使用ObjectMapper解析json不用一直new了
目录
- 前言
- 这代码有问题么?
- JMH测试结果
- End
前言
自从国产之光fastjson频频暴雷,jackson json的使用是越来越广泛了。尤其是spring家族把它搞成了默认的JSON处理包,jackson的使用数量更是呈爆炸式发展。
很多同学发现,jackson并没有类似fastjson的JSON.parseObjec这样的,确实看起来很快的方法。要想解析json,你不得不new一个ObjectMapper,来处理真正的解析动作。
就像下面这样。
public String getCarString(Car car){
ObjectMapper objectMapper = new ObjectMapper();
String str = objectMapper.writeValueAsString(car);
return str;
}
这种代码就在CV工程师手中遍地开了花。
神奇。
这代码有问题么?
你要说它有问题,它确实能正确的执行。你要说它没问题,在追求性能的同学眼里,这肯定是一段十恶不赦的代码。
一般的工具类,都是单例的,同时是线程安全的。ObjectMapper也不例外,它也是线程安全的,你可以并发的执行它,不会产生任何问题。
这段代码,ObjectMapper在每次方法调用的时候,都会生成一个。那它除了造成一定的年轻代内存浪费之外,在执行时间上有没有什么硬伤呢?
new和不new,真的区别有那么大么?
有一次,xjjdog隐晦的指出某段被频繁调用的代码问题,被小伙伴怒吼着拿出证据。
证据?这得搬出Java中的基准测试工具JMH,才能一探究竟。
JMH(the Java Microbenchmark Harness) 就是这样一个能够做基准测试的工具。如果你通过我们一系列的工具,定位到了热点代码,要测试它的性能数据,评估改善情况,就可以交给JMH。它的测量精度非常高,最高可达到纳秒的级别。
JMH是一个jar包,它和单元测试框架JUnit非常的像,可以通过注解进行一些基础配置。这部分配置有很多是可以通过main方法的OptionsBuilder进行设置的。
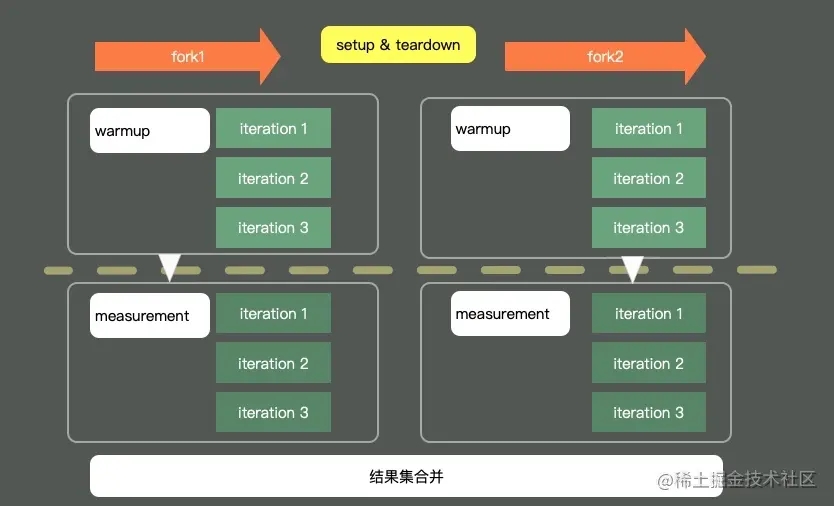
上图是一个典型的JMH程序执行的内容。通过开启多个进程,多个线程,首先执行预热,然后执行迭代,最后汇总所有的测试数据进行分析。在执行前后,还可以根据粒度处理一些前置和后置操作。
JMH测试结果
为了测试上面的场景,我们创造了下面的基准测试类。分为三个测试场景:
- 直接在方法里new ObjectMapper
- 在全局共享一个ObjectMapper
- 使用ThreadLocal,每个线程一个ObjectMapper
这样的测试属于cpu密集型的。我的cpu有10核,直接就分配了10个线程的并发,cpu在测试期间跑的满满的。
@BenchmarkMode({Mode.Throughput})
@OutputTimeUnit(TimeUnit.SECONDS)
@State(Scope.Thread)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@Threads(10)
public class ObjectMapperTest {
String json = "{ \"color\" : \"Black\", \"type\" : \"BMW\" }";
@State(Scope.Benchmark)
public static class BenchmarkState {
ObjectMapper GLOBAL_MAP = new ObjectMapper();
ThreadLocal<ObjectMapper> GLOBAL_MAP_THREAD = new ThreadLocal<>();
}
@Benchmark
public Map globalTest(BenchmarkState state) throws Exception{
Map map = state.GLOBAL_MAP.readValue(json, Map.class);
return map;
}
@Benchmark
public Map globalTestThreadLocal(BenchmarkState state) throws Exception{
if(null == state.GLOBAL_MAP_THREAD.get()){
state.GLOBAL_MAP_THREAD.set(new ObjectMapper());
}
Map map = state.GLOBAL_MAP_THREAD.get().readValue(json, Map.class);
return map;
}
@Benchmark
public Map localTest() throws Exception{
ObjectMapper objectMapper = new ObjectMapper();
Map map = objectMapper.readValue(json, Map.class);
return map;
}
public static void main(String[] args) throws Exception {
Options opts = new OptionsBuilder()
.include(ObjectMapperTest.class.getSimpleName())
.resultFormat(ResultFormatType.CSV)
.build();
new Runner(opts).run();
}
}
测试结果如下。
Benchmark Mode Cnt Score Error Units
ObjectMapperTest.globalTest thrpt 5 25125094.559 ± 1754308.010 ops/s
ObjectMapperTest.globalTestThreadLocal thrpt 5 31780573.549 ± 7779240.155 ops/s
ObjectMapperTest.localTest thrpt 5 2131394.345 ± 216974.682 ops/s
从测试结果可以看出,如果我们每次调用都new一个ObjectMapper,每秒可以执行200万次JSON解析;如果全局使用一个ObjectMapper,则每秒可以执行2000多万次,速度足足快了10倍。
如果使用ThreadLocal的方式,每个线程给它分配一个解析器,则性能会有少许上升,但也没有达到非常夸张的地步。
所以在项目中写代码的时候,我们只需要保证有一个全局的ObjectMapper就可以了。
当然,由于ObjectMapper有很多的特性需要配置,你可能会为不同的应用场景分配一个单独使用的ObjectMapper。总之,它的数量不需要太多,因为它是线程安全的。
End
所以结论就比较清晰了,我们只需要在整个项目里使用一个ObjectMapper就可以了,没必要傻不拉几的每次都new一个,毕竟性能差了10倍。如果你的JSON有很多自定义的配置,使用全局的变量更能凸显它的优势。
不要觉得这样做没有必要,保持良好的编码习惯永远是好的。高性能的代码都是点点滴滴积累起来的。不积跬步,无以至千里。不积小流,无以成江海,说的就是这个道理。
以上就是使用ObjectMapper解析json不用一直new了的详细内容,更多关于ObjectMapper解析json的资料请关注我们其它相关文章!
相关推荐
-
实例解析Json反序列化之ObjectMapper(自定义实现反序列化方法)
对于服务器端开发人员而言,调用第三方接口获取数据,将其"代理"转化并返给客户端几乎是家常便饭的事儿. 一般情况下,第三方接口返回的数据类型是json格式,而服务器开发人员则需将json格式的数据转换成对象,继而对其进行处理并封装,以返回给客户端. 在不是特别考虑效率的情况下(对于搜索.缓存等情形可以考虑使用thrift和protobuffer),通常我们会选取jackson包中的ObjectMapper类对json串反序列化以得到相应对象.通常会选取readValue(Strin
-
使用ObjectMapper把Json转换为复杂的实体类
ObjectMapper Json转换为复杂的实体类 实体类 主实体类* GetRigSmsResult* 里面的* smsContentList 是一个list类型的的 SmsContentSmsContent *集合. /** * * * @author 李关钦 * @version 2017年3月14日 */ public class GetRigSmsResult { private String dataCoding; private String messageParts; priv
-

解决ObjectMapper序列换Map时候的坑
ObjectMapper序列换Map时候的坑 今天,工作中,再一个分布式应用中,一个服务要调用另外一个服务,传输的数据时,返回的类型的Map<Integer,Integer>类型 的数据,但是我打印日志发现,数据是有数据的,但是通过key始终get不出来数据,后来发现传输回来的数据的key变成了String, 是不是很诡异. 打印日志的代码如下 打印的结果如下: 作为技术人,看到这样的情况,就像刨根问底,然后的看到了项目中使用的源码,然后本地模拟了下,发现原来 是ObjectMapper的序列
-
如何用ObjectMapper将复杂Map转换为实体类
目录 ObjectMapper将复杂Map转为实体类 背景 1.使用ObjectMapper要添加的依赖是 2.将复杂Map开始转换 objectMapper 解析复杂json toMap ObjectMapper将复杂Map转为实体类 背景 用fastjson转换复杂Map是浅层的可以转 深层的转换为null.,这时候可以用jackson来转. 1.使用ObjectMapper要添加的依赖是 <!--添加jackson包--> <dependency> <groupId&g
-
Java 多层嵌套JSON类型数据全面解析
目录 多层嵌套JSON类型数据解析 以下举例数据结构 解析代码 json解析多层嵌套并转为对应类(List) Json(随便扒的格式,将就看~) 关键依赖 JAVABEAN转JSONObject 多层嵌套JSON类型数据解析 简单来说: “key”:“value” --> 此时value为String“key":0 --> 此时value为int“key”:{“k1”:“v1”} --> 此时value为JSONObject“key”:[v] --> 此时value为JS
-
使用ObjectMapper解析json不用一直new了
目录 前言 这代码有问题么? JMH测试结果 End 前言 自从国产之光fastjson频频暴雷,jackson json的使用是越来越广泛了.尤其是spring家族把它搞成了默认的JSON处理包,jackson的使用数量更是呈爆炸式发展. 很多同学发现,jackson并没有类似fastjson的JSON.parseObjec这样的,确实看起来很快的方法.要想解析json,你不得不new一个ObjectMapper,来处理真正的解析动作. 就像下面这样. public String getCar
-
jQuery解析json数据实例分析
本文实例分析了jQuery解析json数据的方法.分享给大家供大家参考,具体如下: 先来看看我们的Json数据格式: [ {id:01,name:"小白",old:29,sex:"男"}, {id:02,name:"小蓝",old:29,sex:"男"}, {id:03,name:"小雅",old:29,sex:"男"} ] 为了消除乱码问题,我们设置一个过滤器(代码片段) public
-
vbs 解析json jsonp的方法
我收集了三种常见 json jsonp 的格式,因为很多人找我说如何用正则提取某个字符串,我看了下,要么是json,要么是jsonp, 正则简直浪费,比如那种空间里说说的数据,上百条的信息,你正则个P,而且还有回复里的格式也差不多的,所以最好的方法还是解析. 先来看看常见的三种吧: 酷我音乐用户信息 json 格式 http://kzone.kuwo.cn/mlog/UserVal?uid=1237357&from=profile {"work":4,"fans&qu
-
SpringMVC解析JSON请求数据问题解析
这几年都在搞前后端分离.RESTful风格,我们项目中也在这样用.前几天有人遇到了解析JSON格式的请求数据的问题,然后说了一下解析的方式,今天就写篇文章简单的分析一下后台对于JSON格式请求数据是怎么解析的. 先把例子的代码贴出来: 前端 <input type="button" value="测试JSON数据" onclick="testJSON()" /> <script type="text/javascrip
-
Go语言利用Unmarshal解析json字符串的实现
简单的解析例子: 首先还是从官方文档中的例子: package main import ( "fmt" "encoding/json" ) type Animal struct { Name string Order string } func main() { var jsonBlob = []byte(`[ {"Name": "Platypus", "Or
-
利用Jackson解析JSON的详细实现教程
目录 JSON 介绍 Jackson 介绍 Jackson Maven 依赖 ObjectMapper 对象映射器 Jackson JSON 基本操作 Jackson JSON 序列化 Jackson JSON 反序列化 JSON 转 List JSON 转 Map Jackson 忽略字段 Jackson 日期格式化 Date 类型 LocalDateTime 类型 时间格式化 Jackson 常用注解 @JsonIgnore @JsonGetter @JsonSetter @JsonAnyS
-
在Go语言程序中使用gojson来解析JSON格式文件
gojson是快速解析json数据的一个golang包,你使用它可以快速的查找json内的数据 安装 go get github.com/widuu/gojson 使用简介 结构 复制代码 代码如下: type Js struct { data interface{} } (1) func Json(data) *Js data为string类型,初始化Js结构,解析json并且return Js.data 复制代码 代码如下: json := `{"from":"e
-
Delphi中使用ISuperObject解析Json数据的实现代码
Java.Php等语言中都有成熟的框架来解析Json数据,可以让我们使用很少的代码就把格式化好的json数据转换成程序可识别的对象或者属性,同时delphi中也有这样的组件来实现此功能,即IsuperObject.如果还没有这个组件的请在网上搜索下载或者在下面留言处留下你的邮箱向本人索取. 下面先说一下ISuperObject中几个常用的函数 function SO(const s: SOString = '{}'): ISuperObject; overload; 此函数传入json数据字符串
-
Python解析json文件相关知识学习
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于JavaScript(Standard ECMA-262 3rd Edition - December 1999)的一个子集. JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等).这些特性使JSON成为理想的数据交换语言.易于人阅读和编写,同时也易于机器解析和生成. 今天用pytho