Python用requests模块实现动态网页爬虫
目录
- 前言
- 开发工具
- 环境搭建
- 总结
前言
Python爬虫实战,requests模块,Python实现动态网页爬虫
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
urllib模块;
random模块;
requests模块;
traceback模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
那我们就开启爬虫的正确姿势吧,先用解析接口的方法来写爬虫。
首先,找到真实请求。右键检查,点击Network,选中XHR,刷新网页,选择Name列表中的jsp文件。没错,就这么简单,真实请求就藏在里面。
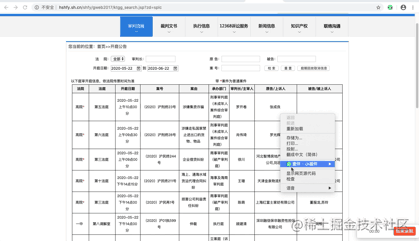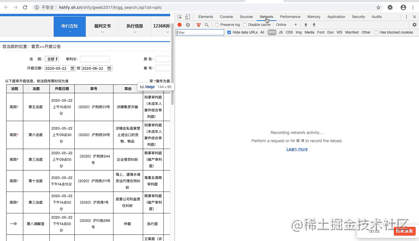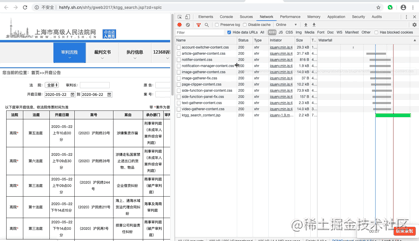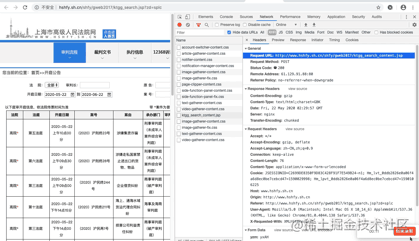
我们再仔细看看这个jsp,这简直是个宝啊。有真实请求url,有请求方法post,有Headers,还有Form Data,而From Data表示给url传递的参数,通过改变参数,咱们就可以获得数据!为了安全,给自个Cookie打了个马赛克
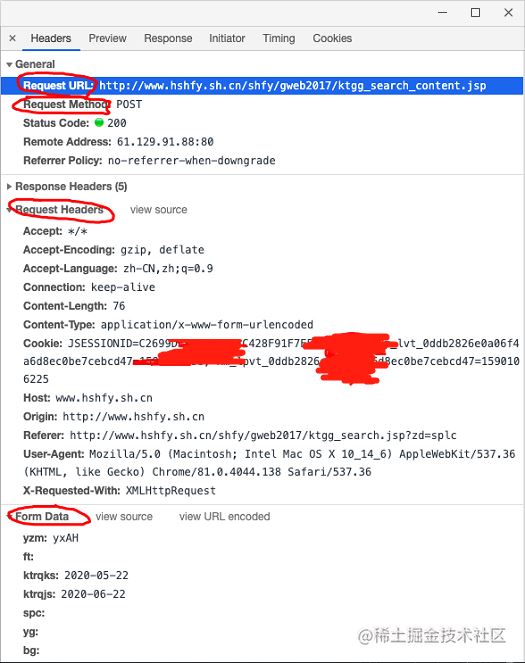
我们尝试点击翻页,发现只有pagesnum参数会变化。

1 from urllib.parse import urlencode 2 import csv 3 import random 4 import requests 5 import traceback 6 from time import sleep 7 from lxml import etree #lxml为第三方网页解析库,强大且速度快
1 base_url = 'http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search_content.jsp?' #这里要换成对应Ajax请求中的链接
2
3 headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search.jsp?zd=splc',
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13 }
构建get_page函数,自变量为page,也就是页数。以字典类型创建表单data,用post方式去请求网页数据。这里要注意要对返回的数据解码,编码为’gbk’,否则返回的数据会乱码!
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构建parse_page函数,对返回的网页数据进行解析,用Xpath提取所有字段内容,保存为csv格式。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
遍历一下页数,调用一下函数
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
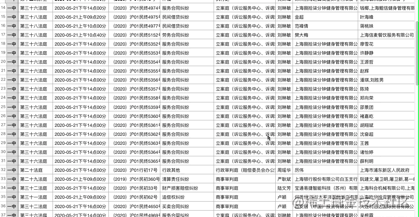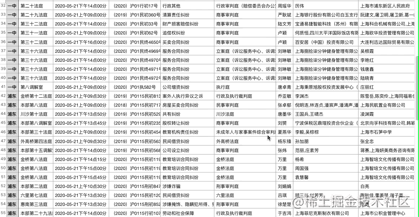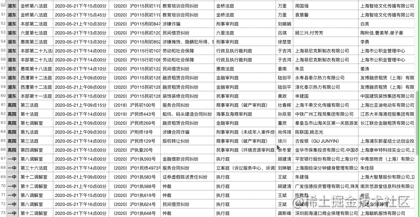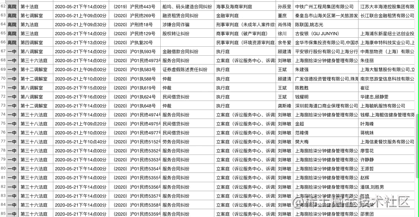
效果:
总结
到此这篇关于Python用requests模块实现动态网页爬虫的文章就介绍到这了,更多相关Python requests内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫之requests库基本介绍
目录 一.说明 二.基本用法: 总结 一.说明 requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多. Requests 有这些功能: 1.Keep-Alive & 连接池2.国际化域名和 URL3.带持久 Cookie 的会话4.浏览器式的 SSL 认证5.自动内容解码6.基本/摘要式的身份认证7.优雅的 key/value Cookie8.自
-

requests.gPython 用requests.get获取网页内容为空 ’ ’问题
目录 一.如何设置headers 1.QQ浏览器 2.Miscrosft edge 二.微软自带浏览器 下面先来看一个例子: import requests result=requests.get("http://data.10jqka.com.cn/financial/yjyg/") result 输出结果: 表示成功处理了请求,一般情况下都是返回此状态码: 报200代表没问题 继续运行,发现返回空值,在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止
-
python爬虫之requests库的使用详解
目录 python爬虫-requests库的用法 基本的get请求 带参数的GET请求: 解析json 使用代理 获取cookie 会话维持 证书验证设置 超时异常捕获 异常处理 总结 python爬虫-requests库的用法 requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求.指定 URL并添加查询url字符串即可开始爬取网页信息等操作 因为是第三方库,所以使用前需要cmd安装 pip install
-
Python用requests模块实现动态网页爬虫
目录 前言 开发工具 环境搭建 总结 前言 Python爬虫实战,requests模块,Python实现动态网页爬虫 让我们愉快地开始吧~ 开发工具 Python版本: 3.6.4 相关模块: urllib模块: random模块: requests模块: traceback模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 那我们就开启爬虫的正确姿势吧,先用解析接口的方法来写爬虫. 首先,找到真实请求.右键检查,点击Networ
-
python使用requests模块实现爬取电影天堂最新电影信息
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到.可以说,Requests 完全满足如今网络的需求.本文重点给大家介绍python使用requests模块实现爬取电影天堂最新电影信息,具体内容如下所示: 在抓取网络数据的时候,有时会用正则对结构化的数据进行提取,比如 href="https://www.1234.com"等.python的re模块的findall()函数会返回一个所有匹配到的内容的列表,在将数据存入数据库时,列表数据
-
浅谈python中requests模块导入的问题
今天使用Pycharm来抓取网页图片时候,要导入requests模块,但是在pycharm中import requests 时候报错. 原因: python中还没有安装requests库 解决办法: 1.先找到自己python安装目录下的pip 2.在自己的电脑里打开cmd窗口. 先点击开始栏,在搜索栏输入cmd,按Enter,打打开cmd窗口.在cmd里将目录切换到你的pip所在路径. 比如我的在C:\Python27\Scripts这个目录下,先切换到d盘,再进入这个路径. 具体命令:cd.
-
python中requests模块的使用方法
本文实例讲述了python中requests模块的使用方法.分享给大家供大家参考.具体分析如下: 在HTTP相关处理中使用python是不必要的麻烦,这包括urllib2模块以巨大的复杂性代价获取综合性的功能.相比于urllib2,Kenneth Reitz的Requests模块更能简约的支持完整的简单用例. 简单的例子: 想象下我们试图使用get方法从http://example.test/获取资源并且查看返回代码,content-type头信息,还有response的主体内容.这件事无论使用
-
Python利用requests模块下载图片实例代码
本文主要介绍的是关于Python利用requests模块下载图片的相关,下面话不多说了,来一起看看详细的介绍吧 MySQL中事先保存好爬取到的图片链接地址. 然后使用多线程把图片下载到本地. 示例代码: # coding: utf-8 import MySQLdb import requests import os import re from threading import Thread import datetime header = {'User-Agent': 'Mozilla/5.0
-
python 使用 requests 模块发送http请求 的方法
Requests具有完备的中英文文档, 能完全满足当前网络的需求, 它使用了urllib3, 拥有其所有的特性! 最近在学python自动化,怎样用python发起一个http请求呢? 通过了解 request 模块可以帮助我们发起http请求 步骤: 1.首先import 下 request 模块 2.然后看请求的方式,选择对应的请求方法 3.接受返回的报文信息 例子:get 方法 import requests url ="https://www.baidu.com" res =
-
Python通过requests模块实现抓取王者荣耀全套皮肤
目录 开发工具 环境搭建 思路分析 代码实现 前言 今天带大家爬取王者荣耀全套皮肤,废话不多说,直接开始~ 开发工具 Python版本: 3.6.4 相关模块: requests模块: urllib模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 思路分析 1.打开官方王者荣耀壁纸网站 网站地址:https://pvp.qq.com/web201605/wallpaper.shtml 2.快捷键F12,调出控制台进行抓包 3.找
-
Python使用requests模块爬取百度翻译
requests模块: python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高. 作用:模拟浏览器发请求. 提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可! requests模块编码流程 指定url 1.1 UA伪装 1.2 请求参数的处理 2.发起请求 3.获取响应数据 4.持久化存储 环境安装: pip install requests 案例一:破解百度翻译(post请求) 1.代码如下: #爬取百度翻
-
Python天气预报采集器实现代码(网页爬虫)
爬虫简单说来包括两个步骤:获得网页文本.过滤得到数据. 1.获得html文本. python在获取html方面十分方便,寥寥数行代码就可以实现我们需要的功能. 复制代码 代码如下: def getHtml(url): page = urllib.urlopen(url) html = page.read() page.close() return html 这么几行代码相信不用注释都能大概知道它的意思. 2.根据正则表达式等获得需要的内容. 使用正则表达式时需要仔细观察该网页信息的结构,并写出正
-
Python 使用requests模块发送GET和POST请求的实现代码
①GET # -*- coding:utf-8 -*- import requests def get(url, datas=None): response = requests.get(url, params=datas) json = response.json() return json 注:参数datas为json格式 ②POST # -*- coding:utf-8 -*- import requests def post(url, datas=None): response = re