YOLOV5超参数介绍以及优化策略
目录
- yaml文件
- 超参数
- 优化策略
- 总结
yaml文件
模型深度&宽度
nc: 3 # 类别数量 depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple
depth_multiple:控制子模块数量=int(number*depth)
width_multiple:控制卷积核的数量=int(number*width)
Anchor
anchors: - [10,13, 16,30, 33,23] # P3/8,检测小目标,10,13是一组尺寸,总共三组检测小目标 - [30,61, 62,45, 59,119] # P4/16,检测中目标,共三组 - [116,90, 156,198, 373,326] # P5/32,检测大目标,共三组
该anchor尺寸是为输入图像640×640分辨率预设的,实现了即可以在小特征图(feature map)上检测大目标,也可以在大特征图上检测小目标。三种尺寸的特征图,每个特征图上的格子有三个尺寸的anchor。
Backbone
backbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, C3, [1024, False]], # 9 ]
具体解释如下:
from:输入来自那一层,-1代表上一次,1代表第1层,3代表第3层
number:模块的数量,最终数量需要乘width,然后四舍五入取整,如果小于1,取1。
module:子模块
args:模块参数,channel,kernel_size,stride,padding,bias等
Focus:对特征图进行切片操作,[64,3]得到[3,32,3],即输入channel=3(RGB),输出为640.5(width_multiple)=32,3为卷积核尺寸。
Conv:nn.conv(kenel_size=1,stride=1,groups=1,bias=False) + Bn + Leaky_ReLu。[-1, 1, Conv, [128, 3, 2]]:输入来自上一层,模块数量为1个,子模块为Conv,网络中最终有1280.5=32个卷积核,卷积核尺寸为3,stride=2,。
BottleNeckCSP:借鉴CSPNet网络结构,由3个卷积层和X个残差模块Concat组成,若有False,则没有残差模块,那么组成结构为nn.conv+Bn+Leaky_ReLu
SPP:[-1, 1, SPP, [1024, [5, 9, 13]]]表示5×5,9×9,13×13的最大池化方式,进行多尺度融合。源代码如下:
k = [5, 9, 13] self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
Head
head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], 上采样 [[-1, 6], 1, Concat, [1]], # cat backbone P4 代表concat上一层和第6层 [-1, 3, C3, [512, False]], # 13 说明该层是第13层网络 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5),[17, 20, 23]说明输入来自第17,20,23层
YOLOv5中的Head包括Neck和Detect_head两部分。Neck采用了PANet机构,Detect结构和YOLOv3中的Head一样。其中BottleNeckCSP带有False,说明没有使用残差结构,而是采用的backbone中的Conv。
超参数
初始化超参
YOLOv5的超参文件见data/hyp.finetune.yaml(适用VOC数据集)或者hyo.scrach.yaml(适用COCO数据集)文件
lr0: 0.01 # 初始学习率 (SGD=1E-2, Adam=1E-3) lrf: 0.2 # 循环学习率 (lr0 * lrf) momentum: 0.937 # SGD momentum/Adam beta1 学习率动量 weight_decay: 0.0005 # 权重衰减系数 warmup_epochs: 3.0 # 预热学习 (fractions ok) warmup_momentum: 0.8 # 预热学习动量 warmup_bias_lr: 0.1 # 预热初始学习率 box: 0.05 # iou损失系数 cls: 0.5 # cls损失系数 cls_pw: 1.0 # cls BCELoss正样本权重 obj: 1.0 # 有无物体系数(scale with pixels) obj_pw: 1.0 # 有无物体BCELoss正样本权重 iou_t: 0.20 # IoU训练时的阈值 anchor_t: 4.0 # anchor的长宽比(长:宽 = 4:1) # anchors: 3 # 每个输出层的anchors数量(0 to ignore) #以下系数是数据增强系数,包括颜色空间和图片空间 fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5) hsv_h: 0.015 # 色调 (fraction) hsv_s: 0.7 # 饱和度 (fraction) hsv_v: 0.4 # 亮度 (fraction) degrees: 0.0 # 旋转角度 (+/- deg) translate: 0.1 # 平移(+/- fraction) scale: 0.5 # 图像缩放 (+/- gain) shear: 0.0 # 图像剪切 (+/- deg) perspective: 0.0 # 透明度 (+/- fraction), range 0-0.001 flipud: 0.0 # 进行上下翻转概率 (probability) fliplr: 0.5 # 进行左右翻转概率 (probability) mosaic: 1.0 # 进行Mosaic概率 (probability) mixup: 0.0 # 进行图像混叠概率(即,多张图像重叠在一起) (probability)
训练超参
训练超参数包括:yaml文件的选择,和训练图片的大小,预训练,batch,epoch等。
可以直接在train.py的parser中修改,也可以在命令行执行时修改,如:$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights ‘’ --batch-size 64
–data指定训练数据文件 --cfg设置网络结构的配置文件 –weihts加载预训练模型的路径
优化策略
1)数增强策略
从数据角度,我们通过粘贴、裁剪、mosaic、仿射变换、颜色空间转换等对样本进行增强,增加目标多样性,以提升模型的检测与分类精度。
2)SAM优化器
SAM优化器[4]可使损失值和损失锐度同时最小化,并可以改善各种基准数据集(例如CIFAR-f10、100g,ImageNet,微调任务)和模型的模型泛化能力,从而产生了多种最新性能。另外, SAM优化器具有固有的鲁棒性。
经实验对比,模型进行优化器梯度归一化和采用SAM优化器,约有0.027点的提升。
3)Varifocal Loss损失函数
Varifocal Loss主要训练密集目标检测器使IOU感知的分类得分(IASC)回归,来提高检测精度。而目标遮挡是密集目标的特征之一,因此尝试使用该loss来缓解目标遮挡造成漏检现象。并且与focal loss不同,varifocal loss是不对称对待正负样本所带来的损失。
4)冻结训练
在训练过程中采取常规训练与冻结训练想相结合的方式迭代,进一步抑制训练过程中容易出现的过拟合现象,具体训练方案是:1)常规训练;2)加入冻结模块的分步训练1;3)加入冻结模块的分步训练2。
我们详细讲解以上步骤。第一步:从训练数据中随机选取一半,进行yolov5常规训练,该过程中所有的参数是同时更新的。具体流程如下:
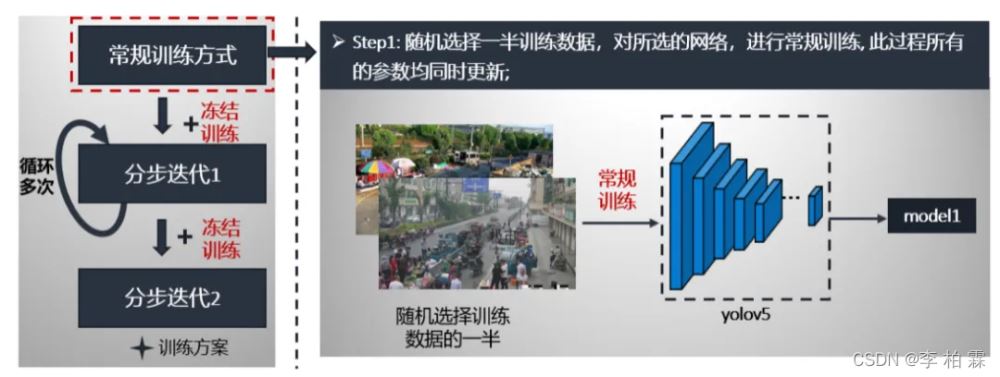
第二步分布迭代1就是采用的冻结模块进行,数据是随机选取训练数据的一半,预训练模型是第一步常规训练的最好模型,按照冻结训练方式进行训练。这个流程循环多次,获得model2。
第三步分布迭代2同样采用的是冻结模块进行,数据是所有训练数据,由于参数已经学过,这时我们将学习率调小一个量级,同样也是按照冻结训练方式进行训练。这个流程只循环一次,获得最终的模型。
两步的具体流程如下:

5)训练时间优化
最初我们直接采用yolov5训练,这种数据加载方式是以张为单位,基于像素的访问,但是训练时速度很慢,可能受其他线程影响造成的,大概一轮要40分钟左右。然后我们就尝试了cache这种方式,它是将所有训练数据存入到内存中,我们以6406403的输入图像为例,占道数据总共有10147张,全部读进去大约占11.6G的内存,平台是提供12G的内存,几乎将内存占满,也会导致训练变慢;于是我们就尝试改进训练读取数据方式,我们采用的是cache+图像编解码的方式,内存占用仅是cache的1/6,由于添加了编解码,速度比cache慢点,但从数据比较来看,相差无几。这样既能节省内存又能加快训练速度。节省了我们训练过程的极力值和加快实验的步伐。
总结
到此这篇关于YOLOV5超参数介绍以及优化策略的文章就介绍到这了,更多相关YOLOV5超参数及优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

yolov5训练时参数workers与batch-size的深入理解
目录 yolov5训练命令 workers和batch-size参数的理解 workers batch-size 两个参数的调优 总结 yolov5训练命令 python .\train.py --data my.yaml --workers 8 --batch-size 32 --epochs 100 yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了.这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字. worke
-
YOLOV5超参数介绍以及优化策略
目录 yaml文件 超参数 优化策略 总结 yaml文件 模型深度&宽度 nc: 3 # 类别数量 depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple depth_multiple:控制子模块数量=int(number*depth) width_multiple:控制卷积核的数量=int(number*width) Anchor anchors: - [10,13, 1
-
使用TensorBoard进行超参数优化的实现
在本文中,我们将介绍超参数优化,然后使用TensorBoard显示超参数优化的结果. 深度神经网络的超参数是什么? 深度学习神经网络的目标是找到节点的权重,这将帮助我们理解图像.文本或语音中的数据模式. 要做到这一点,可以使用为模型提供最佳准度和精度的值来设计神经网络参数. 那么,这些被称为超参数的参数是什么呢? 用于训练神经网络模型的不同参数称为超参数.这些超参数像旋钮一样被调优,以提高神经网络的性能,从而产生一个优化的模型.超参数的一个通俗的解释是:用来优化参数的参数. 神经网络中的一些超参
-
python超参数优化的具体方法
1.手动调参,但这种方法依赖于大量的经验,而且比较费时. 许多情况下,工程师依靠试错法手工调整超参数进行优化,有经验的工程师可以在很大程度上判断如何设置超参数,从而提高模型的准确性. 2.网格化寻优,是最基本的超参数优化方法. 利用这种技术,我们只需要为所有超参数的可能性建立一个独立的模型,评估每个模型的性能,选择产生最佳结果的模型和超参数. from sklearn.datasets import load_iris from sklearn.svm import SVC iris = loa
-
Python实现随机森林RF模型超参数的优化详解
目录 1 代码分段讲解 1.1 数据与模型准备 1.2 超参数范围给定 1.3 超参数随机匹配择优 1.4 超参数遍历匹配择优 1.5 模型运行与精度评定 2 完整代码 本文介绍基于Python的随机森林(Random Forest,RF)回归代码,以及模型超参数(包括决策树个数与最大深度.最小分离样本数.最小叶子节点样本数.最大分离特征数等)自动优化的代码. 本文是在上一篇文章Python实现随机森林RF并对比自变量的重要性的基础上完成的,因此本次仅对随机森林模型超参数自动择优部分的代码加以详
-
webpack4.0打包优化策略整理小结
本文介绍了webpack4.0打包优化策略整理小结,分享给大家,具体如下: webapck4 新特性介绍-参考资料 当前依赖包的版本 1.优化loader配置 1.1 缩小文件匹配范围(include/exclude) 通过排除node_modules下的文件 从而缩小了loader加载搜索范围 高概率命中文件 module: { rules: [ { test: /\.js$/, use: 'babel-loader', exclude: /node_modules/, // 排除不处理的目录
-
OpenCV python sklearn随机超参数搜索的实现
本文介绍了OpenCV python sklearn随机超参数搜索的实现,分享给大家,具体如下: """ 房价预测数据集 使用sklearn执行超参数搜索 """ import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os import sys import tens
-
详解Android内存优化策略
目录 前言 一.内存优化策略 二.具体优化的点 1.避免内存泄漏 2.Bitmap等大对象的优化策略 (1) 优化Bitmap分辨率 (2) 优化单个像素点内存 (3) Bitmap的缓存策略 (4) drawable资源选择合适的drawable文件夹存放 (5) 其他大对象的优化 (6) 避免内存抖动 3.原生API回调释放内存 4.内存排查工具 (1)LeakCanary监测内存泄漏 (2)通过Proflier监控内存 (3)通过MAT工具排查内存泄漏 总结 前言 在开始之前需要先搞明白一
-
实践讲解SpringBoot自定义初始化Bean+HashMap优化策略模式
策略模式:定义了算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户. 传统的策略模式一般是创建公共接口.定义公共方法-->然后创建实体类实现公共接口.根据各自的逻辑重写公共方法-->创建一个行为随着策略对象改变而改变的 context 对象-->根据不同的传参,调用不同的接口实现类方法,达到只改变参数即可获得不同结果的目的. 但是也可以明显发现,这种策略模式的实现方式,代码量较大,而且还要自定义要传递的参数,可能会引入一定数量的if/else,有一定的优
-
Oracle数据库优化策略总结篇
为了提高查询效率,我们常常做一些优化策略.本文主要介绍一些Oracle数据库的一些不常见却是非常有用的优化策略,希望能对您有所帮助. SQL语句优化 这个好办,抓到挪借CPU高的SQL语句,依据索引.SQL技巧等修改一下,行之管用. SELECT时不利用函数 在做频繁的查询垄断时,尽量直接select字段名,然后利用C语言代码对查询收获做二次加工,避免让Oracle来做混杂的函数可能数学计算.因为Oracle出于通用性的琢磨,其函数及数学计算的速度远不及用C语言直接编译成机器码后计算来的快. 绑
-
PHP数据库编程之MySQL优化策略概述
本文简单讲述了PHP数据库编程之MySQL优化策略.分享给大家供大家参考,具体如下: 前些天看到一篇文章说到PHP的瓶颈很多情况下不在PHP自身,而在于数据库.我们都知道,PHP开发中,数据的增删改查是核心.为了提升PHP的运行效率,程序员不光需要写出逻辑清晰,效率很高的代码,还要能对query语句进行优化.虽然我们对数据库的读取写入速度上却是无能为力,但在一些数据库类扩展像memcache.mongodb.redis这样的数据存储服务器的帮助下,PHP也能达到更快的存取速度,所以了解学习这些扩