GoLang函数与面向接口编程全面分析讲解
目录
- 一、函数
- 1. 函数的基本形式
- 2. 递归函数
- 3. 匿名函数
- 4. 闭包
- 5. 延迟调用defer
- 6. 异常处理
- 二、面向接口编程
- 1. 接口的基本概念
- 2. 接口的使用
- 3. 接口的赋值
- 4. 接口嵌入
- 5. 空接口
- 6. 类型断言
- 7. 面向接口编程
一、函数
1. 函数的基本形式
// 函数定义:a,b是形参
func add(a int, b int) {
a = a + b
}
var x, y int = 3, 6
add(x, y) // 函数调用:x,y是实参
- 形参是函数内部的局部变量,实参的值会拷贝给形参
- 函数定义时的第一个的大括号不能另起一行
- 形参可以有0个或多个,支持使用可边长参数
- 参数类型相同时可以只写一次,比如add(a,b int)
- 在函数内部修改形参的值,实参的值不受影响
- 如果想通过函数修改实参,就需要传递指针类型
func change(a, b *int) {
*a = *a + *b
*b = 888
}
var x, y int = 3, 6
change(&x, &y)
slice、map、channel都是引用类型,它们作为函数参数时其实跟普通struct没什么区别,都是对struct内部的各个字段做一次拷贝传到函数内部
package main
import "fmt"
// slice作为参数,实际上是把slice的arrayPointer、len、cap拷贝了一份传进来
func sliceChange(arr []int) {
arr[0] = 1 // 实际是修改底层数据里的首元素
arr = append(arr, 1) // arr的len和cap发生了变化,不会影响实参
}
func main() {
arr := []int{8}
sliceChange(arr)
fmt.Println(arr[0]) // 1,数组元素发生改变
fmt.Println(len(arr)) // 1,实际的长度没有改变
}
关于函数返回值
- 可以返回0个或多个参数
- 可以在func行直接声明要返回的变量
- return后面的语句不会执行
- 无返回参数时return可以不写
// 返回变量c已经声明好了,在函数中可以直接使用
func returnf(a, b int) (c int) {
a = a + b
c = a // 直接使用c
return // 由于函数要求有返回值,即使给c赋过值了,也需要显式写return
}
不定长参数实际上是slice类型
// other为不定长参数可传递任意多个参数,a是必须传递的参数
func args(a int, other ...int) int {
sum := a
// 直接当作slice来使用
for _, ele := range other {
sum += ele
}
fmt.Printf("len %d cap %d\n", len(other), cap(other))
return sum
}
args(1)
args(1,2,3,4)
append函数接收的就是不定长参数
arr = append(arr, 1, 2, 3)
arr = append(arr, 7)
arr = append(arr)
slice := append([]byte("hello "), "world"...) // ...自动把"world"转成byte切片,等价于[]byte("world")...
slice2 := append([]rune("hello "), []rune("world")...) // 需要显式把"world"转成rune切片
在很多场景下string都隐式的转换成了byte切片,而非rune切片,比如"a中"[1]获取到的值为228而非"中"
2. 递归函数
最经典的斐波那契数列的递归求法
func fibonacci(n int) int {
if n == 0 || n == 1 {
return n // 凡是递归,一定要有终止条件,否则会进入无限循环
}
return fibonacci(n-1) + fibonacci(n-2) // 递归调用自身
}
3. 匿名函数
函数也是一种数据类型
func functionArg1(f func(a, b int) int, b int) int { // f参数是一种函数类型
a := 2 * b
return f(a, b)
}
type foo func(a, b int) int // foo是一种函数类型
func functionArg2(f foo, b int) int { // type重命名之后,参数类型看上去简洁多了
a := 2 * b
return f(a, b)
}
type User struct {
Name string
bye foo // bye的类型是foo,也就是是函数类型
hello func(name string) string // 使用匿名函数来声明struct字段的类型为函数类型
}
ch := make(chan func(string) string, 10)
// 使用匿名函数向管道中添加元素
ch <- func(name string) string {
return "hello " + name
}
4. 闭包
闭包(Closure)是引用了自由变量的函数,自由变量将和函数一同存在,即使已经离开了创造它的环境,闭包复制的是原对象的指针
package main
import "fmt"
func sub() func() {
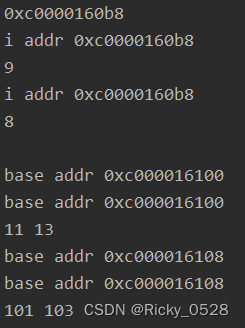
i := 10
fmt.Printf("%p\n", &i)
b := func() {
fmt.Printf("i addr %p\n", &i) // 闭包复制的是原对象的指针
i-- // b函数内部引用了变量i
fmt.Println(i)
}
return b // 返回了b函数,变量i和函数b将一起存在,即使已经离开函数sub()
}
// 外部引用函数参数局部变量
func add(base int) func(int) int {
return func(i int) int {
fmt.Printf("base addr %p\n", &base)
base += i
return base
}
}
func main() {
b := sub()
b()
b()
fmt.Println()
tmp1 := add(10)
fmt.Println(tmp1(1), tmp1(2))
// 此时tmp1和tmp2不是一个实体了
tmp2 := add(100)
fmt.Println(tmp2(1), tmp2(2))
}
5. 延迟调用defer
- defer用于注册一个延迟调用(在函数返回之前调用)
- defer典型的应用场景是释放资源,比如关闭文件句柄,释放数据库连接等
- 如果同一个函数里有多个defer,则后注册的先执行,相当于是一个栈
- defer后可以跟一个func,func内部如果发生panic,会把panic暂时搁置,当把其他defer执行完之后再来执行这个
- defer后不是跟func,而直接跟一条执行语句,则相关变量在注册defer时被拷贝或计算
func basic() {
fmt.Println("A")
defer fmt.Println(1) fmt.Println("B")
// 如果同一个函数里有多个defer,则后注册的先执行
defer fmt.Println(2)
fmt.Println("C")
}
func deferExecTime() (i int) {
i = 9
// defer后可以跟一个func
defer func() {
fmt.Printf("first i=%d\n", i) // 打印5,而非9,充分理解“defer在函数返回前执行”的含义,不是在“return语句前执行defer”
}()
defer func(i int) {
fmt.Printf("second i=%d\n", i) // 打印9
}(i)
defer fmt.Printf("third i=%d\n", i) // 打印9,defer后不是跟func,而直接跟一条执行语句,则相关变量在注册defer时被拷贝或计算
return 5
}
6. 异常处理
go语言没有try catch,它提倡直接返回error
func divide(a, b int) (int, error) {
if b == 0 {
return -1, errors.New("divide by zero")
}
return a / b, nil
}
// 函数调用方判断error是否为nil,不为nil则表示发生了错误
if res, err := divide(3, 0); err != nil {
fmt.Println(err.Error())
}
Go语言定义了error这个接口,自定义的error要实现Error()方法
// 自定义error
type PathError struct {
path string
op string
createTime string
message string
}
// error接口要求实现Error() string方法
func (err PathError) Error() string {
return err.createTime + ": " + err.op + " " + err.path + " " + err.message
}
何时会发生panic:
- 运行时错误会导致panic,比如数组越界、除0
- 程序主动调用panic(error)
panic会执行什么:
- 逆序执行当前goroutine的defer链(recover从这里介入)
- 打印错误信息和调用堆栈
- 调用exit(2)结束整个进程
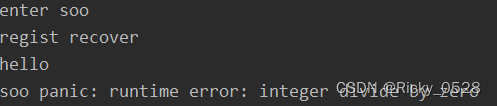
func soo() {
fmt.Println("enter soo")
// 去掉这个defer试试,看看panic的流程,把这个defer放到soo函数末尾试试
defer func() {
// recover必须在defer中才能生效
if err := recover(); err != nil {
fmt.Printf("soo panic:%s\n", err)
}
}()
fmt.Println("regist recover")
defer fmt.Println("hello")
defer func() {
n := 0
_ = 3 / n // 除0异常,发生panic,下一行的defer没有注册成功
defer fmt.Println("how are you")
}()
}
二、面向接口编程
1. 接口的基本概念
接口是一组行为规范的集合
// 定义接口,通常接口名以er结尾
type Transporter interface {
// 接口里面只定义方法,不定义变量
move(src string, dest string) (int, error) // 方法名 (参数列表) 返回值列表
whistle(int) int // 参数列表和返回值列表里的变量名可以省略
}
只要结构体拥有接口里声明的所有方法,就称该结构体“实现了接口”,一个struct可以同时实现多个接口
// 定义结构体时无需要显式声明它要实现什么接口
type Car struct {
price int
}
func (car Car) move(src string, dest string) (int, error) {
return car.price, nil
}
func (car Car) whistle(n int) int {
return n
}
接口值有两部分组成, 一个指向该接口的具体类型的指针和另外一个指向该具体类型真实数据的指针
car := Car{"宝马", 100}
var transporter Transporter
transporter = car

2. 接口的使用
func transport(src, dest string, transporter Transporter) error {
_,err := transporter.move(src, dest)
return err
}
var car Car // Car实现了Transporter接口
var ship Shiper // Shiper实现了Transporter接口
transport("北京", "天津", car)
transport("北京", "天津", ship)
3. 接口的赋值
// 方法接收者是值
func (car Car) whistle(n int) int {
}
// 方法接收者用指针,则实现接口的是指针类型
func (ship *Shiper) whistle(n int) int {
}
car := Car{}
ship := Shiper{}
var transporter Transporter
transporter = car
transporter = &car // 值实现的方法,默认指针同样也实现了
transporter = &ship // 但指针实现的方法,值是没有实现的
4. 接口嵌入
type Transporter interface {
whistle(int) int
}
type Steamer interface {
Transporter // 接口嵌入,相当于Transporter接口定义的行为集合是Steamer的子集
displacement() int
}
5. 空接口
空接口类型用interface{}表示,注意有{}
var i interface{<!--{cke_protected}{C}%3C!%2D%2D%20%2D%2D%3E-->}
空接口没有定义任何方法,因此任意类型都实现了空接口
var a int = 5 i = a
func square(x interface{<!--{cke_protected}{C}%3C!%2D%2D%20%2D%2D%3E-->}){<!--{cke_protected}{C}%3C!%2D%2D%20%2D%2D%3E-->} // 该函数可以接收任意数据类型
注意:slice的元素、map的key和value都可以是空接口类型,map中的key可以是任意能够用==操作符比较的类型,不能是函数、map、切片,以及包含上述3中类型成员变量的的struct,map的value可以是任意类型
6. 类型断言
// 若断言成功,则ok为true,v是具体的类型
if v, ok := i.(int); ok {
fmt.Printf("i是int类型,其值为%d\n", v)
} else {
fmt.Println("i不是int类型")
}
当要判断的类型比较多时,就需要写很多if-else,更好的方法是使用switch i.(type),这也是标准的写法
switch v := i.(type) { // 隐式地在每个case中声明了一个变量v
case int: // v已被转为int类型
fmt.Printf("ele is int, value is %d\n", v)
// 在 Type Switch 语句的 case 子句中不能使用fallthrough
case float64: // v已被转为float64类型
fmt.Printf("ele is float64, value is %f\n", v)
case int8, int32, byte: // 如果case后面跟多种type,则v还是interface{}类型
fmt.Printf("ele is %T, value is %d\n", v, v)
}
7. 面向接口编程
电商推荐流程

为每一个步骤定义一个接口
type Recaller interface {
Recall(n int) []*common.Product // 生成一批推荐候选集
}
type Sorter interface {
Sort([]*common.Product) []*common.Product // 传入一批商品,返回排序之后的商品
}
type Filter interface {
Filter([]*common.Product) []*common.Product // 传入一批商品,返回过滤之后的商品
}
type Recommender struct {
Recallers []recall.Recaller
Sorter sort.Sorter
Filters []filter.Filter
}
使用纯接口编写推荐主流程
func (rec *Recommender) Rec() []*common.Product {
RecallMap := make(map[int]*common.Product, 100)
// 顺序执行多路召回
for _, recaller := range rec.Recallers {
products := recaller.Recall(10) // 统一设置每路最多召回10个商品
for _, product := range products {
RecallMap[product.Id] = product // 把多路召回的结果放到map里,按Id进行排重
}
}
// 把map转成slice
RecallSlice := make([]*common.Product, 0, len(RecallMap))
for _, product := range RecallMap {
RecallSlice = append(RecallSlice, product)
}
SortedResult := rec.Sorter.Sort(RecallSlice) // 对召回的结果进行排序
// 顺序执行多种过滤规则
FilteredResult := SortedResult
for _, filter := range rec.Filters {
FilteredResult = filter.Filter(FilteredResult)
}
return FilteredResult
}
面向接口编程,在框架层面全是接口。具体的实现由不同的开发者去完成,每种实现单独放到一个go文件里,大家的代码互不干扰。通过配置选择采用哪种实现,也方便进行效果对比
到此这篇关于GoLang函数与面向接口编程全面分析讲解的文章就介绍到这了,更多相关GoLang函数与面向接口内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Golang接口使用教程详解
目录 前言 一.概述 二.接口类型 2.1 接口的定义 2.2 实现接口的条件 2.3 为什么需要接口 2.4 接口类型变量 三.值接收者和指针接收者 3.1 值接收者实现接口 3.2 指针接收者实现接口 四.类型与接口的关系 4.1 一个类型实现多个接口 4.2 多种类型实现同一接口 五.接口嵌套 六.空接口 七.类型断言 总结 前言 go语言并没有面向对象的相关概念,go语言提到的接口和java.c++等语言提到的接口不同,它不会显示的说明实现了接口,没有继承.子类.implements关键
-
一文带你了解Go语言中接口的使用
目录 接口 接口的实现 接口类型变量 空接口 类型断言 类型断言变种 type switch 小结 接口 在 Go 语言中,接口是一种抽象的类型,是一组方法的集合.接口存在的目的是定义规范,而规范的细节由其他对象去实现.我们来看一个例子: import "fmt" type Person struct { Name string } func main() { person := Person{Name: "cmy"} fmt.Println(person) //
-
GoLang函数与面向接口编程全面分析讲解
目录 一.函数 1. 函数的基本形式 2. 递归函数 3. 匿名函数 4. 闭包 5. 延迟调用defer 6. 异常处理 二.面向接口编程 1. 接口的基本概念 2. 接口的使用 3. 接口的赋值 4. 接口嵌入 5. 空接口 6. 类型断言 7. 面向接口编程 一.函数 1. 函数的基本形式 // 函数定义:a,b是形参 func add(a int, b int) { a = a + b } var x, y int = 3, 6 add(x, y) // 函数调用:x,y是实参 形参是函
-
Golang pprof性能测试与分析讲解
目录 一.性能分析类型 1.CPU性能分析 2.内存性能分析 3.阻塞性能分析 二.cpu性能分析 1.生成pporf 2.分析数据 三.内存性能分析 四.benchmark 生成 profile 一.性能分析类型 1.CPU性能分析 CPU性能分析是最常见的性能分析类型.启动CPU分析时,运行时每隔10ms中断一次,采集正在运行协程的堆栈信息. 程序运行结束后,可以根据收集的数据,找到最热代码路径. 一个函数在分析阶段出现的次数越多,则该函数的代码路径(code path)花费的时间占总运行时
-
GoLang逃逸分析讲解
目录 概念 逃逸分析准则 逃逸分析大致思路 概念 当一个对象的指针在被多个方法或者线程引用,称为逃逸分析, 逃逸分析决定一个变量分配在堆上还是栈上, 当然是否发生逃逸是由编译器决定的 分配栈和堆上变量的问题 1.局部变量在栈上(静态分配),函数执行完毕后,自动被栈回收,导致其他对此变量引用出现painc null 指针异常, 栈用户态实现goroutine 作为执行上下文 2.将变量 new 方式分配在堆上(动态分配),堆上有个特点,变量不会被删除,但是会造成内存异常 // 如下代码导致 程序崩
-
Golang 之协程的用法讲解
一.Golang 线程和协程的区别 备注:需要区分进程.线程(内核级线程).协程(用户级线程)三个概念. 进程.线程 和 协程 之间概念的区别 对于 进程.线程,都是有内核进行调度,有 CPU 时间片的概念,进行 抢占式调度(有多种调度算法) 对于 协程(用户级线程),这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行 协作式调度,需要协程自己主动把控
-

C++详细分析讲解函数参数的扩展
目录 一.函数参数的默认值 二.函数占位参数 三.小结 一.函数参数的默认值 C++ 中可以在函数声明时为参数提供一个默认值 当函数调用时没有提供参数的值,则使用默认值 参数的默认值必须在函数声明中指定 下面看一段代码: #include <stdio.h> int mul(int x = 0); int main(int argc, char *argv[]) { printf("%d\n", mul()); printf("%d\n", mul(-1
-
C++分析讲解类的静态成员函数如何使用
目录 一.未完成的需求 二.问题分析 三.静态成员函数 四.小结 一.未完成的需求 统计在程序运行期间某个类的对象数目 保证程序的安全性(不能使用全局变量) 随时可以获取当前对象的数目 在[C++基础入门]20.C++中类的静态成员变量中每次打印对象的个数时,都需要依赖于一个对象名,下面看一个代码: #include <stdio.h> class Test { public: static int cCount; public: Test() { cCount++; } ~Test() {
-
C语言详细分析讲解内存管理malloc realloc free calloc函数的使用
目录 C语言内存管理 一.动态空间申请 二.动态空间的扩容 三.释放内存 C语言内存管理 malloc && realloc && free && calloc c语言中为了进行动态内存管理,<stdlib.h>中提供了几个函数帮助进行内存管理. 我们知道,C语言中是没有C++中的容器或者说是python中list,set这些高级的数据结构的,我们一旦申请了一段内存空间以后这一段空间就归你了,比如我们举个例子,我们申请一个数组 int nums[
-
C++简明分析讲解引用与函数提高及重载
目录 详解引用 引用的基本使用 引用做函数参数 引用做函数返回值 常量引用 引用的本质 函数提高 函数默认值 函数占位参数 函数重载及注意事项 详解引用 引用的基本使用 语法:数据类型 &新变量名 =原来变量名 作用:给变量起别名 注意事项: 1.引用必须初始化 2.一旦初始化就不能更改(具体原因在下面引用本质上会讲到) 示例: int a = 10; int c = 20; 如果写 int &b;这是错误的,没有初始化引用,编译器不知道b指向的地址. 所以这样写 int &b=a
-
C++超详细分析讲解内联函数
目录 宏函数(带参数的宏)的缺点 inline修饰的函数就是内联函数 内联函数的特点 宏函数和内联函数的区别 宏函数(带参数的宏)的缺点 第一个问题:宏函数看起来像一个函数调用,但是会有隐藏一些难以发现的问题. 例如: #define FUN(x, y) (x * y) printf("%d", add(3, 3 + 2)) //3 * 3 + 2 = 11 以上情况可以通过加 “()” 解决: #define FUN(x, y) (x * y) printf("%d&quo
-
Kotlin中Lambda表达式与高阶函数使用分析讲解
目录 Lambda表达式 高阶函数 小结 编程语言的发展,通过需求,不断的变化出新的特性,而这些特性就会使得编程变得更加的简洁. Lambda表达式 Lambda表达式的出现,一定程度上使得函数和变量慢慢的融为一体,这样做的好处大大的方便了回调函数的使用. 在很多的情况下,其实我们的函数就只有简单的几行代码,用fun就感觉有点重了,而且有的时候这么大的函数结构用起来,并不是非常的方便. Lambda表达式,其表达式为: {变量定义 -> 代码块} 其中: lambda 函数是一个可以接收任意多个