keras绘制acc和loss曲线图实例
我就废话不多说了,大家还是直接看代码吧!
#加载keras模块
from __future__ import print_function
import numpy as np
np.random.seed(1337) # for reproducibility
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD, Adam, RMSprop
from keras.utils import np_utils
import matplotlib.pyplot as plt
%matplotlib inline
#写一个LossHistory类,保存loss和acc
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = {'batch':[], 'epoch':[]}
self.accuracy = {'batch':[], 'epoch':[]}
self.val_loss = {'batch':[], 'epoch':[]}
self.val_acc = {'batch':[], 'epoch':[]}
def on_batch_end(self, batch, logs={}):
self.losses['batch'].append(logs.get('loss'))
self.accuracy['batch'].append(logs.get('acc'))
self.val_loss['batch'].append(logs.get('val_loss'))
self.val_acc['batch'].append(logs.get('val_acc'))
def on_epoch_end(self, batch, logs={}):
self.losses['epoch'].append(logs.get('loss'))
self.accuracy['epoch'].append(logs.get('acc'))
self.val_loss['epoch'].append(logs.get('val_loss'))
self.val_acc['epoch'].append(logs.get('val_acc'))
def loss_plot(self, loss_type):
iters = range(len(self.losses[loss_type]))
plt.figure()
# acc
plt.plot(iters, self.accuracy[loss_type], 'r', label='train acc')
# loss
plt.plot(iters, self.losses[loss_type], 'g', label='train loss')
if loss_type == 'epoch':
# val_acc
plt.plot(iters, self.val_acc[loss_type], 'b', label='val acc')
# val_loss
plt.plot(iters, self.val_loss[loss_type], 'k', label='val loss')
plt.grid(True)
plt.xlabel(loss_type)
plt.ylabel('acc-loss')
plt.legend(loc="upper right")
plt.show()
#变量初始化
batch_size = 128
nb_classes = 10
nb_epoch = 20
# the data, shuffled and split between train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
#建立模型 使用Sequential()
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
#打印模型
model.summary()
#训练与评估
#编译模型
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
#创建一个实例history
history = LossHistory()
#迭代训练(注意这个地方要加入callbacks)
model.fit(X_train, Y_train,
batch_size=batch_size, nb_epoch=nb_epoch,
verbose=1,
validation_data=(X_test, Y_test),
callbacks=[history])
#模型评估
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
#绘制acc-loss曲线
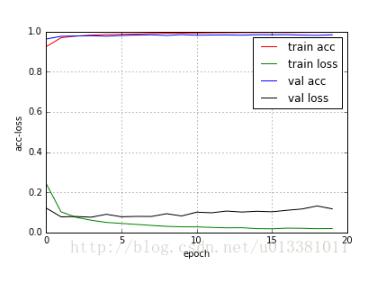
history.loss_plot('epoch')
补充知识:keras中自定义验证集的性能评估(ROC,AUC)
在keras中自带的性能评估有准确性以及loss,当需要以auc作为评价验证集的好坏时,就得自己写个评价函数了:
from sklearn.metrics import roc_auc_score from keras import backend as K # AUC for a binary classifier def auc(y_true, y_pred): ptas = tf.stack([binary_PTA(y_true,y_pred,k) for k in np.linspace(0, 1, 1000)],axis=0) pfas = tf.stack([binary_PFA(y_true,y_pred,k) for k in np.linspace(0, 1, 1000)],axis=0) pfas = tf.concat([tf.ones((1,)) ,pfas],axis=0) binSizes = -(pfas[1:]-pfas[:-1]) s = ptas*binSizes return K.sum(s, axis=0) #------------------------------------------------------------------------------------ # PFA, prob false alert for binary classifier def binary_PFA(y_true, y_pred, threshold=K.variable(value=0.5)): y_pred = K.cast(y_pred >= threshold, 'float32') # N = total number of negative labels N = K.sum(1 - y_true) # FP = total number of false alerts, alerts from the negative class labels FP = K.sum(y_pred - y_pred * y_true) return FP/N #----------------------------------------------------------------------------------- # P_TA prob true alerts for binary classifier def binary_PTA(y_true, y_pred, threshold=K.variable(value=0.5)): y_pred = K.cast(y_pred >= threshold, 'float32') # P = total number of positive labels P = K.sum(y_true) # TP = total number of correct alerts, alerts from the positive class labels TP = K.sum(y_pred * y_true) return TP/P #接着在模型的compile中设置metrics #如下例子,我用的是RNN做分类
from keras.models import Sequential
from keras.layers import Dense, Dropout
import keras
from keras.layers import GRU
model = Sequential()
model.add(keras.layers.core.Masking(mask_value=0., input_shape=(max_lenth, max_features))) #masking用于变长序列输入
model.add(GRU(units=n_hidden_units,activation='selu',kernel_initializer='orthogonal', recurrent_initializer='orthogonal',
bias_initializer='zeros', kernel_regularizer=regularizers.l2(0.01), recurrent_regularizer=regularizers.l2(0.01),
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None,
bias_constraint=None, dropout=0.5, recurrent_dropout=0.0, implementation=1, return_sequences=False,
return_state=False, go_backwards=False, stateful=False, unroll=False))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=[auc]) #写入自定义评价函数
接下来就自己作预测了...
方法二:
from sklearn.metrics import roc_auc_score
import keras
class RocAucMetricCallback(keras.callbacks.Callback):
def __init__(self, predict_batch_size=1024, include_on_batch=False):
super(RocAucMetricCallback, self).__init__()
self.predict_batch_size=predict_batch_size
self.include_on_batch=include_on_batch
def on_batch_begin(self, batch, logs={}):
pass
def on_batch_end(self, batch, logs={}):
if(self.include_on_batch):
logs['roc_auc_val']=float('-inf')
if(self.validation_data):
logs['roc_auc_val']=roc_auc_score(self.validation_data[1],
self.model.predict(self.validation_data[0],
batch_size=self.predict_batch_size))
def on_train_begin(self, logs={}):
if not ('roc_auc_val' in self.params['metrics']):
self.params['metrics'].append('roc_auc_val')
def on_train_end(self, logs={}):
pass
def on_epoch_begin(self, epoch, logs={}):
pass
def on_epoch_end(self, epoch, logs={}):
logs['roc_auc_val']=float('-inf')
if(self.validation_data):
logs['roc_auc_val']=roc_auc_score(self.validation_data[1],
self.model.predict(self.validation_data[0],
batch_size=self.predict_batch_size))
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import GRU
import keras
from keras.callbacks import EarlyStopping
from sklearn.metrics import roc_auc_score
from keras import metrics
cb = [
my_callbacks.RocAucMetricCallback(), # include it before EarlyStopping!
EarlyStopping(monitor='roc_auc_val',patience=300, verbose=2,mode='max')
]
model = Sequential()
model.add(keras.layers.core.Masking(mask_value=0., input_shape=(max_lenth, max_features)))
# model.add(Embedding(input_dim=max_features+1, output_dim=64,mask_zero=True))
model.add(GRU(units=n_hidden_units,activation='selu',kernel_initializer='orthogonal', recurrent_initializer='orthogonal',
bias_initializer='zeros', kernel_regularizer=regularizers.l2(0.01), recurrent_regularizer=regularizers.l2(0.01),
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None,
bias_constraint=None, dropout=0.5, recurrent_dropout=0.0, implementation=1, return_sequences=False,
return_state=False, go_backwards=False, stateful=False, unroll=False)) #input_shape=(max_lenth, max_features),
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=[auc]) #这里就可以写其他评估标准
model.fit(x_train, y_train, batch_size=train_batch_size, epochs=training_iters, verbose=2,
callbacks=cb,validation_split=0.2,
shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
亲测有效!
以上这篇keras绘制acc和loss曲线图实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
keras 自定义loss损失函数,sample在loss上的加权和metric详解
首先辨析一下概念: 1. loss是整体网络进行优化的目标, 是需要参与到优化运算,更新权值W的过程的 2. metric只是作为评价网络表现的一种"指标", 比如accuracy,是为了直观地了解算法的效果,充当view的作用,并不参与到优化过程 在keras中实现自定义loss, 可以有两种方式,一种自定义 loss function, 例如: # 方式一 def vae_loss(x, x_decoded_mean): xent_loss = objectives.binary_
-
Keras之自定义损失(loss)函数用法说明
在Keras中可以自定义损失函数,在自定义损失函数的过程中需要注意的一点是,损失函数的参数形式,这一点在Keras中是固定的,须如下形式: def my_loss(y_true, y_pred): # y_true: True labels. TensorFlow/Theano tensor # y_pred: Predictions. TensorFlow/Theano tensor of the same shape as y_true . . . return scalar #返回一个标量
-
如何通过python画loss曲线的方法
1. 首先导入一些python画图的包,读取txt文件,假设我现在有两个模型训练结果的records.txt文件 import numpy as np import matplotlib.pyplot as plt import pylab as pl from mpl_toolkits.axes_grid1.inset_locator import inset_axes data1_loss =np.loadtxt("valid_RCSCA_records.txt") data2_l
-
keras中的loss、optimizer、metrics用法
用keras搭好模型架构之后的下一步,就是执行编译操作.在编译时,经常需要指定三个参数 loss optimizer metrics 这三个参数有两类选择: 使用字符串 使用标识符,如keras.losses,keras.optimizers,metrics包下面的函数 例如: sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='categorical_crossentropy', opt
-
keras绘制acc和loss曲线图实例
我就废话不多说了,大家还是直接看代码吧! #加载keras模块 from __future__ import print_function import numpy as np np.random.seed(1337) # for reproducibility import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers.core import Dense,
-
在tensorflow下利用plt画论文中loss,acc等曲线图实例
直接上代码: fig_loss = np.zeros([n_epoch]) fig_acc1 = np.zeros([n_epoch]) fig_acc2= np.zeros([n_epoch]) for epoch in range(n_epoch): start_time = time.time() #training train_loss, train_acc, n_batch = 0, 0, 0 for x_train_a, y_train_a in minibatches(x_trai
-
利用Tensorboard绘制网络识别准确率和loss曲线实例
废话不多说,直接上代码看吧! import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #载入数据集 mnist = input_data.read_data_sets("MNIST_data",one_hot=True) #每个批次的大小和总共有多少个批次 batch_size = 100 n_batch = mnist.train.num_examples // batch_
-

Python绘制3d螺旋曲线图实例代码
Line plots Axes3D.plot(xs, ys, *args, **kwargs) 绘制2D或3D数据 参数 描述 xs, ys X轴,Y轴坐标定点 zs Z值,每一个点的值都是1 zdir 绘制2D集合时使用z的方向 其他的参数:plot() Python代码: import matplotlib as mpl from mpl_toolkits.mplot3d import Axes3D import numpy as np import matplotlib.pyplot as
-
pytorch绘制并显示loss曲线和acc曲线,LeNet5识别图像准确率
我用的是Anaconda3 ,用spyder编写pytorch的代码,在Anaconda3中新建了一个pytorch的虚拟环境(虚拟环境的名字就叫pytorch). 以下内容仅供参考哦~~ 1.首先打开Anaconda Prompt,然后输入activate pytorch,进入pytorch. 2.输入pip install tensorboardX,安装完成后,输入python,用from tensorboardX import SummaryWriter检验是否安装成功.如下图所示: 3.
-
使用Keras构造简单的CNN网络实例
1. 导入各种模块 基本形式为: import 模块名 from 某个文件 import 某个模块 2. 导入数据(以两类分类问题为例,即numClass = 2) 训练集数据data 可以看到,data是一个四维的ndarray 训练集的标签 3. 将导入的数据转化我keras可以接受的数据格式 keras要求的label格式应该为binary class matrices,所以,需要对输入的label数据进行转化,利用keras提高的to_categorical函数 label = np_u
-
在Keras中CNN联合LSTM进行分类实例
我就废话不多说,大家还是直接看代码吧~ def get_model(): n_classes = 6 inp=Input(shape=(40, 80)) reshape=Reshape((1,40,80))(inp) # pre=ZeroPadding2D(padding=(1, 1))(reshape) # 1 conv1=Convolution2D(32, 3, 3, border_mode='same',init='glorot_uniform')(reshape) #model.add(
-
IOS开发之为视图绘制单(多)个圆角实例代码
IOS开发之为视图绘制单(多)个圆角实例代码 前言: 为视图绘制圆角,圆角可以选左上角.左下角.右下角.右上角.全部圆角 //Core Raduias UIView *actionView = [[UIView alloc]initWithFrame:CGRectMake(0, 0, 200, 200)]; UIBezierPath *maskPath = [UIBezierPath bezierPathWithRoundedRect:actionView.bounds byRoundingCo
-
JavaScript使用atan2来绘制箭头和曲线的实例
最近搞Canvas绘图,知道了JavaScript中提供了atan2(y,x)这样一个三角函数.乍眼一看,不认识,毕竟在高中时,学过的三角函数有:sin,cos,arcsin,arccos,tan,arctan等,并没有这个.而工作中又需要用到它,所以这里就做了个简单的了解. 在坐标系中理解tan 和 atan 回顾一下三角函数tan: tanθ,用三角函数来表示时,它的值等于sinθ/cosθ,如果将其放到坐标系中,它的的值等价于:dy/dx.在坐标系中,任意两个点所组成的直线,相对于x轴的斜
-
python+pillow绘制矩阵盖尔圆简单实例
本文主要研究的是使用Python+pillow绘制矩阵盖尔圆的一个实例,具体如下. 盖尔圆是矩阵特征值估计时常用的方法之一,其定义为: 与盖尔圆有关的两个定理为: 定理1:矩阵A的所有特征值均落在它的所有盖尔圆的并集之中. 定理2:将矩阵A的全体盖尔圆的并集按连通部分分成若干个子集,(一个子集由完全连通的盖尔圆组成,不同子集没有相连通的部分),对每个子集,若它恰好由K个盖尔圆组成,则该子集中恰好包含A的K个特征值. 与盖尔圆定理有关的几个推论为: 推论1:孤立盖尔圆中恰好包含一个特征值. 推论2