 再散列法 4 散列表的简单实现 4.1 测试 介绍 本文详细介绍了散列表的概念.散列函数的选择.散列冲突的解决办法,并且最后提供了一种散列表的Java代码实现. 数组的特点是寻址容易,插入和删除困难:而链表的特点是寻址困难,插入和删除容易.而对于tree结构,它们
-
Java数据结构之散列表(动力节点Java学院整理)
基本概念 散列表(Hash table,也叫哈希表),是根据关键字(key value)而直接进行访问的数据结构. 说的具体点就是它通过吧key值映射到表中的一个位置来访问记录,从而加快查找的速度. 实现key值映射的函数就叫做散列函数 存放记录的数组就就叫做散列表 实现散列表的过程通常就称为散列(hashing),也就是常说的hash 散列 这里的散列的概念不仅限于数据结构了,在计算机科学领域中,散列-哈希是一种对信息的处理方法,通过某种特定的函数/算法(散列函数/hash()方法)将要检索的
-
散列表的原理与Java实现方法详解
本文实例讲述了散列表的原理与Java实现方法.分享给大家供大家参考,具体如下: 概述 符号表是一种用于存储键值对(key-value pair)的数据结构,我们平常经常使用的数组也可以看做是一个特殊的符号表,数组中的"键"即为数组索引,值为相应的数组元素.也就是说,当符号表中所有的键都是较小的整数时,我们可以使用数组来实现符号表,将数组的索引作为键,而索引处的数组元素即为键对应的值,但是这一表示仅限于所有的键都是比较小的整数时,否则可能会使用一个非常大的数组.散列表是对以上策略的一种&
-
如何在Java中实现一个散列表
目录 前言: 优化1 优化2 优化3 如何实现 总结 前言: 假设现在有一篇很长的文档,如果希望统计文档中每个单词在文档中出现了多少次,应该怎么做呢? 很简单! 我们可以建一个HashMap,以String类型为Key,Int类型为Value: 遍历文档中的每个单词 word ,找到键值对中key为 word 的项,并对相关的value进行自增操作. 如果该key= word 的项在 HashMap中不存在,我们就插入一个(word,1)的项表示新增. 这样每组键值对表示的就是某个单词对应的数量
-
Java利用TreeUtils工具类实现列表转树
目录 一.序言 二.实战编码 1.引入坐标 2.编写DO 3.创建BO 3.调用TreeUtils工具类 4.效果展示 三.小结 一.序言 在日常一线开发过程中,总有列表转树的需求,几乎是项目的标配,比方说做多级菜单.多级目录.多级分类等,有没有一种通用且跨项目的解决方式呢?帮助广大技术朋友给业务瘦身,提高开发效率. 本文将基于Java8的Lambda 表达式和Stream等知识,使用TreeUtils工具类实现一行代码完成列表转树这一通用型需求.本文有配套视频,传送门直达. 需要说明的是,本T
-
Java面试问题知识点总结
本篇文章会对面试中常遇到的Java技术点进行全面深入的总结(阅读本文需要有一定的Java基础:若您初涉Java,可以通过这些问题建立起对Java初步的印象,待有了一定基础后再后过头来看收获会更大),喜欢的朋友可以参考下. 1. Java中的原始数据类型都有哪些,它们的大小及对应的封装类是什么? (1)boolean boolean数据类型非true即false.这个数据类型表示1 bit的信息,但是它的大小并没有精确定义. <Java虚拟机规范>中如是说:"虽然定义了boolean这
-
Java面试重点中的重点之Elasticsearch核心原理
目录 Elasticsearch简介 Elasticsearch是什么?它能干什么? 从核心概念开始 Lucence 核心数据结构 Document Index 倒排索引 FST 集群相关概念 节点 分片 总结 Elasticsearch简介 Elasticsearch是什么?它能干什么? Elasticsearch(以下称之为ES)是一款基于Lucene的分布式全文搜索引擎,擅长海量数据存储.数据分析以及全文检索查询,它是一款非常优秀的数据存储与数据分析中间件,广泛应用于日志分析以及全文检索等