go第三方库sqlx操作MySQL及ORM原理
目录
- sqlx实战
- 准备工作
- 编写代码
- 添加引用
- 创建连接
- 增删改查
- 预处理语句
- 数据库事务
- sqlx干了什么
- MustXXX
- NamedXXX
- XXXScan
sqlx是Golang中的一个知名三方库,其为Go标准库database/sql提供了一组扩展支持。使用它可以方便的在数据行与Golang的结构体、映射和切片之间进行转换,从这个角度可以说它是一个ORM框架;它还封装了一系列地常用SQL操作方法,让我们用起来更爽。
sqlx实战
这里以操作MySQL的增删改查为例。
准备工作
先要准备一个MySQL,这里通过docker快速启动一个MySQL 5.7。
docker run -d --name mysql1 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
在MySQL中创建一个名为test的数据库:
CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
数据库中创建一个名为Person的数据库表:
CREATE TABLE test.Person ( Id integer auto_increment NOT NULL, Name VARCHAR(30) NULL, City VARCHAR(50) NULL, AddTime DATETIME NOT NULL, UpdateTime DATETIME NOT NULL, CONSTRAINT Person_PK PRIMARY KEY (Id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
然后创建一个Go项目,安装sqlx:
go get github.com/jmoiron/sqlx
因为操作的是MySQL,还需要安装MySQL的驱动:
go get github.com/go-sql-driver/mysql
编写代码
添加引用
添加sqlx和mysql驱动的引用:
import ( "log" _ "github.com/go-sql-driver/mysql" "github.com/jmoiron/sqlx" )
MySQL的驱动是隐式注册的,并不会在接下来的程序中直接调用,所以这里加了下划线。
创建连接
操作数据库前需要先创建一个连接:
db, err := sqlx.Connect("mysql", "root:123456@tcp(127.0.0.1:3306)/test?charset=utf8mb4&parseTime=true&loc=Local")
if err != nil {
log.Println("数据库连接失败")
}
这个连接中指定了程序要用MySQL驱动,以及MySQL的连接地址、用户名和密码、数据库名称、字符编码方式;这里还有两个参数parseTime和loc,parseTime的作用是让MySQL中时间类型的值可以映射到Golang中的time.Time类型,loc的作用是设置time.Time的值的时区为当前系统时区,不使用这个参数的话保存到的数据库的就是UTC时间,会和北京时间差8个小时。
增删改查
sqlx扩展了DB和Tx,继承了它们原有的方法,并扩展了一些方法,这里主要看下这些扩展的方法。
增加
通用占位符的方式:
insertResult := db.MustExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES (?, ?, ?, ?)", "Zhang San", "Beijing", time.Now(), time.Now())
lastInsertId, _ := insertResult.LastInsertId()
log.Println("Insert Id is ", lastInsertId)
这个表的主键使用了自增的方式,可以通过返回值的LastInsertId方法获取。
命名参数的方式:
insertPerson := &Person{
Name: "Li Si",
City: "Shanghai",
AddTime: time.Now(),
UpdateTime: time.Now(),
}
insertPersonResult, err := db.NamedExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES(:Name, :City, :AddTime, :UpdateTime)", insertPerson)
命名参数的方式是sqlx扩展的,这个方式就是常说的ORM。这里需要注意给struct字段添加上db标签:
type Person struct {
Id int `db:"Id"`
Name string `db:"Name"`
City string `db:"City"`
AddTime time.Time `db:"AddTime"`
UpdateTime time.Time `db:"UpdateTime"`
}
struct中的字段名称不必和数据库字段相同,只需要通过db标签映射正确就行。注意SQL语句中使用的命名参数需要是db标签中的名字。
除了可以映射struct,sqlx还支持map,请看下面这个示例:
insertMap := map[string]interface{}{
"n": "Wang Wu",
"c": "HongKong",
"a": time.Now(),
"u": time.Now(),
}
insertMapResult, err := db.NamedExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES(:n, :c, :a, :u)", insertMap)
再来看看批增加的方式:
insertPersonArray := []Person{
{Name: "BOSIMA", City: "Wu Han", AddTime: time.Now(), UpdateTime: time.Now()},
{Name: "BOSSMA", City: "Xi An", AddTime: time.Now(), UpdateTime: time.Now()},
{Name: "BOMA", City: "Cheng Du", AddTime: time.Now(), UpdateTime: time.Now()},
}
insertPersonArrayResult, err := db.NamedExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES(:Name, :City, :AddTime, :UpdateTime)", insertPersonArray)
if err != nil {
log.Println(err)
return
}
insertPersonArrayId, _ := insertPersonArrayResult.LastInsertId()
log.Println("InsertPersonArray Id is ", insertPersonArrayId)
这里还是采用命名参数的方式,参数传递一个struct数组或者切片就可以了。这个执行结果中也可以获取到最后插入数据的自增Id,不过实测返回的是本次插入的第一条的Id,这个有点别扭,但是考虑到增加多条只获取一个Id的场景似乎没有,所以也不用多虑。
除了使用struct数组或切片,也可以使用map数组或切片,这里就不贴出来了,有兴趣的可以去看文末给出的Demo链接。
删除
删除也可以使用通用占位符和命名参数的方式,并且会返回本次执行受影响的行数,某些情况下可以使用这个数字判断SQL实际有没有执行成功。
deleteResult := db.MustExec("Delete from Person where Id=?", 1)
log.Println(deleteResult.RowsAffected())
deleteMapResult, err := db.NamedExec("Delete from Person where Id=:Id",
map[string]interface{}{"Id": 1})
if err != nil {
log.Println(err)
return
}
log.Println(deleteMapResult.RowsAffected())
修改
Sqlx对修改的支持和删除差不多:
updateResult := db.MustExec("Update Person set City=?, UpdateTime=? where Id=?", "Shanghai", time.Now(), 1)
log.Println(updateResult.RowsAffected())
updateMapResult, err := db.NamedExec("Update Person set City=:City, UpdateTime=:UpdateTime where Id=:Id",
map[string]interface{}{"City": "Chong Qing", "UpdateTime": time.Now(), "Id": 1})
if err != nil {
log.Println(err)
}
log.Println(updateMapResult.RowsAffected())
查询
Sqlx对查询的支持比较多。
使用Get方法查询一条:
getPerson := &Person{}
db.Get(getPerson, "select * from Person where Name=?", "Zhang San")
使用Select方法查询多条:
selectPersons := []Person{}
db.Select(&selectPersons, "select * from Person where Name=?", "Zhang San")
只查询部分字段:
getId := new(int64)
db.Get(getId, "select Id from Person where Name=?", "Zhang San")
selectTowFieldSlice := []Person{}
db.Select(&selectTowFieldSlice, "select Id,Name from Person where Name=?", "Zhang San")
selectNameSlice := []string{}
db.Select(&selectNameSlice, "select Name from Person where Name=?", "Zhang San")
从上可以看出如果只查询部分字段,还可以继续使用struct;特别的只查询一个字段时,使用基本数据类型就可以了。
除了这些高层次的抽象方法,Sqlx也对更低层次的查询方法进行了扩展:
查询单行:
row = db.QueryRowx("select * from Person where Name=?", "Zhang San")
if row.Err() == sql.ErrNoRows {
log.Println("Not found Zhang San")
} else {
queryPerson := &Person{}
err = row.StructScan(queryPerson)
if err != nil {
log.Println(err)
return
}
log.Println("QueryRowx-StructScan:", queryPerson.City)
}
查询多行:
rows, err := db.Queryx("select * from Person where Name=?", "Zhang San")
if err != nil {
log.Println(err)
return
}
for rows.Next() {
rowSlice, err := rows.SliceScan()
if err != nil {
log.Println(err)
return
}
log.Println("Queryx-SliceScan:", string(rowSlice[2].([]byte)))
}
命名参数Query:
rows, err = db.NamedQuery("select * from Person where Name=:n", map[string]interface{}{"n": "Zhang San"})
查询出数据行后,这里有多种映射方法:StructScan、SliceScan和MapScan,分别对应映射后的不同数据结构。
预处理语句
对于重复使用的SQL语句,可以采用预处理的方式,减少SQL解析的次数,减少网络通信量,从而提高SQL操作的吞吐量。
下面的代码展示了sqlx中如何使用stmt查询数据,分别采用了命名参数和通用占位符两种传参方式。
bosima := Person{}
bossma := Person{}
nstmt, err := db.PrepareNamed("SELECT * FROM Person WHERE Name = :n")
if err != nil {
log.Println(err)
return
}
err = nstmt.Get(&bossma, map[string]interface{}{"n": "BOSSMA"})
if err != nil {
log.Println(err)
return
}
log.Println("NamedStmt-Get1:", bossma.City)
err = nstmt.Get(&bosima, map[string]interface{}{"n": "BOSIMA"})
if err != nil {
log.Println(err)
return
}
log.Println("NamedStmt-Get2:", bosima.City)
stmt, err := db.Preparex("SELECT * FROM Person WHERE Name=?")
if err != nil {
log.Println(err)
return
}
err = stmt.Get(&bosima, "BOSIMA")
if err != nil {
log.Println(err)
return
}
log.Println("Stmt-Get1:", bosima.City)
err = stmt.Get(&bossma, "BOSSMA")
if err != nil {
log.Println(err)
return
}
log.Println("Stmt-Get2:", bossma.City)
对于上文增删改查的方法,sqlx都有相应的扩展方法。与上文不同的是,需要先使用SQL模版创建一个stmt实例,然后执行相关SQL操作时,不再需要传递SQL语句。
数据库事务
为了在事务中执行sqlx扩展的增删改查方法,sqlx必然也对数据库事务做一些必要的扩展支持。
tx, err = db.Beginx()
if err != nil {
log.Println(err)
return
}
tx.MustExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES (?, ?, ?, ?)", "Zhang San", "Beijing", time.Now(), time.Now())
tx.MustExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES (?, ?, ?, ?)", "Li Si Hai", "Dong Bei", time.Now(), time.Now())
err = tx.Commit()
if err != nil {
log.Println(err)
return
}
log.Println("tx-Beginx is successful")
上面这段代码就是一个简单的sqlx数据库事务示例,先通过db.Beginx开启事务,然后执行SQL语句,最后提交事务。
如果想要更改默认的数据库隔离级别,可以使用另一个扩展方法:
tx, err = db.BeginTxx(context.Background(), &sql.TxOptions{Isolation: sql.LevelRepeatableRead})
sqlx干了什么
通过上边的实战,基本上就可以使用sqlx进行开发了。为了更好的使用sqlx,我们可以再了解下sqlx是怎么做到上边这些扩展的。
Go的标准库中没有提供任何具体数据库的驱动,只是通过database/sql库定义了操作数据库的通用接口。sqlx中也没有包含具体数据库的驱动,它只是封装了常用SQL的操作方法,让我们的SQL写起来更爽。
MustXXX
sqlx提供两个几个MustXXX方法。
Must方法是为了简化错误处理而出现的,当开发者确定SQL操作不会返回错误的时候就可以使用Must方法,但是如果真的出现了未知错误的时候,这个方法内部会触发panic,开发者需要有一个兜底的方案来处理这个panic,比如使用recover。
这里是MustExec的源码:
func MustExec(e Execer, query string, args ...interface{}) sql.Result {
res, err := e.Exec(query, args...)
if err != nil {
panic(err)
}
return res
}
NamedXXX
对于需要传递SQL参数的方法, sqlx都扩展了命名参数的传参方式。这让我们可以在更高的抽象层次处理数据库操作,而不必关心数据库操作的细节。
这种方法的内部会解析我们的SQL语句,然后从传递的struct、map或者slice中提取命名参数对应的值,然后形成新的SQL语句和参数集合,再交给底层database/sql的方法去执行。
这里摘抄一些代码:
func NamedExec(e Ext, query string, arg interface{}) (sql.Result, error) {
q, args, err := bindNamedMapper(BindType(e.DriverName()), query, arg, mapperFor(e))
if err != nil {
return nil, err
}
return e.Exec(q, args...)
}
NamedExec 内部调用了 bindNamedMapper,这个方法就是用于提取参数值的。其内部分别对Map、Slice和Struct有不同的处理。
func bindNamedMapper(bindType int, query string, arg interface{}, m *reflectx.Mapper) (string, []interface{}, error) {
...
switch {
case k == reflect.Map && t.Key().Kind() == reflect.String:
...
return bindMap(bindType, query, m)
case k == reflect.Array || k == reflect.Slice:
return bindArray(bindType, query, arg, m)
default:
return bindStruct(bindType, query, arg, m)
}
}
以批量插入为例,我们的代码是这样写的:
insertPersonArray := []Person{
{Name: "BOSIMA", City: "Wu Han", AddTime: time.Now(), UpdateTime: time.Now()},
{Name: "BOSSMA", City: "Xi An", AddTime: time.Now(), UpdateTime: time.Now()},
{Name: "BOMA", City: "Cheng Du", AddTime: time.Now(), UpdateTime: time.Now()},
}
insertPersonArrayResult, err := db.NamedExec("INSERT INTO Person (Name, City, AddTime, UpdateTime) VALUES(:Name, :City, :AddTime, :UpdateTime)", insertPersonArray)
经过bindNamedMapper处理后SQL语句和参数是这样的:


这里使用了反射,有些人可能会担心性能的问题,对于这个问题的常见处理方式就是缓存起来,sqlx也是这样做的。
XXXScan
这些Scan方法让数据行到对象的映射更为方便,sqlx提供了StructScan、SliceScan和MapScan,看名字就可以知道它们映射的数据结构。而且在这些映射能力的基础上,sqlx提供了更为抽象的Get和Select方法。
这些Scan内部还是调用了database/sql的Row.Scan方法。
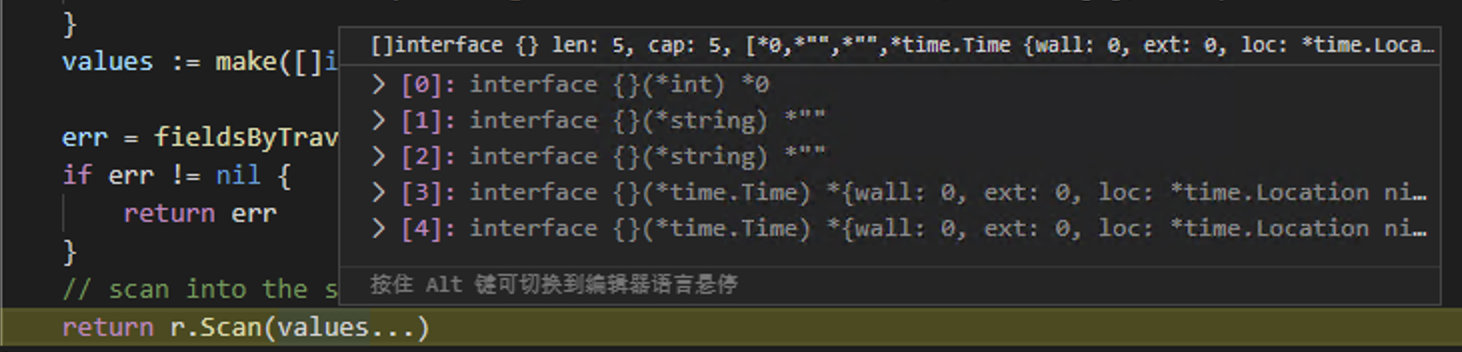
以StructScan为例,其使用方法为:
queryPerson := &Person{}
err = row.StructScan(queryPerson)
经过sqlx处理后,调用Row.Scan的参数是:
以上就是go第三方库sqlx操作MySQL及ORM原理的详细内容,更多关于go sqlx操作MySQLORM的资料请关注我们其它相关文章!
相关推荐
-
golang连接sqlx库的操作使用指南
目录 安装sqlx 基本使用 连接数据库 查询 插入.更新和删除 NamedExec NamedQuery 事务操作 sqlx.In的批量插入示例 表结构 结构体 bindvars(绑定变量) 自己拼接语句实现批量插入 使用sqlx.In实现批量插入 使用NamedExec实现批量插入 sqlx.In的查询示例 in查询 in查询和FIND_IN_SET函数 sqlx库使用指南 在项目中我们通常可能会使用database/sql连接MySQL数据库.本文借助使用sqlx实现批量插入数据的例子,介
-

使用GO语言实现Mysql数据库CURD的简单示例
目录 〇.介绍驱动包和增强版Mysql操作库Sqlx 一.先导入驱动包和增强版Mysql操作库Sqlx 二.insert操作 三.delete操作 四.update操作 五.select操作 〇.介绍驱动包和增强版Mysql操作库Sqlx go-mysql-driver是go语言标准库(SDK)database/sql的"加工产品",质量有保障! go-mysql-driver运行时间虽然比较长,但是内存使用较少. go-mysql-driver实现了database/sql,即便不是
-
Golang 数据库操作(sqlx)和不定字段结果查询
目录 一.Mysql数据库 二.Golang操作Mysql 1. 现有test数据库表格user 2. 连接mysql数据库 2.1. 使用到的第三方库 2.2. 连接 3. SELECT数据库查询操作 4. Insert数据库插入操作 5. Update数据库更新操作 6. DELETE数据库删除操作 三.生成动态字段数据库查询结果 使用的是内置的库 一.Mysql数据库 为什么要使用数据库 一开始人手动记录数据,不能长期保存,追溯: 然后创建了文件系统,能够长期保存,但是查询追溯更新麻烦,数
-
golang实现mysql数据库事务的提交与回滚
MySQL 事务主要用于处理操作量大,复杂度高的数据.在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务. 事务用来管理 insert,update,delete 语句,事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行. 一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性).一致性(Consistency).隔离性(Isolation,又称独立性).持久性(Durability). 本文主要
-
go第三方库sqlx操作MySQL及ORM原理
目录 sqlx实战 准备工作 编写代码 添加引用 创建连接 增删改查 预处理语句 数据库事务 sqlx干了什么 MustXXX NamedXXX XXXScan sqlx是Golang中的一个知名三方库,其为Go标准库database/sql提供了一组扩展支持.使用它可以方便的在数据行与Golang的结构体.映射和切片之间进行转换,从这个角度可以说它是一个ORM框架:它还封装了一系列地常用SQL操作方法,让我们用起来更爽. sqlx实战 这里以操作MySQL的增删改查为例. 准备工作 先要准备一
-
golang常用库之操作数据库的orm框架-gorm基本使用详解
golang常用库:gorilla/mux-http路由库使用 golang常用库:配置文件解析库-viper使用 golang常用库:操作数据库的orm框架-gorm基本使用 一:字段映射-模型定义 gorm中通常用struct来映射字段. gorm教程中叫模型定义 比如我们定义一个模型Model: type User struct { gorm.Model UserId int64 `gorm:"index"` //设置一个普通的索引,没有设置索引名,gorm会自动命名 Birth
-
ORM模型框架操作mysql数据库的方法
[什么是ORM] ORM 全称是(Object Relational Mapping)表示对象关系映射: 通俗理解可以理解为编程语言的虚拟数据库: [理解ORM] 用户地址信息数据库表与对象的映射 [ORM的重要特性] 1.面向对象的编程思想,方便扩充 2. 少写(几乎不写)sql,提升开发效率 3.支持多种类型的数据库(常用的mysql,pg,oracle等等),方便切换 4.ORM技术已经相当成熟,能解决绝大部分问题 [ORM模型框架的选择] [SQLAlchemy ORM模型] 众所周知,
-
SpringBoot实现ORM操作MySQL的几种方法
目录 1.第一种方式:@Mapper 2.第二种方式@MapperScan 3.第三种方式:Mapper文件和Dao接口分开管理 4.事务 使用mybatis框架操作数据,在springboot框架中集成mybatis 使用步骤: mybatis起步依赖:完成mybatis对象自动配置,对象放在容器中. <dependencies> <!-- web起步依赖--> <dependency> <groupId>org.springframework.boot&
-
PHP基于ORM方式操作MySQL数据库实例
本文实例讲述了PHP基于ORM方式操作MySQL数据库.分享给大家供大家参考,具体如下: ORM----Oriented Relationship Mapper,即用面向对象的方式来操作数据库.归根结底,还是对于SQL语句的封装. 首先,我们的数据库有如下一张表: 我们希望能够对这张表,利用setUserid("11111"),即可以设置userid:getUserid()既可以获得对象的userid.所以,我们需要建立model对象,与数据库中的表对应. 由于每张表所对应的model
-
.net core利用orm如何操作mysql数据库详解
前言 众所周知Mysql数据库由于其体积小.速度快.总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库.MySQL是一个多用户.多线程的关系型数据库管理系统. 工作模式是基于客户机/服务器结构.目前它可以支持几乎所有的操作系统. 简单的来说 ,MySql是一个开放的.快速的.多线程的.多用户的SQL数据库服务器. 下面讲解如何在.net core中使用mysql数据库,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 操
-
python 安装移动复制第三方库操作
一.绪论 在使用python开发过程中经常会使用到第三方库.因此就涉及到了如何安装.复制移动. 二.安装方式 第三方库的安装方式 1.python自带包管理器:使用pip命令自动安装.例如:pip install xlwings 2.源码安装:在pypi下载的tar.zip包到本地安装. 2.1.pip安装方式详解 在windows环境先打开cmd命令窗口 进入到python安装路径的Scripts目录 执行pip install 库名字 2.2.源码安装 下载库文件压缩包,并解压. 在cmd命
-
MySQL 数据库的对库的操作及其数据类型
目录 1. 数据库的操作 1.1 显示数据库 1.2 创建数据库 1.3 选中数据库 1.4 删除数据库 2. MySQL 中的数据类型 2.1 数值类型 2.2 字符串类型 2.3 日期类型 1. 数据库的操作 注意: SQL 语句不区分大小写,以下将以小写的语句来演示 每个 SQL 语句后面都要加英文的分号(个别语句不用加分号,但是推荐无脑全加) [] 中括号中的语句是可选的 库名.表名.列名等等不能和关键字相同,如果一定要用关键字为名,则可以通过反引号把名字引起来 1.1 显示数据库 语法
-
MySQL 数据库的对库的操作及其数据类型
目录 1. 数据库的操作 1.1 显示数据库 1.2 创建数据库 1.3 选中数据库 1.4 删除数据库 2. MySQL 中的数据类型 2.1 数值类型 2.2 字符串类型 2.3 日期类型 1. 数据库的操作 注意: SQL 语句不区分大小写,以下将以小写的语句来演示 每个 SQL 语句后面都要加英文的分号(个别语句不用加分号,但是推荐无脑全加) [] 中括号中的语句是可选的 库名.表名.列名等等不能和关键字相同,如果一定要用关键字为名,则可以通过反引号把名字引起来 1.1 显示数据库 语法