解析ROC曲线绘制(python+sklearn+多分类)
目录
- ROC曲线绘制要点(仅记录)
- 提取数据(标签值和模型预测值)
- 多分类的ROC曲线画出来并不难
ROC曲线绘制要点(仅记录)
1、ROC用于度量模型性能
2、用于二分类问题,如若遇到多分类也以二分类的思想进行操作。
3、二分类问题代码实现(至于实现,文档说的很清楚了:官方文档)
原理看懂就好,实现直接调用API即可
提取数据(标签值和模型预测值)
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_true,y_sore)
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, '#9400D3',label=u'AUC = %0.3f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.1])
plt.ylim([-0.1,1.1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.grid(linestyle='-.')
plt.grid(True)
plt.show()
print(roc_auc)

4、多分类问题代码实现
对于两个以上类的分类问题,
这里就有ROC的宏观平均(macro-average)和微观平均(micro-average)的做法了(具体查阅机器学习)
在这之前,我想肯定会有人想把每个类别的ROC的都绘制出来,实现起来,无非就是获得每个单类的标签值和模型预测值数据
不过你怎么解释呢?有什么意义呢?其实这个问题我也想了很久,查阅了很多文献,也没有个所以然。
PS:(如果有人知道,麻烦告知下~)
多分类的ROC曲线画出来并不难
具体如下
import numpy as np import matplotlib.pyplot as plt from scipy import interp from sklearn.preprocessing import label_binarize from sklearn.metrics import confusion_matrix,classification_report from sklearn.metrics import roc_curve, auc from sklearn.metrics import cohen_kappa_score, accuracy_score
fpr0, tpr0, thresholds0 = roc_curve(y_true0,y_sore0)
fpr1, tpr1, thresholds1 = roc_curve(y_true1,y_sore1)
fpr2, tpr2, thresholds2 = roc_curve(y_true2,y_sore2)
fpr3, tpr3, thresholds3 = roc_curve(y_true3,y_sore3)
fpr4, tpr4, thresholds4 = roc_curve(y_true4,y_sore4)
roc_auc0 = auc(fpr0, tpr0)
roc_auc1 = auc(fpr1, tpr1)
roc_auc2 = auc(fpr2, tpr2)
roc_auc3 = auc(fpr3, tpr3)
roc_auc4 = auc(fpr4, tpr4)
plt.title('Receiver Operating Characteristic')
plt.rcParams['figure.figsize'] = (10.0, 10.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 设置标题大小
plt.rcParams['font.size'] = '16'
plt.plot(fpr0, tpr0, 'k-',color='k',linestyle='-.',linewidth=3,markerfacecolor='none',label=u'AA_AUC = %0.5f'% roc_auc0)
plt.plot(fpr1, tpr1, 'k-',color='grey',linestyle='-.',linewidth=3,label=u'A_AUC = %0.5f'% roc_auc1)
plt.plot(fpr2, tpr2, 'k-',color='r',linestyle='-.',linewidth=3,markerfacecolor='none',label=u'B_AUC = %0.5f'% roc_auc2)
plt.plot(fpr3, tpr3, 'k-',color='red',linestyle='-.',linewidth=3,markerfacecolor='none',label=u'C_AUC = %0.5f'% roc_auc3)
plt.plot(fpr4, tpr4, 'k-',color='y',linestyle='-.',linewidth=3,markerfacecolor='none',label=u'D_AUC = %0.5f'% roc_auc4)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.1])
plt.ylim([-0.1,1.1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.grid(linestyle='-.')
plt.grid(True)
plt.show()
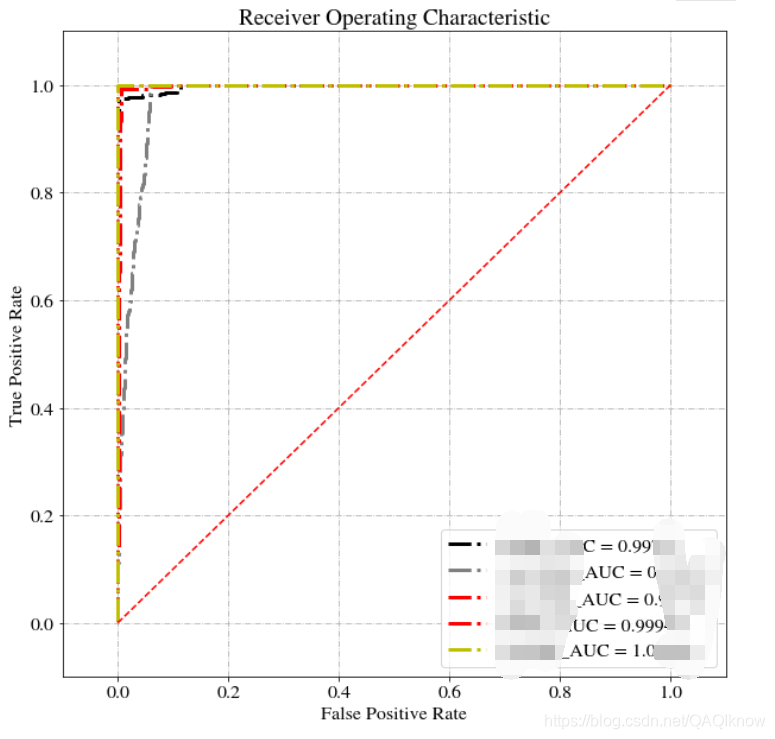
在上面的基础上,我们将标签二值化
(如果你不使用二分类思想去画ROC曲线,大概率会出现报错:ValueError: multilabel-indicator format is not supported)
y_test_all = label_binarize(true_labels_i, classes=[0,1,2,3,4])
y_score_all=test_Y_i_hat
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(len(classes)):
fpr[i], tpr[i], thresholds = roc_curve(y_test_all[:, i],y_score_all[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
注意看,宏观平均(macro-average)和微观平均(micro-average)的处理方式
(y_test_all(真实标签值)和y_score_all(与真实标签值维度匹配,如果十个类就对应十个值,↓行代表数据序号,列代表每个类别的预测值)
# micro-average ROC curve(方法一)
fpr["micro"], tpr["micro"], thresholds = roc_curve(y_test_all.ravel(),y_score_all.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# macro-average ROC curve 方法二)
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(len(classes))]))
mean_tpr = np.zeros_like(all_fpr)
for i in range(len(classes)):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# 求平均计算ROC包围的面积AUC
mean_tpr /= len(classes)
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
#画图部分
plt.figure()
plt.plot(fpr["micro"], tpr["micro"],'k-',color='y',
label='XXXX ROC curve micro-average(AUC = {0:0.4f})'
''.format(roc_auc["micro"]),
linestyle='-.', linewidth=3)
plt.plot(fpr["macro"], tpr["macro"],'k-',color='k',
label='XXXX ROC curve macro-average(AUC = {0:0.4f})'
''.format(roc_auc["macro"]),
linestyle='-.', linewidth=3)
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.1])
plt.ylim([-0.1,1.1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.legend(loc="lower right")
plt.grid(linestyle='-.')
plt.grid(True)
plt.show()

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python中ROC曲线绘制
首先以支持向量机模型为例 先导入需要使用的包,我们将使用roc_curve这个函数绘制ROC曲线! from sklearn.svm import SVC from sklearn.metrics import roc_curve from sklearn.datasets import make_blobs from sklearn. model_selection import train_test_split import matplotlib.pyplot as plt %matplot
-
python实现二分类和多分类的ROC曲线教程
基本概念 precision:预测为对的当中,原本为对的比例(越大越好,1为理想状态) recall:原本为对的当中,预测为对的比例(越大越好,1为理想状态) F-measure:F度量是对准确率和召回率做一个权衡(越大越好,1为理想状态,此时precision为1,recall为1) accuracy:预测对的(包括原本是对预测为对,原本是错的预测为错两种情形)占整个的比例(越大越好,1为理想状态) fp rate:原本是错的预测为对的比例(越小越好,0为理想状态) tp rate:原本是对的
-
利用scikitlearn画ROC曲线实例
一个完整的数据挖掘模型,最后都要进行模型评估,对于二分类来说,AUC,ROC这两个指标用到最多,所以 利用sklearn里面相应的函数进行模块搭建. 具体实现的代码可以参照下面博友的代码,评估svm的分类指标.注意里面的一些细节需要注意,一个是调用roc_curve 方法时,指明目标标签,否则会报错. 具体是这个参数的设置pos_label ,以前在unionbigdata实习时学到的. 重点是以下的代码需要根据实际改写: mean_tpr = 0.0 mean_fpr = np.linspac
-
解析ROC曲线绘制(python+sklearn+多分类)
目录 ROC曲线绘制要点(仅记录) 提取数据(标签值和模型预测值) 多分类的ROC曲线画出来并不难 ROC曲线绘制要点(仅记录) 1.ROC用于度量模型性能 2.用于二分类问题,如若遇到多分类也以二分类的思想进行操作. 3.二分类问题代码实现(至于实现,文档说的很清楚了:官方文档) 原理看懂就好,实现直接调用API即可 提取数据(标签值和模型预测值) from sklearn.metrics import roc_curve, auc fpr, tpr, thresholds = roc_cur
-
python如何将多个模型的ROC曲线绘制在一张图(含图例)
目录 多条ROC曲线绘制函数 绘制效果 调用格式与方法 详细解释和说明 1.关键函数 2.参数解释 需要注意的小小坑 补充 总结 多条ROC曲线绘制函数 def multi_models_roc(names, sampling_methods, colors, X_test, y_test, save=True, dpin=100): """ 将多个机器模型的roc图输出到一张图上 Args: names: list, 多个模型的名称 sampling_methods: li
-
python sklearn常用分类算法模型的调用
本文实例为大家分享了python sklearn分类算法模型调用的具体代码,供大家参考,具体内容如下 实现对'NB', 'KNN', 'LR', 'RF', 'DT', 'SVM','SVMCV', 'GBDT'模型的简单调用. # coding=gbk import time from sklearn import metrics import pickle as pickle import pandas as pd # Multinomial Naive Bayes Classifier d
-
基于python实现ROC曲线绘制广场解析
ROC 结果 源数据:鸢尾花数据集(仅采用其中的两种类别的花进行训练和检测) Summary features:['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] 实例:[5.1, 3.5, 1.4, 0.2] target:'setosa' 'versicolor' (0 , 1) 采用回归方法进行拟合得到参数和bias model.fit(data_train, data_tra
-
R语言利用caret包比较ROC曲线的操作
说明 我们之前探讨了多种算法,每种算法都有优缺点,因而当我们针对具体问题去判断选择那种算法时,必须对不同的预测模型进行重做评估. 为了简化这个过程,我们使用caret包来生成并比较不同的模型与性能. 操作 加载对应的包与将训练控制算法设置为10折交叉验证,重复次数为3: library(ROCR) library(e1071) library("pROC") library(caret) library("pROC") control = trainControl(
-
python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上.应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取.降维.训练预测.通过混淆矩阵看分类效果,得出报告. 1.输入 从数据集开始,提取特征转化为有标签的数据集,转为向量.拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可.在训练集中有data和target开始. 2.
-
Python sklearn分类决策树方法详解
目录 决策树模型 决策树学习 使用Scikit-learn进行决策树分类 决策树模型 决策树(decision tree)是一种基本的分类与回归方法. 分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点(leaf node).内部结点表示一个特征或属性,叶结点表示一个类. 用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子
-
Python sklearn库实现PCA教程(以鸢尾花分类为例)
PCA简介 主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等.矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推. 基本步骤: 具体实现 我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布.样本数据结构如下图: 其中样本总数为150