python读取eml文件并用正则表达式匹配邮箱的代码
目录
- 下面看看python正则表达式匹配邮箱
- 1. 一次匹配多个邮箱的情况
- 2. 一次匹配一个
今天接到一个需求有一个同事离职了,但是留下了非常多(2W多封)的邮件,我需要将他的邮件进行分类,只要邮件中以@xxx.com结尾的存放在文件夹中(下图名叫【是】的文件夹),否则放在另一个文件夹中(下图名叫【否】的文件夹)。 目录结构
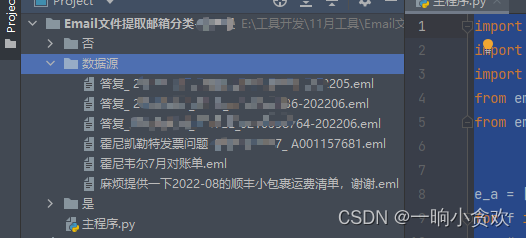
代码注意事项
import email(我发现是内置模块,不用安装) 下面是注意事项(就当是注释吧!!!!) 1、提取包含一下后缀的邮箱,我用了split(“@”),所以不用写 @
e_a = [‘Honeywell.com’, ‘honeywell.com’, ‘garrettmotion.com’, ‘HONEYWELL.COM’, ‘resideo.com’]
2、提取,收件人、发件人、抄送人的邮箱(这个是可以不写的,但是我这个代码是借鉴的,没找到提取全部内容的函数,只找到提取内容的函数,所以加上了下面的代码)
fjr = email.utils.parseaddr(msg.get(“from”))[1]
sjr = email.utils.parseaddr(msg.get(‘to’))[1]
csr = email.utils.parseaddr(msg.get(‘cc’))[1]
print(“发件人”, fjr)
print(“收件人”, sjr)
print(“抄送人”, csr)3、将eml文件内容与收件人、发件人、抄送人拼接,并且加 " " 间隔,不加会有些小问题
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
4、正则匹配邮箱
prog = re.compile(r’[a-zA-Z0-9_.±]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+')
res = prog.findall(text)5、移动文件 os.remove()
完整代码
import email
import os
import re
from email import policy
from email.parser import BytesParser
e_a = ['Honeywell.com', 'honeywell.com', 'garrettmotion.com', 'HONEYWELL.COM', 'resideo.com']
for f in os.listdir("./数据源/"):
# print(f)
text = ""
with open("./数据源/" + f, 'rb') as fp:
msg = BytesParser(policy=policy.default).parse(fp)
fjr = email.utils.parseaddr(msg.get("from"))[1]
sjr = email.utils.parseaddr(msg.get('to'))[1]
csr = email.utils.parseaddr(msg.get('cc'))[1]
print("发件人", fjr)
print("收件人", sjr)
print("抄送人", csr)
if msg.get_body(preferencelist=('plain'))==None:
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
else:
text = msg.get_body(preferencelist=('plain')).get_content()
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
# print(text)
prog = re.compile(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
res = prog.findall(text)
for e in res:
res1 = e.split("@")[1]
if res1 in e_a:
print(f, "在")
ori = "./数据源/" + f
now = "./是/" + f
os.rename(ori, now)
break
else:
ori = "./数据源/" + f
now = "./否/" + f
os.rename(ori, now)
print(f, "不在")
下面看看python正则表达式匹配邮箱
下面来看看python验证邮箱模式的例子。
(首先还是把环境列出来)
环境:python 2.7.10
1. 一次匹配多个邮箱的情况
下面的例子中:邮箱中可以出现 数字、大小写字母、下划线、和横线(-)
# -*- coding:utf-8 -*-
# 邮箱格式-正则表达式匹配
import re
# 一次匹配多个邮箱
str1 = 'aaf ssa@ss.net asdf asdb@163.com.cn asdf ss-a@ss.net asdf asdd.cba@163.com afdsaf'
reg_str1 = r'([\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+)'
mod = re.compile(reg_str1)
items = mod.findall(str1)
for item in items:
print item
结果输出:

2. 一次匹配一个
这种情况,常见在登录界面用户名为邮箱时, 此时一个字符串只有一个 邮箱
# 只匹配一个
str2 = 'ssa_a-c@ss.net.cn'
reg_str2 = r'(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)'
mod = re.compile(reg_str2)
items = mod.findall(str2)
for item in items:
print item
结果输出:
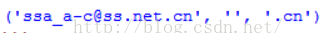
到此这篇关于python读取eml文件并用正则匹配邮箱的文章就介绍到这了,更多相关python读取eml文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python正则匹配抓取豆瓣电影链接和评论代码分享
复制代码 代码如下: import urllib.requestimport reimport time def movie(movieTag): tagUrl=urllib.request.urlopen(url) tagUrl_read = tagUrl.read().decode('utf-8') return tagUrl_read def subject(tagUrl_read): ''' 这里还存在问题: ①这只针对单独的一页进行排序,而没有
-
Python时间的精准正则匹配方法分析
本文实例讲述了Python时间的精准正则匹配方法.分享给大家供大家参考,具体如下: 要用正则表达式精准匹配时间,其实并不容易 方式一: >>> import re >>> t = '19:10:48' >>> m = re.match(r'(.*):(.*):(.*)', t) >>> m.groups() ('19', '10', '48') 方式二: >>> t = '19:10:48' >>>
-
Python3正则匹配re.split,re.finditer及re.findall函数用法详解
本文实例讲述了Python3正则匹配re.split,re.finditer及re.findall函数用法.分享给大家供大家参考,具体如下: re.split re.finditer re.findall @(python3) 官方 re 模块说明文档 re.compile() 函数 编译正则表达式模式,返回一个对象.可以把常用的正则表达式编译成正则表达式对象,方便后续调用及提高效率. re 模块最离不开的就是 re.compile 函数.其他函数都依赖于 compile 创建的 正则表达式对象
-
python正则表达式去掉数字中的逗号(python正则匹配逗号)
分析 数字中经常是3个数字一组,之后跟一个逗号,因此规律为:***,***,*** 正则式 复制代码 代码如下: [a-z]+,[a-z]? 复制代码 代码如下: import re sen = "abc,123,456,789,mnp"p = re.compile("\d+,\d+?") for com in p.finditer(sen): mm = com.group() print "hi:", mm print &qu
-
python 包之 re 正则匹配教程分享
目录 一.开头匹配 二.全匹配 三.部分匹配 四.匹配替换 五.匹配替换返回数量 六.分割字符串 七.匹配所有 八.迭代器匹配 九.编译对象 十.修饰符 一.开头匹配 从字符串开头开始匹配 返回匹配对象:如果找不到匹配,则为None import re print(re.match('飞兔小哥', '飞兔小哥教你零基础学编程')) print(re.match('学编程', '飞兔小哥教你零基础学编程')) 二.全匹配 匹配字符串是否和给定的字符一模一样 如果一模一样才返回匹配对象,如果找不到匹
-
Python正则匹配判断手机号是否合法的方法
正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),是计算机科学的一个概念.正则表达式使用单个字符串来描述.匹配一系列匹配某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索.替换那些匹配某个模式的文本. # 需求 # 定义一个函数,用于判断输入的手机号是否合法 # 并判断它的运营商 # 思路步骤: # 1.首先了解三大运营商的号段分布 # 2.获取用户输入内容 #
-

python读取eml文件并用正则表达式匹配邮箱的代码
目录 下面看看python正则表达式匹配邮箱 1. 一次匹配多个邮箱的情况 2. 一次匹配一个 今天接到一个需求有一个同事离职了,但是留下了非常多(2W多封)的邮件,我需要将他的邮件进行分类,只要邮件中以@xxx.com结尾的存放在文件夹中(下图名叫[是]的文件夹),否则放在另一个文件夹中(下图名叫[否]的文件夹). 目录结构 代码注意事项 import email(我发现是内置模块,不用安装) 下面是注意事项(就当是注释吧!!!!) 1.提取包含一下后缀的邮箱,我用了split(“@”),所以
-
通过python读取txt文件和绘制柱形图的实现代码
目的 临床数据的记录时间和对应标签(逗号后面的数字)记录在txt文件里,要把标签转换为3类标签,并且计算出每个标签的分别持续时间,然后绘制成柱形图方便查阅. 小难点分析: (1)txt的切割读取对应内容 (2)时间差计算 txt文件如图: 使用效果 首先将原始txt转换为 左列新标签 右列持续时间 绘制为柱形图 为了直观,每次只最多显示 2个小时,同时横坐标还是按照临床的记录时间顺序. 代码实现 # -*- coding: utf-8 -*- from datetime import date
-
Python读取csv文件实例解析
这篇文章主要介绍了Python读取csv文件实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 创建一个csv文件,命名为data.csv,文本内容如下: root,123456,login successfully root,wrong,wrong password wrong,123456,nonexistent username ,123456,username is null root,,password is null 使用Exc
-
使用python读取.text文件特定行的数据方法
如何用python循环读取下面.txt文件中,用红括号标出来的数据呢? 首先,观察数据可知,不同行的第一个数据元素不一样,所以考虑直接用正则表达式. 再加上,对读和写文件的操作,就行了 注:我用的是pycharm+python2.7 话不多说,直接上代码 import re f1=file('shen.txt','r') data1=f1.readlines() # print data1 f1.close() results = [] for line in data1: data2=line
-
在VB中遍历文件并用正则表达式完成复制及vb实现重命名、拷贝文件夹的方法
先看下在VB中遍历文件并用正则表达式完成复制功能 将"E:\my\汇报\成绩"路径下源文件中的"1项目","一项目"等文件复制到目标文件下.以下为实现方式. Private Sub Option1_Click() Dim myStr As String '通过在单元格中输入项目序号,目前采用的InputBox方式指定的,也可通过此方式.二者取其一. 'myStr = Sheets("Sheet1").Range("D
-
python 读取yaml文件的两种方法(在unittest中使用)
作者:做梦的人(小姐姐) 出处:https://www.cnblogs.com/chongyou/ python读取yaml文件使用,有两种方式: 1.使用ddt读取 2,使用方法读取ddt的内容,在使用方法中进行调用 1.使用ddt读取 @ddt.ddt class loginTestPage(unittest.TestCase): @ddt.file_data(path) @ddt.unpack def testlogin(self,**kwargs):
-
python读取json文件并将数据插入到mongodb的方法
本文实例讲述了python读取json文件并将数据插入到mongodb的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 import sunburnt import urllib from pymongo import Connection from bson.objectid import ObjectId import logging from datetime import datetime import json from time import mktime
-
python 读取excel文件生成sql文件实例详解
python 读取excel文件生成sql文件实例详解 学了python这么久,总算是在工作中用到一次.这次是为了从excel文件中读取数据然后写入到数据库中.这个逻辑用java来写的话就太重了,所以这次考虑通过python脚本来实现. 在此之前需要给python添加一个xlrd模块,这个模块是专门用来操作excel文件的. 在mac中可以通过easy_install xlrd命令实现自动安装模块 import xdrlib ,sys import xlrd def open_excel(fil
-
Python读取ini文件、操作mysql、发送邮件实例
我是闲的没事干,2014过的太浮夸了,博客也没写几篇,哎~~~ 用这篇来记录即将逝去的2014 python对各种数据库的各种操作满大街都是,不过,我还是喜欢我这种风格的,涉及到其它操作,不过重点还是对数据库的操作.呵~~ Python操作Mysql 首先,我习惯将配置信息写到配置文件,这样修改时可以不用源代码,然后再写通用的函数供调用 新建一个配置文件,就命名为conf.ini,可以写各种配置信息,不过都指明节点(文件格式要求还是较严格的): 复制代码 代码如下: [app_info] DAT
-
Python实现读取txt文件并画三维图简单代码示例
记忆力差的孩子得勤做笔记! 刚接触python,最近又需要画一个三维图,然后就找了一大堆资料,看的人头昏脑胀的,今天终于解决了!好了,废话不多说,直接上代码! #由三个一维坐标画三维散点 #coding:utf-8 import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d.axes3d import Axes3D x = [] y = [] z = [] f = open("data\\record.