GoLang string类型深入分析
目录
- 并发不安全
- 竞态竞争
- 字符串优化
文章运行环境:go version go1.16.6 darwin/amd64
并发不安全
看下面的代码,大家觉得会输出什么?大多数人应该都会觉得输出""、abc、neoj 这三种情况,但真实的情况并不是这样,真实情况是只输出 “” 空字符串。
结合日常的工作,类似这种并发操作同一个变量的情况也比较常见,为什么业务没有发生异常问题?
var name string = ""
func main() {
go func() {
for {
name = "abc"
}
}()
go func() {
for {
name = "neoj"
}
}()
for {
fmt.Println(name)
}
}
1.14 之后引入了 G 抢占式调度,那为什么代码中的两个协程没有执行呢?其实是编译器做了优化,这两个协程被省略掉了。
我们对代码做一点调整,在协程中加一行空的输出,输出结果中出现了一些特例,比如:neo、abca。其中,neo 字符串长度等于 abc 的长度,而 abca 的长度等于 neoj 的长度。
var name string = ""
func main() {
go func() {
for {
name = "abc"
fmt.Printf("")
}
}()
go func() {
for {
name = "neoj"
fmt.Printf("")
}
}()
for {
if name != "abc" && name != "neoj" {
fmt.Println(name)
}
}
}
例子说明,string 的赋值并不是原子的。
Go 语言中 string 的内存结果如下,它包含两部分:Data 表示实际的数据部分,而 Len 表示字符串的长度。
所以,通过方法 len 来计算字符串的长度并不会有性能开销,len 方法会直接返回结构体的 Len 属性;而传递字符串类型的参数,使用指针类型和值类型,性能上也不会有太大差别。
type StringHeader struct {
Data uintptr
Len int
}
字符串的并发不安全,主要就是给这两个字段的赋值,没有办法保证原子性。参考 runtime/string.go 中的源码,我们可以了解字符串生成过程。
并发赋值的情况下,Data 指向的地址和 Len 无法保证一一对应。所以,通过 Data 获取到内存的首地址,通过 Len 去读取指定长度的内存时,就会出现内存读取异常的情况。
func rawstring(size int) (s string, b []byte) {
p := mallocgc(uintptr(size), nil, false)
stringStructOf(&s).str = p
stringStructOf(&s).len = size
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}
rawstring 函数在字符串拼接的时候被调用,我们代码中创建一个字符串类型,每次都生成一份新的内存空间。特别强调,创建和字符串赋值需要区分开来。赋值的过程其实是值拷贝,拷贝的便是 StringHeader 结构体。
var name string = ""
func main() {
blog := name
fmt.Println(blog)
}
上面的变量 blog 是 name 的值拷贝,底层指向的字符串是同一块内存空间。这个赋值过程中,发生拷贝的只是外层的 StringHeader 对象。
Go 中通过 unsafe 包可以强制对内存数据做类型转换,我们将 blog 和 name 的内存地址打印出来比较一下。最终打印输出两个变量的地址和Data地址。可以看出,赋值前后,Data指向的地址并没有发生变化。
type StringHeader struct {
Data uintptr
Len int
}
var name string = "g"
func main() {
blog := name
n := (*StringHeader)(unsafe.Pointer(&name))
b := (*StringHeader)(unsafe.Pointer(&blog))
fmt.Println(&n, n.Data) // 0xc00018a020 17594869
fmt.Println(&b, b.Data) // 0xc00018a028 17594869
}
string 并发不安全读写,会导致线上服务偶发 panic。比如使用 json 对内存异常的 string 做序列化的时候。下面的例子中,其中一个协程用来赋值为空,非常容易复现 panic。
type People struct {
Name string
}
var p *People = new(People)
func main() {
go func() {
for {
p.Name = ""
}
}()
go func() {
for {
p.Name = "neoj"
}
}()
for {
_, _ = json.Marshal(p)
}
}
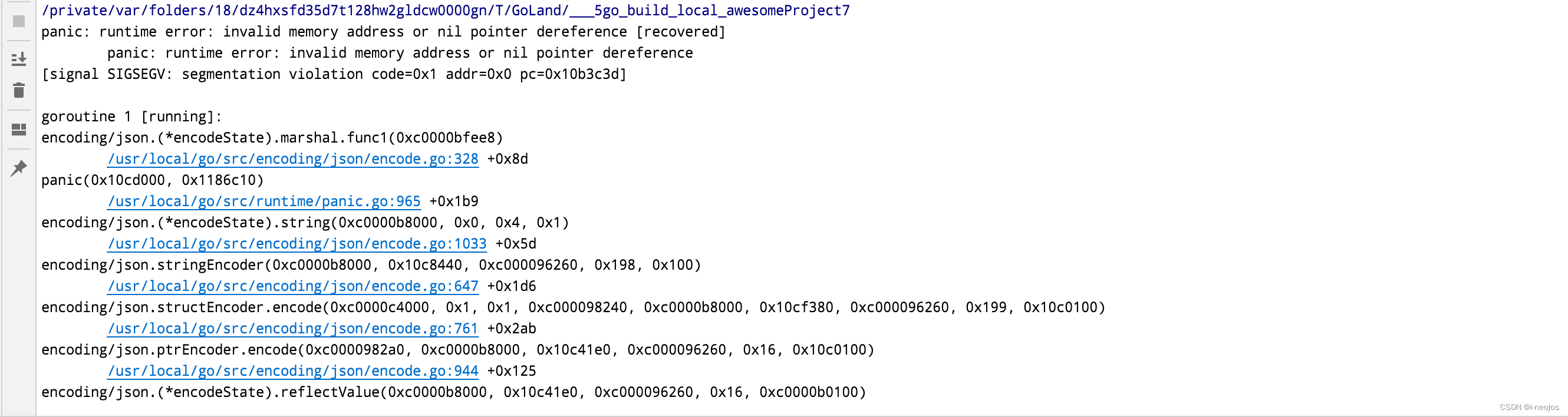
下面是 panic 的堆栈信息,空字符串的 Data 指向的是 nil 的地址,而并发导致 Len 字段有值,最终导致发生 panic。
竞态竞争
对同一个变量并发读写,如果没有使用辅助的同步操作,就会出现不符合预期的情况。直白的讲,我们开发完一个程序之后,针对同样的输入,会输出什么结果,我们是不确定的。
可以参考 The Go Memory Model 的介绍,强调一下数据竞争的概念:
A data race is defined as a write to a memory location happening concurrently with another read or write to that same location, unless all the accesses involved are atomic data accesses as provided by the sync/atomic package
幸运的是,Go 已经集成了现成的工具来诊断数据竞争:-race。在 go build、或者直接执行的时候,指定 -race 属性,系统会做数据竞争检测,并打印输出。
以最近的代码为例,如果你使用的也是 goland 编译器,只需要在 Run Configurations / Go tool arguments 中指定 -race 属性,运行程序,就会出现下面的检测结果:

面对生产环境,-race 有比较严重的性能开销,我们最好是开发环境做竞态检测。
-race 是通过编译器注入代码来执行检测的,在函数执行前、执行后都会做内存统计。也就是说:只有被执行到的代码才能被检测到。所以,如果开发阶段做竞态检测的话,一定要保证代码被执行到了。
再加上埋点的内存统计也是有策略的,也不可能保证存在数据竞争的代码就一定会被检测出来,最好可以多执行几次来避免这种情况。
字符串优化
因字符串并发读写导致的 panic,很容易被 Go 的字符串优化带偏。
我在第一次遇到这种情况的时候,想到的居然是:会不会是底层优化导致的。因为发生 panic 的代码用到了 map 的数据结构。这种想法很快被我用测试用例排除了。
[]byte 到 string 类型转换是比较常规的操作,正常情况下,转换都会申请了一份新的内存空间。但 Go 为了提高性能,在某些场景下 string 和 []byte 会共用一份内存空间,这种场景下也能写乱内存。
// slicebytetostringtmp returns a "string" referring to the actual []byte bytes.
//
func slicebytetostringtmp(ptr *byte, n int) (str string) {
if raceenabled && n > 0 {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostringtmp))
}
if msanenabled && n > 0 {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
stringStructOf(&str).str = unsafe.Pointer(ptr)
stringStructOf(&str).len = n
return
}
程序中出现问题,还是要先充分审查自己开发的代码
到此这篇关于GoLang string类型深入分析的文章就介绍到这了,更多相关Go string内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

go语言数据类型之字符串string
1.Go语言String的本质就是一个[]byte,所以他们之间可以互相转换,byte数组的长度就是字符串的长度. func StringTest1() { str := "Hello,World" a := str[0] b := str[1] fmt.Printf("a=%c\n", a) fmt.Printf("b=%c\n", b) } 结果 a=H b=e str=Mello,World 2.字符串的值一旦指定,就不能进行修改.如果想修
-
Golang中字符串(string)与字节数组([]byte)一行代码互转实例
目录 一.字符串与字节数组? 二.详细代码 1.简单的方式字节转字符串 2.简单的字符串转字节数组 3.字节转字符串 4.字符串转字节数组 5.完整运行测试 补充:一些结论如下 总结 一.字符串与字节数组? 字符串是 Go 语言中最常用的基础数据类型之一,本质上是只读的字符型数组,虽然字符串往往都被看做是一个整体,但是实际上字符串是一片连续的内存空间. Go 语言中另外一个类型字节(Byte).在ASCII中,一个英文字母占一个字节的空间,一个中文汉字占两个字节的空间.英文标点占一个字节,中文标
-
Golang基础教程之字符串string实例详解
目录 1. string的定义 2.string不可变 3.使用string给另一个string赋值 4.string重新赋值 补充:字符串拼接 总结 1. string的定义 Golang中的string的定义在reflect包下的value.go中,定义如下: StringHeader 是字符串的运行时表示,其中包含了两个字段,分别是指向数据数组的指针和数组的长度. // StringHeader is the runtime representation of a string. // I
-
GO语言基本类型String和Slice,Map操作详解
目录 本文大纲 1.字符串String String常用操作:获取长度和遍历 字符串的strings包 字符串的strconv包: 2.切片Slice 3.集合Map 本文大纲 本文继续学习GO语言基础知识点. 1.字符串String String是Go语言的基本类型,在初始化后不能修改,Go字符串是一串固定长度的字符连接起来的字符序列,当然它也是一个字节的切片(Slice). import ("fmt") func main() { name := "Hello World
-
Golang的strings.Split()踩坑记录
目录 背景 场景 前置 排查 验证 打印底层信息 追源码 类似情况 总结 背景 工作中,当我们需要对字符串按照某个字符串切分成字符串数组数时,常用到strings.Split() 最近在使用过程中踩到了个坑,后对踩坑原因做了分析,并总结了使用string.Split可能踩到的坑.最后写本篇文章做复盘总结与分享 场景 当时是需要取某个结构体的某个属性,并将其按,切分 整体逻辑类似这样的 type Info struct{ Ids string // Ids: 123,456 } func test
-
GoLang strings.Builder底层实现方法详解
目录 1.strings.Builder结构体 1.1strings.Builder结构体 1.2Write方法 1.3WriteByte方法 1.4WriteRune方法 1.5.WriteString方法 1.6String方法 1.7Len方法 1.8Cap方法 1.9Reset方法 1.10Grow方法 1.11grow方法 1.12copyCheck方法 2.strings.Builder介绍 3.存储原理 4.拷贝问题 5.不能与nil作比较 6.Grow深入 7.不支持并行读写 1
-
Golang底层原理解析String使用实例
目录 引言 String底层 stringStruct结构 引言 本人因为种种原因(说来听听),放弃大学学的java,走上了golang这条路,本着干一行爱一行的情怀,做开发嘛,不能只会使用这门语言,所以打算开一个底层原理系列,深挖一下,狠狠的掌握一下这门语言 废话不多说,上货 String底层 既然研究底层,那就得全方面覆盖,必须先搞一下基础的东西,那必须直接基本数据类型走起啊, 字符串String的底层我看就很基础 string大家应该都不陌生,go中的string是所有8位字节字符串的集合
-
GoLang string类型深入分析
目录 并发不安全 竞态竞争 字符串优化 文章运行环境:go version go1.16.6 darwin/amd64 并发不安全 看下面的代码,大家觉得会输出什么?大多数人应该都会觉得输出"".abc.neoj 这三种情况,但真实的情况并不是这样,真实情况是只输出 “” 空字符串. 结合日常的工作,类似这种并发操作同一个变量的情况也比较常见,为什么业务没有发生异常问题? var name string = "" func main() { go func() {
-
自己模拟写C++中的String类型实例讲解
下面是模拟实现字符串的相关功能,它包括一下功能: String(const char * s);//利用字符串来初始化对象 String(); //默认构造函数 String(const String & s);//复制构造函数,利用String类型来初始化对象 ~String(); //析构函数 int length(); //返回String类型中字符串的长度 String & operator=(const String & s);//重载=运算符. String &
-
C++中将string类型转化为int类型
写程序需要将string转化为int,所以就探索了一下. 方法一:atoi函数 atoi函数将字符串转化为整数,注意需要stdlib库.所以就尝试了一下: #include <iostream> #include <string.h> #include <stdlib.h> using namespace std; int main() { string a="11",b="22"; cout<<atoi(a)+ato
-
浅谈C++中的string 类型占几个字节
在C语言中我们操作字符串肯定用到的是指针或者数组,这样相对来说对字符串的处理还是比较麻烦的,好在C++中提供了 string 类型的支持,让我们在处理字符串时方便了许多. 首先,我写了一段测试代码,如下所示: 复制代码 代码如下: #include <iostream>using namespace std; int main(void){ string str_test1; string str_test2 = "Hello World"; int value1, val
-
Redis02 使用Redis数据库(String类型)全面解析
一 String类型 首先使用启动服务器进程 : redis-server.exe 1. Set 设置Key对应的值为String 类型的value. 例子:向 Redis数据库中插入一条数据类型为String 的记录. 在客户端输入命令: C:\software\redis\64bit>redis-cli.exe -h 127.0.0.1 -p 6379 redis 127.0.0.1:6379> set foo test OK redis 127.0.0.1:6379> get fo
-
js中string转int把String类型转化成int类型
今天做项目的时候,碰到一个问题,需要把String类型的变量转化成int类型的.按照常规,我写了var i = Integer.parseInt("112");但控制台报错,说是"'Integer' 未定义".后来,才知道,原来js中String转int和Java中不一样,不能直接把Java中的用到js中.改成var j = parseInt("11");就ok了. 备注:无论是 Java 还是 JavaScript, parseInt 方法都有
-
JavaScript的基本类型值-String类型
大致介绍 String类型用于表示由零或多个16位Unicode字符组成的字符序列,即字符串.在JavaScript中没有单个的字符型,都是字符串.字符型就相当于只包含一个字符的字符串. 引号 字符串可以由双引号("")或单引号('')表示,但是要注意,如果是双引号开始就要以双引号结束,单双引号是可以嵌套的 "hello"; //正确 'hello'; //正确 'hello"; //错误 "hel
-
java对象转换String类型的三种方法
一.采用Object.toString()toString方法是java.lang.Object对象的一个public方法.在java中任何对象都会继承Object对象,所以一般来说任何对象都可以调用toString这个方法.这是采用该种方法时,常派生类会覆盖Object里的toString()方法.但是在使用该方法时要注意,必须保证Object不是null值,否则将抛出NullPointerException异常. 二.采用(String)Object 该方法是一个标准的类型转换的方法,可以将
-
Java中char数组(字符数组)与字符串String类型的转换方法
本文实例讲述了Java中char数组(字符数组)与字符串String类型的转换方法.分享给大家供大家参考,具体如下: 在Java语言编程时,使用"口令字段"jPasswordField组件时,如果要获得密码值,就需要使用该组件的getPassword()方法.jPasswordField的getPassword()方法返回一个char类型的数组,我们经常需要将这个数组转换为String类型,以便进行诸如口令匹配或口令赋值等操作.这时,就需要将char类型的数组进行转换.当然也经常会遇到
-
简单谈谈Java中String类型的参数传递问题
提要:本文从实现原理的角度上阐述和剖析了:在Java语言中,以 String 作为类型的变量在作为方法参数时所表现出的"非对象"的特性. 一.最开始的示例 写代码最重要的就是实践,不经过反复试验而得出的说辞只能说是凭空遐想罢了.所以,在本文中首先以一个简单示例来抛出核心话题: public class StringAsParamOfMethodDemo { public static void main(String[] args) { StringAsParamOfMethodDem