PyTorch一小时掌握之autograd机制篇
目录
- 概述
- 代码实现
- 手动定义求导
- 计算流量
- 反向传播计算
- 线性回归
- 导包
- 构造 x, y
- 构造模型
- 参数 & 损失函数
- 训练模型
- 完整代码
概述
PyTorch 干的最厉害的一件事情就是帮我们把反向传播全部计算好了.
代码实现
手动定义求导
import torch # 方法一 x = torch.randn(3, 4, requires_grad=True) # 方法二 x = torch.randn(3,4) x.requires_grad = True
b = torch.randn(3, 4, requires_grad=True) t = x + b y = t.sum() print(y) print(y.backward()) print(b.grad) print(x.requires_grad) print(b.requires_grad) print(t.requires_grad)
输出结果:
tensor(1.1532, grad_fn=<SumBackward0>)
None
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
True
True
True
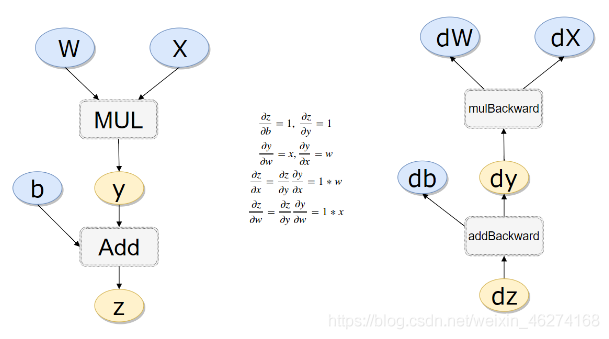
计算流量
# 计算流量 x = torch.rand(1) w = torch.rand(1, requires_grad=True) b = torch.rand(1, requires_grad=True) y = w * x z = y + b print(x.requires_grad, w.requires_grad,b.requires_grad, z.requires_grad) print(x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf,z.is_leaf)
输出结果:
False True True True
True True True False False
反向传播计算
# 反向传播 z.backward(retain_graph= True) # 如果不清空会累加起来 print(w.grad) print(b.grad)
输出结果:
tensor([0.1485])
tensor([1.])
线性回归
导包
import numpy as np import torch import torch.nn as nn
构造 x, y
# 构造数据 X_values = [i for i in range(11)] X_train = np.array(X_values, dtype=np.float32) X_train = X_train.reshape(-1, 1) print(X_train.shape) # (11, 1) y_values = [2 * i + 1 for i in X_values] y_train = np.array(y_values, dtype=np.float32) y_train = y_train.reshape(-1,1) print(y_train.shape) # (11, 1)
输出结果:
(11, 1)
(11, 1)
构造模型
# 构造模型
class LinerRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinerRegressionModel, self).__init__()
self.liner = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.liner(x)
return out
input_dim = 1
output_dim = 1
model = LinerRegressionModel(input_dim, output_dim)
print(model)
输出结果:
LinerRegressionModel(
(liner): Linear(in_features=1, out_features=1, bias=True)
)
参数 & 损失函数
# 超参数 enpochs = 1000 learning_rate = 0.01 # 损失函数 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) criterion = nn.MSELoss()
训练模型
# 训练模型
for epoch in range(enpochs):
# 转成tensor
inputs = torch.from_numpy(X_train)
labels = torch.from_numpy(y_train)
# 梯度每次迭代清零
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
if epoch % 50 == 0:
print("epoch {}, loss {}".format(epoch, loss.item()))
输出结果:
epoch 0, loss 114.47456359863281
epoch 50, loss 0.00021522105089388788
epoch 100, loss 0.00012275540211703628
epoch 150, loss 7.001651829341426e-05
epoch 200, loss 3.9934264350449666e-05
epoch 250, loss 2.2777328922529705e-05
epoch 300, loss 1.2990592040296178e-05
epoch 350, loss 7.409254521917319e-06
epoch 400, loss 4.227155841363128e-06
epoch 450, loss 2.410347860859474e-06
epoch 500, loss 1.3751249525739695e-06
epoch 550, loss 7.844975016269018e-07
epoch 600, loss 4.4756839656656666e-07
epoch 650, loss 2.5517596213830984e-07
epoch 700, loss 1.4577410922811396e-07
epoch 750, loss 8.30393886985803e-08
epoch 800, loss 4.747753479250605e-08
epoch 850, loss 2.709844615367274e-08
epoch 900, loss 1.5436164346738224e-08
epoch 950, loss 8.783858973515635e-09
完整代码
import numpy as np
import torch
import torch.nn as nn
# 构造数据
X_values = [i for i in range(11)]
X_train = np.array(X_values, dtype=np.float32)
X_train = X_train.reshape(-1, 1)
print(X_train.shape) # (11, 1)
y_values = [2 * i + 1 for i in X_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1,1)
print(y_train.shape) # (11, 1)
# 构造模型
class LinerRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinerRegressionModel, self).__init__()
self.liner = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.liner(x)
return out
input_dim = 1
output_dim = 1
model = LinerRegressionModel(input_dim, output_dim)
print(model)
# 超参数
enpochs = 1000
learning_rate = 0.01
# 损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
# 训练模型
for epoch in range(enpochs):
# 转成tensor
inputs = torch.from_numpy(X_train)
labels = torch.from_numpy(y_train)
# 梯度每次迭代清零
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
if epoch % 50 == 0:
print("epoch {}, loss {}".format(epoch, loss.item()))
到此这篇关于PyTorch一小时掌握之autograd机制篇的文章就介绍到这了,更多相关PyTorch autograd内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pytorch 中autograd.grad()函数的用法说明
我们在用神经网络求解PDE时, 经常要用到输出值对输入变量(不是Weights和Biases)求导: 在训练WGAN-GP 时, 也会用到网络对输入变量的求导. 以上两种需求, 均可以用pytorch 中的autograd.grad() 函数实现. autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False
-
浅谈Pytorch中autograd的若干(踩坑)总结
关于Variable和Tensor 旧版本的Pytorch中,Variable是对Tensor的一个封装:在Pytorch大于v0.4的版本后,Varible和Tensor合并了,意味着Tensor可以像旧版本的Variable那样运行,当然新版本中Variable封装仍旧可以用,但是对Varieble操作返回的将是一个Tensor. import torch as t from torch.autograd import Variable a = t.ones(3,requires_grad=
-
pytorch-autograde-计算图的特点说明
在PyTorch实现中,autograd会随着用户的操作,记录生成当前variable的所有操作,并由此建立一个有向无环图.用户每进行一个操作,相应的计算图就会发生改变. 更底层的实现中,图中记录了操作Function,每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到.在反向传播过程中,autograd沿着这个图从当前变量(根节点\textbf{z}z)溯源,可以利用链式求导法则计算所有叶子节点的梯度. 每一个前向传播操作的函数都有与之对应的反向传播函数用来计算输入的各个va
-
PyTorch一小时掌握之autograd机制篇
目录 概述 代码实现 手动定义求导 计算流量 反向传播计算 线性回归 导包 构造 x, y 构造模型 参数 & 损失函数 训练模型 完整代码 概述 PyTorch 干的最厉害的一件事情就是帮我们把反向传播全部计算好了. 代码实现 手动定义求导 import torch # 方法一 x = torch.randn(3, 4, requires_grad=True) # 方法二 x = torch.randn(3,4) x.requires_grad = True b = torch.randn(3
-
PyTorch一小时掌握之神经网络分类篇
目录 概述 导包 设置超参数 读取数据 可视化展示 建立模型 训练模型 完整代码 概述 对于 MNIST 手写数据集的具体介绍, 我们在 TensorFlow 中已经详细描述过, 在这里就不多赘述. 有兴趣的同学可以去看看之前的文章: https://www.jb51.net/article/222183.htm 在上一节的内容里, 我们用 PyTorch 实现了回归任务, 在这一节里, 我们将使用 PyTorch 来解决分类任务. 导包 import torchvision import to
-
PyTorch一小时掌握之迁移学习篇
目录 概述 为什么使用迁移学习 更好的结果 节省时间 加载模型 ResNet152 冻层实现 模型初始化 获取需更新参数 训练模型 获取数据 完整代码 概述 迁移学习 (Transfer Learning) 是把已学训练好的模型参数用作新训练模型的起始参数. 迁移学习是深度学习中非常重要和常用的一个策略. 为什么使用迁移学习 更好的结果 迁移学习 (Transfer Learning) 可以帮助我们得到更好的结果. 当我们手上的数据比较少的时候, 训练非常容易造成过拟合的现象. 使用迁移学习可以
-
PyTorch一小时掌握之图像识别实战篇
目录 概述 预处理 导包 数据读取与预处理 数据可视化 主体 加载参数 建立模型 设置哪些层需要训练 优化器设置 训练模块 开始训练 测试 测试网络效果 测试训练好的模型 测试数据预处理 展示预测结果 概述 今天我们要来做一个进阶的花分类问题. 不同于之前做过的鸢尾花, 这次我们会分析 102 中不同的花. 是不是很上头呀. 预处理 导包 常规操作, 没什么好解释的. 缺模块的同学自行pip -install. import numpy as np import time from matplo
-
PyTorch一小时掌握之神经网络气温预测篇
目录 概述 导包 数据读取 数据预处理 构建网络模型 数据可视化 完整代码 概述 具体的案例描述在此就不多赘述. 同一数据集我们在机器学习里的随机森林模型中已经讨论过. 导包 import numpy as np import pandas as pd import datetime import matplotlib.pyplot as plt from pandas.plotting import register_matplotlib_converters from sklearn.pre
-
PyTorch一小时掌握之基本操作篇
目录 创建数据 torch.empty() torch.zeros() torch.ones() torch.tensor() torch.rand() 数学运算 torch.add() torch.sub() torch.matmul() 索引操作 创建数据 torch.empty() 创建一个空张量矩阵. 格式: torch.empty(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_gr
-
Pytorch中的自动求梯度机制和Variable类实例
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性:Varibale的Tensor本身的.data,对应Tensor的梯度.grad,以及这个Variable是通过什么方式得到的.grad_fn,根据最新消息,在pytorch0.4更新后,torch和torch.autograd.Variab
-
pytorch 中的重要模块化接口nn.Module的使用
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 查看源码 初始化部分: def __init__(self): self._backend = thnn_backend self._parameters = OrderedDict() self._buffers = OrderedDict() self._backward_hooks = Ordered
-
PyTorch 中的傅里叶卷积实现示例
卷积 卷积在数据分析中无处不在.几十年来,它们一直被用于信号和图像处理.最近,它们成为现代神经网络的重要组成部分.如果你处理数据的话,你可能会遇到错综复杂的问题. 数学上,卷积表示为: 尽管离散卷积在计算应用程序中更为常见,但在本文的大部分内容中我将使用连续形式,因为使用连续变量来证明卷积定理(下面讨论)要容易得多.之后,我们将回到离散情况,并使用傅立叶变换在 PyTorch 中实现它.离散卷积可以看作是连续卷积的近似,其中连续函数离散在规则网格上.因此,我们不会为这个离散的案例重新证明卷积定理