python pytorch图像识别基础介绍
目录
- 一、数据集爬取
- 二、数据处理
- 三、开始识别
- 四、模型测试
- 总结
一、数据集爬取
现在的深度学习对数据集量的需求越来越大了,也有了许多现成的数据集可供大家查找下载,但是如果你只是想要做一下深度学习的实例以此熟练一下或者找不到好的数据集,那么你也可以尝试自己制作数据集——自己从网上爬取图片,下面是通过百度图片爬取数据的示例。
import os
import time
import requests
import re
def imgdata_set(save_path,word,epoch):
q=0 #停止爬取图片条件
a=0 #图片名称
while(True):
time.sleep(1)
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn={}&ct=&ic=0&lm=-1&width=0&height=0".format(word,q)
#word=需要搜索的名字
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
response=requests.get(url,headers=headers)
# print(response.request.headers)
html=response.text
# print(html)
urls=re.findall('"objURL":"(.*?)"',html)
# print(urls)
for url in urls:
print(a) #图片的名字
response = requests.get(url, headers=headers)
image=response.content
with open(os.path.join(save_path,"{}.jpg".format(a)),'wb') as f:
f.write(image)
a=a+1
q=q+20
if (q/20)>=int(epoch):
break
if __name__=="__main__":
save_path = input('你想保存的路径:')
word = input('你想要下载什么图片?请输入:')
epoch = input('你想要下载几轮图片?请输入(一轮为60张左右图片):') # 需要迭代几次图片
imgdata_set(save_path, word, epoch)
通过上述的代码可以自行选择自己需要保存的图片路径、图片种类和图片数目。如我下面做的几种常见的盆栽植物的图片爬取,只需要执行六次代码,改变相应的盆栽植物的名称就可以了。下面是爬取盆栽芦荟的输入示例,输入完成后按Enter执行即可,会自动爬取图片保存到指定文件夹,

如图即为爬取后的图片。
可以看到图片中出现了一些无法打开的图片,同时因为是直接爬取的网络上的图片,可能会出现一些相同的图片,这些都需要进行删除,这就需要我们进行第二步处理了。
二、数据处理
由于上面直接爬取到的图片有一些瑕疵,这就需要对图片进行进一步的处理了,对图片进行去重处理
通过重复图片去重处理,将自己需要的数据集按照种类分别保存在各自的文件夹里。同样,由于数据集可能存在无法打开的图片,这就需要对数据集进行下一步处理了。
首先将上面去重处理后的文件夹统一保存在同一个文件夹里面,如下图所示。
记住此文件夹路径,我这里是‘C:\Users\Lenovo\Desktop\data’,将此路径输入到下面代码中。
import os
from PIL import Image
root_path=r"C:\Users\Lenovo\Desktop\data" #待处理文件夹绝对路径(可按‘Ctrl+Shift+c'复制)
root_names=os.listdir(root_path)
for root_name in root_names:
path=os.path.join(root_path,root_name)
print("正在删除文件夹:",path)
names=os.listdir(path)
names_path=[]
for name in names:
# print(name)
img=Image.open(os.path.join(path,name))
name_path=os.path.join(path,name)
if img==None: #筛选无法打开的图片
names_path.append(name_path)
print('成功保存错误图片路径:{}'.format(name))
else:
w,h=img.size
if w<50 or h<50: #筛选错误图片
names_path.append(name_path)
print('成功保存特小图片路径:{}'.format(name))
print("开始删除需删除的图片")
for r in names_path:
os.remove(r)
print("已删除:",r)
经过上述处理即完成了图片数据集的处理。最后,也可以对图片数据集进行图片名称的处理,使图片的名称重新从零开始依次排列,方便计数(注意下面代码中的rename将会删除掉原文件夹中的图片)。
import os
root_dir=r"C:\Users\Lenovo\Desktop\pzlh" #原文件夹路径
save_path=r"C:\Users\Lenovo\Desktop\pzlh2" #新建文件夹路径
img_path=os.listdir(root_dir)
a=0
for i in img_path:
a+=1
i= os.path.join(os.path.abspath(root_dir), i)
new_name=os.path.join(os.path.abspath(save_path), str(a) + '_pzlh.jpg') #此处可以修改图片名称
os.rename(i,new_name) #特别注意:rename会删除原图
最后,我们可以得到一个将完整的常见盆栽植物的数据集。如果此时数据集的图片数量不多,我们还可以采用数据增强的方法,如旋转,加噪等步骤,都可以在网上找到相应的教程。最后,我们可以得到数据集如下图所示。

三、开始识别
首先,先为上面的图片数据集生成对应的标签文件,运行下面代码可以自动生成对应的标签文件。
import os
root_path=r"C:\Users\Lenovo\Desktop\data"
save_path=r"C:\Users\Lenovo\Desktop\data_label" #对应的label文件夹下也要建好相应的空子文件夹
names=os.listdir(root_path) #得到images文件夹下的子文件夹的名称
for name in names:
path=os.path.join(root_path,name)
img_names=os.listdir(path) #得到子文件夹下的图片的名称
for img_name in img_names:
save_name = img_name.split(".jpg")[0]+'.txt' #得到相应的lable名称
txt_path=os.path.join(save_path,name) #得到label的子文件夹的路径
with open(os.path.join(txt_path,save_name), "w") as f: #结合子文件夹路径和相应子文件夹下图片的名称生成相应的子文件夹txt文件
f.write(name) #将label写入对应txt文件夹
print(f.name)
然后,将上面已经准备好的数据集按照7:3(其他比例也可以)分为训练数据集和验证数据集(图片和标签一定要完全对应即对应图片和标签应该都处于训练集或者数据集),并如下图所示放置。
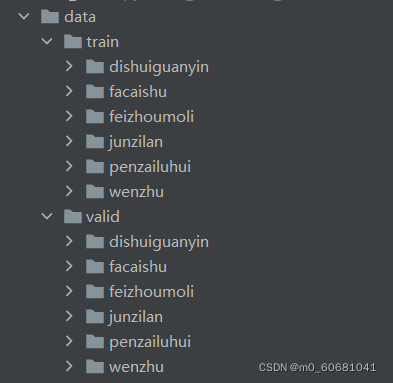
最后,数据集准备好后,即可导入到模型开始训练,运行下列代码
import time
from torch.utils.tensorboard import SummaryWriter
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision.models as models
import torch.nn as nn
import torch
print("是否使用GPU训练:{}".format(torch.cuda.is_available())) #打印是否采用gpu训练
if torch.cuda.is_available:
print("GPU名称为:{}".format(torch.cuda.get_device_name())) #打印相应的gpu信息
#数据增强太多也可能造成训练出不好的结果,而且耗时长,宜增强两三倍即可。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5]) #规范化
transform=transforms.Compose([ #数据处理
transforms.Resize((64,64)),
transforms.ToTensor(),
normalize
])
dataset_train=ImageFolder('data/train',transform=transform) #训练数据集
# print(dataset_tran[0])
dataset_valid=ImageFolder('data/valid',transform=transform) #验证或测试数据集
# print(dataset_train.classer)#返回类别
print(dataset_train.class_to_idx) #返回类别及其索引
# print(dataset_train.imgs)#返回图片路径
print(dataset_valid.class_to_idx)
train_data_size=len(dataset_train) #放回数据集长度
test_data_size=len(dataset_valid)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#torch自带的标准数据集加载函数
dataloader_train=DataLoader(dataset_train,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
dataloader_test=DataLoader(dataset_valid,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
#2.模型加载
model_ft=models.resnet18(pretrained=True)#使用迁移学习,加载预训练权重
# print(model_ft)
in_features=model_ft.fc.in_features
model_ft.fc=nn.Sequential(nn.Linear(in_features,36),
nn.Linear(36,6))#将最后的全连接改为(36,6),使输出为六个小数,对应六种植物的置信度
#冻结卷积层函数
# for i,para in enumerate(model_ft.parameters()):
# if i<18:
# para.requires_grad=False
# print(model_ft)
# model_ft.half()#可改为半精度,加快训练速度,在这里不适用
model_ft=model_ft.cuda()#将模型迁移到gpu
#3.优化器
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda() #将loss迁移到gpu
learn_rate=0.01 #设置学习率
optimizer=torch.optim.SGD(model_ft.parameters(),lr=learn_rate,momentum=0.01)#可调超参数
total_train_step=0
total_test_step=0
epoch=50 #迭代次数
writer=SummaryWriter("logs_train_yaopian")
best_acc=-1
ss_time=time.time()
for i in range(epoch):
start_time = time.time()
print("--------第{}轮训练开始---------".format(i+1))
model_ft.train()
for data in dataloader_train:
imgs,targets=data
# if torch.cuda.is_available():
# imgs.float()
# imgs=imgs.float()#为上述改为半精度操作,在这里不适用
imgs=imgs.cuda()
targets=targets.cuda()
# imgs=imgs.half()
outputs=model_ft(imgs)
loss=loss_fn(outputs,targets)
optimizer.zero_grad() #梯度归零
loss.backward() #反向传播计算梯度
optimizer.step() #梯度优化
total_train_step=total_train_step+1
if total_train_step%100==0:#一轮时间过长可以考虑加一个
end_time=time.time()
print("使用GPU训练100次的时间为:{}".format(end_time-start_time))
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
# writer.add_scalar("valid_loss",loss.item(),total_train_step)
model_ft.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad(): #验证数据集时禁止反向传播优化权重
for data in dataloader_test:
imgs,targets=data
# if torch.cuda.is_available():
# imgs.float()
# imgs=imgs.float()
imgs = imgs.cuda()
targets = targets.cuda()
# imgs=imgs.half()
outputs=model_ft(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的loss:{}(越小越好,与上面的loss无关此为测试集的总loss)".format(total_test_loss))
print("整体测试集上的正确率:{}(越大越好)".format(total_accuracy / len(dataset_valid)))
writer.add_scalar("valid_loss",(total_accuracy/len(dataset_valid)),(i+1))#选择性使用哪一个
total_test_step = total_test_step + 1
if total_accuracy > best_acc: #保存迭代次数中最好的模型
print("已修改模型")
best_acc = total_accuracy
torch.save(model_ft, "best_model_yaopian.pth")
ee_time=time.time()
zong_time=ee_time-ss_time
print("训练总共用时:{}h:{}m:{}s".format(int(zong_time//3600),int((zong_time%3600)//60),int(zong_time%60))) #打印训练总耗时
writer.close()
上述采用的迁移学习直接使用resnet18的模型进行训练,只对全连接的输出进行修改,是一种十分方便且实用的方法,同样,你也可以自己编写模型,然后使用自己的模型进行训练,但是这种方法显然需要训练更长的时间才能达到拟合。如图所示,只需要修改矩形框内部分,将‘model_ft=models.resnet18(pretrained=True)'改为自己的模型‘model_ft=model’即可。

四、模型测试
经过上述的步骤后,我们将会得到一个‘best_model_yaopian.pth’的模型权重文件,最后运行下列代码就可以对图片进行识别了
import os
import torch
import torchvision
from PIL import Image
from torch import nn
i=0 #识别图片计数
root_path="测试_data" #待测试文件夹
names=os.listdir(root_path)
for name in names:
print(name)
i=i+1
data_class=['滴水观音','发财树','非洲茉莉','君子兰','盆栽芦荟','文竹'] #按文件索引顺序排列
image_path=os.path.join(root_path,name)
image=Image.open(image_path)
print(image)
transforms=torchvision.transforms.Compose([torchvision.transforms.Resize((64,64)),
torchvision.transforms.ToTensor()])
image=transforms(image)
print(image.shape)
model_ft=torchvision.models.resnet18() #需要使用训练时的相同模型
# print(model_ft)
in_features=model_ft.fc.in_features
model_ft.fc=nn.Sequential(nn.Linear(in_features,36),
nn.Linear(36,6)) #此处也要与训练模型一致
model=torch.load("best_model_yaopian.pth",map_location=torch.device("cpu")) #选择训练后得到的模型文件
# print(model)
image=torch.reshape(image,(1,3,64,64)) #修改待预测图片尺寸,需要与训练时一致
model.eval()
with torch.no_grad():
output=model(image)
print(output) #输出预测结果
# print(int(output.argmax(1)))
print("第{}张图片预测为:{}".format(i,data_class[int(output.argmax(1))])) #对结果进行处理,使直接显示出预测的植物种类
最后,通过上述步骤我们可以得到一个简单的盆栽植物智能识别程序,对盆栽植物进行识别,如下图是识别结果说明。

到这里,我们就实现了一个简单的深度学习图像识别示例了。
总结
到此这篇关于python pytorch图像识别基础介绍的文章就介绍到这了,更多相关python pytorch图像识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pytorch实现图像识别之数字识别(附详细注释)
使用了两个卷积层加上两个全连接层实现 本来打算从头手撕的,但是调试太耗时间了,改天有时间在从头写一份 详细过程看代码注释,参考了下一个博主的文章,但是链接没注意关了找不到了,博主看到了联系下我,我加上 代码相关的问题可以评论私聊,也可以翻看博客里的文章,部分有详细解释 Python实现代码: import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transf
-
PyTorch一小时掌握之图像识别实战篇
目录 概述 预处理 导包 数据读取与预处理 数据可视化 主体 加载参数 建立模型 设置哪些层需要训练 优化器设置 训练模块 开始训练 测试 测试网络效果 测试训练好的模型 测试数据预处理 展示预测结果 概述 今天我们要来做一个进阶的花分类问题. 不同于之前做过的鸢尾花, 这次我们会分析 102 中不同的花. 是不是很上头呀. 预处理 导包 常规操作, 没什么好解释的. 缺模块的同学自行pip -install. import numpy as np import time from matplo
-
python pytorch图像识别基础介绍
目录 一.数据集爬取 二.数据处理 三.开始识别 四.模型测试 总结 一.数据集爬取 现在的深度学习对数据集量的需求越来越大了,也有了许多现成的数据集可供大家查找下载,但是如果你只是想要做一下深度学习的实例以此熟练一下或者找不到好的数据集,那么你也可以尝试自己制作数据集——自己从网上爬取图片,下面是通过百度图片爬取数据的示例. import os import time import requests import re def imgdata_set(save_path,word,epoch)
-
Python函数参数基础介绍及示例
目录 视频 函数的参数 位置参数 默认参数 默认参数陷阱 视频 观看视频 函数的参数 定义函数时,我们把参数的名字和位置确定下来,函数的接口定义就完成了.参数在函数名后的括号内指定.您可以根据需要添加任意数量的参数,只需用逗号分隔即可.对于函数的调用者,只需要知道如何传递正确的参数,以及函数将返回什么样的值就够了,函数内部的复杂逻辑被封装起来,调用者无需了解. Python的函数定义可以使用必选参数.默认参数.可变参数和关键字参数. 位置参数 我们先写一个计算x2的函数: def power(x
-
python机器学习pytorch 张量基础教程
目录 正文 1.初始化张量 1.1 直接从列表数据初始化 1.2 用 NumPy 数组初始化 1.3 从另一个张量初始化 1.4 使用随机值或常量值初始化 2.张量的属性 3.张量运算 3.1 标准的类似 numpy 的索引和切片: 3.2 连接张量 3.3 算术运算 3.4单元素张量 Single-element tensors 3.5 In-place 操作 4. 张量和NumPy 桥接 4.1 张量到 NumPy 数组 4.2 NumPy 数组到张量 正文 张量是一种特殊的数据结构,与数组
-
Python中字典的基础介绍及常用操作总结
目录 1.字典的介绍 2.访问字典的值 (一)根据键访问值 (二)通过get()方法访问值 3.修改字典的值 4.添加字典的元素(键值对) 5.删除字典的元素 6.字典常见操作 1.len 测量字典中键值对的个数 2. keys 返回一个包含字典所有KEY的列表 3. values 返回一个包含字典所有value的列表 4. items 返回一个包含所有(键,值)元祖的列表 5.遍历字典的key(键) 6.遍历字典的value(值) 7.遍历字典的items(元素) 8.遍历字典的items(键
-
Python中元组的基础介绍及常用操作总结
目录 1.元组的介绍 2.访问元组 3.修改元组(不可以修改的) 4.元组的内置函数有count,index 5.类型转换 1.将元组转换为列表 2.将元组转换为集合 1.元组的介绍 Python的元组与列表类似,不同之处在于元组的元素不能修改. 元组使用小括号,列表使用方括号. 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可. 元组的格式: tup=('a','b','c','d') 2.访问元组 元组可以使用下标索引来访问元组中的值,下标索引从0开始 例如: tup=('a','
-
Python中字符串的基础介绍及常用操作总结
目录 1.字符串的介绍 2.字符串的下标 3.字符串切片 4.字符串find()操作 5.字符串index()操作 6.字符串count()操作 7.字符串replace()操作 8.字符串split()操作 9.字符串startswith()操作 10.字符串endswith()操作 11.字符串upper()操作 12.字符串lower()操作 13.字符串title()操作 14.字符串capitalize()操作 15.字符串strip()操作 16.字符串rfind()操作 17.字符
-
Python学习之基础语法介绍
目录 前言 基础语法 编码 注释 行与缩进 多行语句 import 与 from-import 前言 Python环境的搭建这里就不赘述了,有需要的小伙伴可以在网上搜罗出很多教程,注意安装PyChom编辑工具.这次我们主要讲一下几点内容: 基础语法基本数据类型 首先,我们打开安装好的PyChom编辑工具创建第一个Python程序. 启动PyChom编辑工具后,需要创建一个新项目,选择"New Projec",或者"File ️ New Projec" 命名,可以看到
-
Python面向对象编程基础解析(二)
Python最近挺火呀,比鹿晗薛之谦还要火,当然是在程序员之间.下面我们看看有关Python的相关内容. 上一篇文章我们已经介绍了部分Python面向对象编程基础的知识,大家可以参阅:Python面向对象编程基础解析(一),接下来,我们看看另一篇. 封装 1.为什么要封装? 封装就是要把数据属性和方法的具体实现细节隐藏起来,只提供一个接口.封装可以不用关心对象是如何构建的,其实在面向对象中,封装其实是最考验水平的 2.封装包括数据的封装和函数的封装,数据的封装是为了保护隐私,函数的封装是为了隔离
-
Python面向对象编程基础解析(一)
1.什么是面向对象 面向对象(oop)是一种抽象的方法来理解这个世界,世间万物都可以抽象成一个对象,一切事物都是由对象构成的.应用在编程中,是一种开发程序的方法,它将对象作为程序的基本单元. 2.面向对象与面向过程的区别 我们之前已经介绍过面向过程了,面向过程的核心在'过程'二字,过程就是解决问题的步骤,面向过程的方法设计程序就像是在设计一条流水线,是一种机械式的思维方式 优点:复杂的问题简单化,流程化 缺点:扩展性差 主要应用场景有:Linux内核,git,以及http服务 面向对象的程序设计
-
Python 模块EasyGui详细介绍
Python 模块EasyGui详细介绍 前言: 在Windows想用Python开发一些简单的界面,所以找到了很容易上手的EasyGui库.下面就分享一下简单的使用吧. 参考的链接:官网Tutorial 接下来,我将从简单,到复杂一点点的演示如何使用这个模块.希望能给刚接触easygui的你一点帮助 :-) msgBox,ccbox,ynbox # coding:utf-8 # __author__ = 'Mark sinoberg' # __date__ = '2016/5/25' # __