pandas.DataFrame.drop_duplicates 用法介绍
如下所示:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据
keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除;last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有两行数据重复,把两行数据都删除,而不是保留其中一行。默认参数是first。
补充知识:python3删除数据重复值,只保留第一项。drop_duplicates()函数使用介绍
原始数据如下:
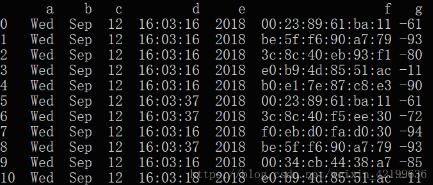
f 列的前3个数据都有重复项,现在要将重复值删去,只保留第一项或最后一项。
使用drop_duplicates()
drop_duplicates(self, subset=None, keep='first', inplace=False)
subset :如['a']代表a列中的重复值全部被删除
keep:保留第一个值,参数为first,last
inplace:是否替换原来的df,默认为False
import pandas as pd
data = pd.read_table("C:/Users/xujinhua/Desktop/aa/a.txt",header=None, names=['a','b','c','d','e','f','g'])
#读取文件数据,并将列命名为abcdef
data.drop_duplicates(subset='f', keep='first', inplace=True)
print(data)
结果:

可以看到 f 列中的重复值都被删除,且保留了第一项
以上这篇pandas.DataFrame.drop_duplicates 用法介绍就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-
利用Pandas来清除重复数据的实现方法
一.前言 最近刚好在练手一个数据挖掘的项目,众所周知,数据挖掘中比较重要的一步为数据清洗,而对重复数据的处理也是数据清洗中经常碰到的一项.本文将仅介绍如何利用Pandas来清除重复数据(主要指重复行),话不多说请看下文. 二.具体介绍 2.1. 导入Pandas库 pandas是python的核心数据分析库,你可以把它理解为python版的excel,倘若你还没有安装相应的库,请查询相关教程进行安装,导入pandas的代码为: import pandas as pd 2.2. DataFrame
-
详解pandas使用drop_duplicates去除DataFrame重复项参数
Pandas之drop_duplicates:去除重复项 方法 DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) 参数 这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行.返回DataFrame格式的数据. subset : column label or sequence of labels, optional 用来指定特定的列,默认所有列 keep : {'firs
-
pandas DataFrame 删除重复的行的实现方法
1. 建立一个DataFrame C=pd.DataFrame({'a':['dog']*3+['fish']*3+['dog'],'b':[10,10,12,12,14,14,10]}) 2. 判断是否有重复项 用duplicated( )函数判断 C.duplicated() 3. 有重复项,则可以用drop_duplicates()移除重复项 C.drop_duplicates() 4. Duplicated( )和drop_duplicates( )方法是以默认的方式判断全部的列(上面
-
pandas.DataFrame.drop_duplicates 用法介绍
如下所示: DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据 keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除:last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有
-

pandas dataframe drop函数介绍
使用drop函数删除dataframe的某列或某行数据: drop(labels, axis=0, level=None, inplace=False, errors='raise') -- axis为0时表示删除行,axis为1时表示删除列 常用参数如下: import pandas as pd import numpy as np data = {'Country':['China','US','Japan','EU','UK/Australia', 'UK/Netherland'], '
-
Python Pandas中DataFrame.drop_duplicates()删除重复值详解
目录 语法 参数 结果展示 扩展:识别重复值 总结 语法 df.drop_duplicates(subset = None, keep = 'first', inplace = False, ignore_index = False) 参数 1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列 2.keep:确定要保留的重复值,有以下可选项: first:保留第一次出现的重复值,默认 last:保留最后一次出现的重复值 False:删除所有重复值 3.inplace:是否
-
Pandas DataFrame求差集的示例代码
在Pandas中 求差集没有专门的函数.处理办法就是将两个DataFrame追加合并,然后去重. divident.append(hasThisYearDivident) noHasThisYearDivident = divident.drop_duplicates(subset='ts_code', keep=False, inplace=True, ignore_index=True) 具体函数用法: https://pandas.pydata.org/pandas-docs/stable
-
pandas dataframe 中的explode函数用法详解
在使用 pandas 进行数据分析的过程中,我们常常会遇到将一行数据展开成多行的需求,多么希望能有一个类似于 hive sql 中的 explode 函数. 这个函数如下: Code # !/usr/bin/env python # -*- coding:utf-8 -*- # create on 18/4/13 import pandas as pd def dataframe_explode(dataframe, fieldname): temp_fieldname = fieldname
-
python pandas dataframe 去重函数的具体使用
今天笔者想对pandas中的行进行去重操作,找了好久,才找到相关的函数 先看一个小例子 from pandas import Series, DataFrame data = DataFrame({'k': [1, 1, 2, 2]}) print data IsDuplicated = data.duplicated() print IsDuplicated print type(IsDuplicated) data = data.drop_duplicates() print data 执行
-
Python Pandas数据分析工具用法实例
1.介绍 Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器.它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列 2.创建DataFrame # -*- encoding=utf-8 -*- import pandas if __name__ == '__main__': pass test_stu = pandas.DataF
-
解析pandas apply() 函数用法(推荐)
目录 Series.apply() apply 函数接收带有参数的函数 DataFrame.apply() apply() 计算日期相减示例 参考 理解 pandas 的函数,要对函数式编程有一定的概念和理解.函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它函数,也能作为函数的返回值. 函数作为对象能带来代码风格的巨大改变.举一个例子,有一个类型为 list 的变量,包含 从 1 到 10 的数据,需
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa