mysql自动插入百万模拟数据的操作代码
本人数据库工具用的navicat 其他的大同小异
1.打开navicat,在对应的数据库下有个函数菜单,右键新建函数==》完成
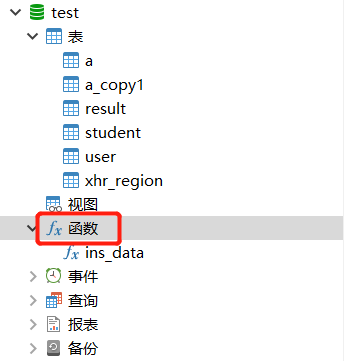

2.创建测试表 user,懒得写语句 反正每个人需要的表不一样
3.创建函数,直接上代码!注意中间的insert语句换成你自己需要的插入语句,可利用随机方法保证生成的数据不同
CREATE DEFINER=`root`@`localhost` FUNCTION `ins_data`(`num` int) RETURNS int(11)
BEGIN
DECLARE i int DEFAULT 0;
WHILE i<num DO
INSERT INTO `user` (`name`,email,phone,sex,password,age,create_time)
values(concat('用户',i),'12345678@qq.com'
,CONCAT('18',FLOOR(rand()*(999999999-100000000)+100000000))
,FLOOR(RAND()*2),UUID(),FLOOR(RAND()*100)
,now());
set i = i+1;
END WHILE;
RETURN i;
END
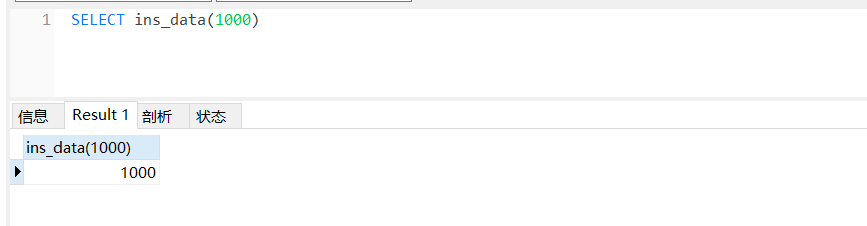
4.测试,返回值为生成的数据条数。
注:100万条数据可能需要生成几分钟,中途进行其他操作有可能会导致失败
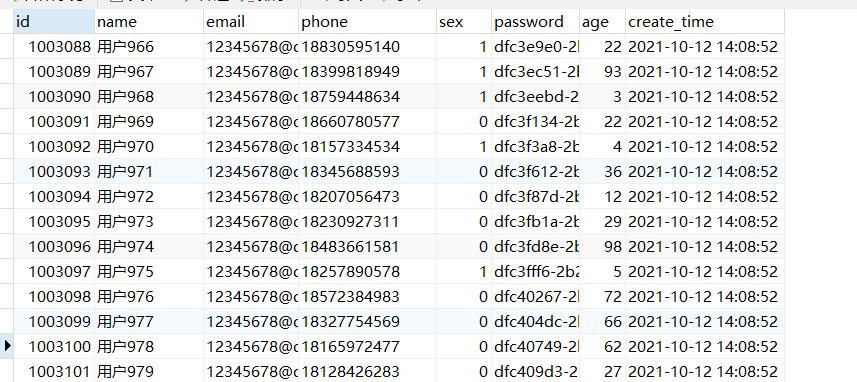
搞定!
到此这篇关于mysql自动插入百万模拟数据的文章就介绍到这了,更多相关mysql自动插入数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySql三种避免重复插入数据的方法
前言 MySql 在存在主键冲突或唯一键冲突的情况下,根据插入方式,一般有以下三种插入方式避免错误. insert ignore. replace into insert on duplicate key update insert ignore insert ignore 会忽视数据库中已经存在的数据,根据主键或者唯一索引判断,如果数据库没有数据,就会插入新的数据,如果有数据的话就跳过这条数据 小case 表结构 root:test> show create table t3G *******
-

Mysql避免重复插入数据的4种方式
最常见的方式就是为字段设置主键或唯一索引,当插入重复数据时,抛出错误,程序终止,但这会给后续处理带来麻烦,因此需要对插入语句做特殊处理,尽量避开或忽略异常,下面我简单介绍一下,感兴趣的朋友可以尝试一下: 这里为了方便演示,我新建了一个user测试表,主要有id,username,sex,address这4个字段,其中主键为id(自增),同时对username字段设置了唯一索引: 01 insert ignore into 即插入数据时,如果数据存在,则忽略此次插入,前提条件是插入的数据字段设置了
-
mysql大批量插入数据的4种方法示例
前言 本文主要给大家介绍了关于mysql大批量插入数据的4种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 方法一:循环插入 这个也是最普通的方式,如果数据量不是很大,可以使用,但是每次都要消耗连接数据库的资源. 大致思维如下 (我这里写伪代码,具体编写可以结合自己的业务逻辑或者框架语法编写) for($i=1;$i<=100;$i++){ $sql = 'insert...............'; //querysql } foreach($arr as $key =
-
MySql批量插入时如何不重复插入数据
目录 前言 一.insert ignore into 二.on duplicate key update 三.replace into 总结 前言 Mysql插入不重复的数据,当大数据量的数据需要插入值时,要判断插入是否重复,然后再插入,那么如何提高效率?解决的办法有很多种,不同的场景解决方案也不一样,数据量很小的情况下,怎么搞都行,但是数据量很大的时候,这就不是一个简单的问题了. 一.insert ignore into 会忽略数据库中已经存在 的数据,如果数据库没有数据,就插入新的数据,如果
-
MySQL删除和插入数据很慢的问题解决
公司开发人员在测试环境中执行一条 insert 语句时,需要花费 10 几秒才可以执行成功.查看测试环境数据库性能.数据量.死锁等信息,均为发现异常.最后通过修改日志写入方式解决此问题. 1. 修改办法 修改/etc/my.cnf文件,将 innodb_flush_log_at_trx_commit = 1改为0, 但这样就要承担数据库Crash后,1秒内未存储到数据库数据丢失可能的风险.MySQL文档中对该参数的描述如下: If the value of innodb_flush_log_at
-
mysql自动插入百万模拟数据的操作代码
本人数据库工具用的navicat 其他的大同小异 1.打开navicat,在对应的数据库下有个函数菜单,右键新建函数==>完成 2.创建测试表 user,懒得写语句 反正每个人需要的表不一样 3.创建函数,直接上代码!注意中间的insert语句换成你自己需要的插入语句,可利用随机方法保证生成的数据不同 CREATE DEFINER=`root`@`localhost` FUNCTION `ins_data`(`num` int) RETURNS int(11) BEGIN DECLARE i i
-
MySQL数据库10秒内插入百万条数据的实现
首先我们思考一个问题: 要插入如此庞大的数据到数据库,正常情况一定会频繁地进行访问,什么样的机器设备都吃不消.那么如何避免频繁访问数据库,能否做到一次访问,再执行呢? Java其实已经给了我们答案. 这里就要用到两个关键对象:Statement.PrepareStatement 我们来看一下二者的特性: 要用到的BaseDao工具类 (jar包 / Maven依赖) (Maven依赖代码附在文末)(封装以便于使用) 注:(重点)rewriteBatchedStatements=true,一次插入
-
Mysql快速插入千万条数据的实战教程
一.创建数据库 二.创建表 1.创建 dept表 CREATE TABLE `dept` ( `id` int(11) NOT NULL, `deptno` mediumint(9) DEFAULT NULL, `dname` varchar(20) DEFAULT NULL, `loc` varchar(13) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 2.创建emp表 CREATE TABLE
-
java中JDBC实现往MySQL插入百万级数据的实例代码
想往某个表中插入几百万条数据做下测试,原先的想法,直接写个循环10W次随便插入点数据试试吧,好吧,我真的很天真.... DROP PROCEDURE IF EXISTS proc_initData;--如果存在此存储过程则删掉 DELIMITER $ CREATE PROCEDURE proc_initData() BEGIN DECLARE i INT DEFAULT 1; WHILE i<=100000 DO INSERT INTO text VALUES(i,CONCAT('姓名',i),
-
mysql 如何插入随机字符串数据的实现方法
应用场景: 有时需要测试插入数据库的记录来测试,所以就非常需要用到这些脚本. 创建表: CREATE TABLE `tables_a` ( `id` int(10) NOT NULL DEFAULT '0', `name` char(50) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 创建产生随机字符串的函数: set global log_bin_trust_function_creators =
-
用一条mysql语句插入多条数据
假如有一个数据表A: id name title addtime 如果需要插入n条数据 : $time= time(); $data = array( array( 'name'=>'name1','title'=>'title1','addtime'=>$time; ), array( 'name'=>'name2','title'=>'title2','addtime'=>$time; ), array( 'name'=>'name3','title'=>
-
MySQL循环插入千万级数据
1.创建测试表 CREATE TABLE `mysql_genarate` ( `id` int(11) NOT NULL AUTO_INCREMENT, `uuid` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5999001 DEFAULT CHARSET=utf8; 2.创建一个循环插入的存储过程 CREATE DEFINER=`root`@`localhost` PROCEDURE
-
python遍历迭代器自动链式处理数据的实例代码
目录 python遍历迭代器自动链式处理数据 附:python 手动遍历迭代器 总结 python遍历迭代器自动链式处理数据 pytorch.utils.data可兼容迭代数据训练处理,在dataloader中使用提高训练效率:借助迭代器避免内存溢出不足的现象.借助链式处理使得数据读取利用更高效(可类比操作系统的资源调控) 书接上文,使用迭代器链式处理数据,在Process类的__iter__方法中执行挂载的预处理方法,可以嵌套包裹多层处理方法,类似KoaJs洋葱模型,在for循环时,自动执行预
-
MySQL中一些常用的数据表操作语句笔记
0.创建表 CREATE TABLE 表名 (属性名 数据类型 [完整性约束条件], 属性名 数据类型 [完整性约束条件], 属性名 数据类型 [完整性约束条件]) "完整性约束条件"是指指定某些字段的某些特殊约束条件. 在使用CREATE TABLE创建表时首先要使用USE语句选择数据库.比如有个example数据库,用USE EXAMPLE选择这个数据库. 表名不能用SQL的关键字,如create,update等,字母不区分大小写. 下面是一个创建表的例子: create tabl
-
vue动态加载SVG文件并修改节点数据的操作代码
先上一个马赛克图片叭. 接领导需求,动态实现电路图, 并附带放大.缩小功能. 以及不同的回路点击能弹窗显示相关节点的更多信息, 通俗一点讲: 随着用户点击放大和缩小, 点击位置保持不变,而且能实现点击交互. 初接触的时候,觉得根本没法下手呀,说说自己的思路叭, 从随着用户点击放大缩小位置不变,想到了SVG 但是需要动态加载进来呀,而且还需要需求不同节点的电流值, 从放大缩小来看, 首先想到的是 D3 在集合领导给的部分相关资料 综上: 进行了可行性的方案试探,也完成了整个功能的开发. 且听我细细