Python 处理 Pandas DataFrame 中的行和列
目录
- 处理列
- 处理行
前言:
数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐。我们可以对行/列执行基本操作,例如选择、删除、添加和重命名。在本文中,我们使用的是nba.csv文件。
处理列
为了处理列,我们对列执行基本操作,例如选择、删除、添加和重命名。
列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列。
# Import pandas package
import pandas as pd
# 定义包含员工数据的字典
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 选择两列
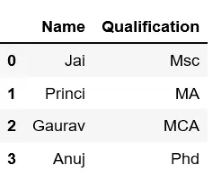
print(df[['Name', 'Qualification']])
输出:
列添加:为了在 Pandas DataFrame 中添加列,我们可以将新列表声明为列并添加到现有数据框。
# Import pandas package
import pandas as pd
# 定义包含学生数据的字典
data = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Height': [5.1, 6.2, 5.1, 5.2],
'Qualification': ['Msc', 'MA', 'Msc', 'Msc']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 声明要转换为列的列表
address = ['Delhi', 'Bangalore', 'Chennai', 'Patna']
# 使用“地址”作为列名并将其等同于列表
df['Address'] = address
# 观察结果
print(df)
输出:

有关更多示例,请参阅在 Pandas列删除中向现有 DataFrame 添加新列:为了删除 Pandas DataFrame 中的列,我们可以使用该方法。通过删除具有列名的列来删除列。drop()
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除通过的列
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# 展示
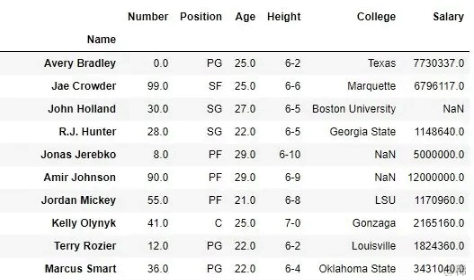
print(data)
输出:如输出图像所示,新输出没有传递的列。这些值被删除,因为轴设置为等于 1,并且由于 inplace 为 True,因此在原始数据框中进行了更改。
删除列之前的数据框- 删除列:

之后的数据框:
处理行
为了处理行,我们可以对行执行基本的操作,例如选择、删除、添加和重命名。
行选择Pandas 提供了一种从数据框中检索行的独特方法。DataFrame.loc[]方法用于从 Pandas DataFrame 中检索行。也可以通过将整数位置传递给 iloc[] 函数来选择行。
# importing pandas package
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name")
# 通过 loc 方法检索行
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
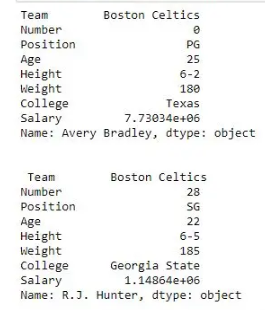
print(first, "\n\n\n", second)
输出:如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。
有关更多示例,请参阅Pandas 使用 .loc Row Addition提取行:为了在 Pandas DataFrame 中添加一行,我们可以将旧数据帧与新数据帧连接。
# importing pandas module
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv", index_col ="Name")
df.head(10)
new_row = pd.DataFrame({'Name':'Geeks', 'Team':'Boston', 'Number':3,
'Position':'PG', 'Age':33, 'Height':'6-2',
'Weight':189, 'College':'MIT', 'Salary':99999},
index =[0])
# 简单地连接两个数据框
df = pd.concat([new_row, df]).reset_index(drop = True)
df.head(5)
输出:添加行前的数据框- 添加行

后的数据框-

删除行:为了删除 Pandas DataFrame 中的一行,我们可以使用 drop() 方法。通过按索引标签删除行来删除行。
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的值
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace = True)
# 展示
data
输出:如输出图像所示,新输出没有传递的值。由于 inplace 为 True,因此删除了这些值并在原始数据框中进行了更改。
删除值之前的数据框- 删除值
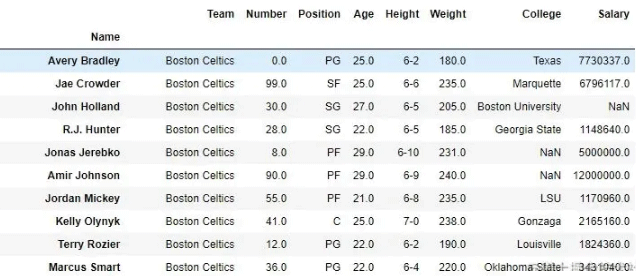
后的数据框:

到此这篇关于Python 处理 Pandas DataFrame 中的行和列的文章就介绍到这了,更多相关Python Pandas DataFrame 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python pandas DataFrame基础运算及空值填充详解
目录 前言 数据对齐 fill_value 空值api dropna fillna 总结 前言 今天我们一起来聊聊DataFrame中的索引. 上一篇文章当中我们介绍了DataFrame数据结构当中一些常用的索引的使用方法,比如iloc.loc以及逻辑索引等等.今天的文章我们来看看DataFrame的一些基本运算. 数据对齐 我们可以计算两个DataFrame的加和,pandas会自动将这两个DataFrame进行数据对齐,如果对不上的数据会被置为Nan(not a number). 首先我们来
-
python numpy中array与pandas的DataFrame转换方式
目录 numpy array与pandas的DataFrame转换 1.numpy的array转换为pandas的DataFrame 2.pandas的DataFrame转换为numpy的array Pandas DataFrame转换成Numpy中array的三种方法 1.使用DataFrame中的values方法 2.使用DataFrame中的as_matrix()方法 3.使用Numpy中的array方法 numpy array与pandas的DataFrame转换 1.numpy的arr
-
python Pandas之DataFrame索引及选取数据
目录 1.索引是什么 1.1 认识索引 1.2 自定义索引 2. 索引的简单使用 2.1 列索引 2.2 行索引 2.2.1 使用[ ] 2.2.2 使用.loc()和.iloc() 1.索引是什么 1.1 认识索引 先创建一个简单的DataFrame. myList = [['a', 10, 1.1], ['b', 20, 2.2], ['c', 30, 3.3], ['d', 40, 4.4]] df1 = pd.DataFrame(data = myList) print(df1) ---
-
Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录 一.条件筛选 二.Dataframe数据遍历 for...in...语句 iteritems()方法 iterrows()方法 itertuples()方法 一.条件筛选 查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式. 示例Dataframe如下: 单条件筛选,例如查询gender为woman的数据: df[df["gender"]=="woman"] # 或 df.loc[df["gender
-
Python pandas DataFrame数据拼接方法
目录 前言 DataFrame数据拼接方法一:使用.append()方法. DataFrame数据拼接方法二:使用.concat()方法. 补充:Python同时合并多个DataFrame 总结 前言 在pandas模块中,通常我们都需要对类型为DataFrame的数据进行操作,其中最为常见的操作便是拼接了.比如我们将两个Excel表格中的数据读入,随后拼接完成后保存进一个新的Excel表格文件中.之前查找了相关的博客, 发现网络上鱼龙混杂.有些代码完全无法执行,为了提高效率,这里做一个详细地记
-
python pandas dataframe 行列选择,切片操作方法
SQL中的select是根据列的名称来选取:Pandas则更为灵活,不但可根据列名称选取,还可以根据列所在的position(数字,在第几行第几列,注意pandas行列的position是从0开始)选取.相关函数如下: 1)loc,基于列label,可选取特定行(根据行index): 2)iloc,基于行/列的position: 3)at,根据指定行index及列label,快速定位DataFrame的元素: 4)iat,与at类似,不同的是根据position来定位的: 5)ix,为loc与i
-
Python Pandas实现DataFrame合并的图文教程
目录 一.merge(合并)的语法: 二.以关键列来合并两个dataframe 三.理解merge时数量的对齐关系 1.one-to-one 一对一关系的merge 2.one-to-many 一对多关系的merge 3.many-to-many 多对多关系的merge 四.理解left join.right join.inner join.outer join的区别 1.inner join,默认 2.left join 3. right join 4. outer join 五.如果出现非K
-
Python 处理 Pandas DataFrame 中的行和列
目录 处理列 处理行 前言: 数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐.我们可以对行/列执行基本操作,例如选择.删除.添加和重命名.在本文中,我们使用的是nba.csv文件. 处理列 为了处理列,我们对列执行基本操作,例如选择.删除.添加和重命名. 列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列. # Import pandas package import pandas as pd # 定义包含员工数据的字典 data =
-
Pandas.DataFrame删除指定行和列(drop)的实现
目录 DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFrame指定的列删除 按列名指定(列标签) 按列号指定 多行多列的删除 使用drop()方法删除pandas.DataFrame的行和列. 在0.21.0版之前,请使用参数labels和axis指定行和列.从0.21.0开始,可以使用index或columns. 在此,将对以下内容进行说明. DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFra
-
在Pandas DataFrame中插入一列的方法实例
目录 引言 示例1:插入新列作为第一列 示例2:插入新列作为中间列 示例3:插入新列作为最后一列 补充:按条件选择分组分别赋值 总结 引言 通常,您可能希望在 Pandas DataFrame 中插入一个新列.幸运的是,使用 pandas insert()函数很容易做到这一点,该函数使用以下语法: insert(loc, column, value, allow_duplicates=False) 在哪里: loc: 插入列的索引.第一列是 0. column: 赋予新列的名称. value:
-
python中pandas.DataFrame对行与列求和及添加新行与列示例
本文介绍的是python中pandas.DataFrame对行与列求和及添加新行与列的相关资料,下面话不多说,来看看详细的介绍吧. 方法如下: 导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFrame(np.random.randn(4, 5), columns=['A', 'B', 'C', 'D', 'E']) DataFrame数据预览: A
-
pandas.DataFrame中提取特定类型dtype的列
目录 select_dtypes()的基本用法 指定要提取的类型:参数include 指定要排除的类型:参数exclude pandas.DataFrame为每一列保存一个数据类型dtype. 要仅提取(选择)特定数据类型为dtype的列,请使用pandas.DataFrame的select_dtypes()方法. 以带有各种数据类型的列的pandas.DataFrame为例. import pandas as pd df = pd.DataFrame({'a': [1, 2, 1, 3],
-
如何更改 pandas dataframe 中两列的位置
如何更改 pandas dataframe 中两列的位置: 把其中的某列移到第一列的位置. 原来的 df 是: df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01.csv') Net Upper Lower Mid Zsore Answer option More than once a day 0% 0.22% -0.12% 2 65 Once a day 0% 0.32% -0.19% 3 45 Sever
-
pandas.DataFrame 根据条件新建列并赋值的方法
实例如下所示: import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'], 'year': [2016,2016,2015,2017,2016, 2016], 'population': [2100, 2300, 1000, 700, 500, 500]} frame = pd.DataFrame(
-
Pandas DataFrame中的tuple元素遍历的实现
pandas中遍历dataframe的每一个元素 假如有一个需求场景需要遍历一个csv或excel中的每一个元素,判断这个元素是否含有某个关键字 那么可以用python的pandas库来实现. 方法一: pandas的dataframe有一个很好用的函数applymap,它可以把某个函数应用到dataframe的每一个元素上,而且比常规的for循环去遍历每个元素要快很多.如下是相关代码: import pandas as pd data = [["str","ewt"
-
pandas dataframe 中的explode函数用法详解
在使用 pandas 进行数据分析的过程中,我们常常会遇到将一行数据展开成多行的需求,多么希望能有一个类似于 hive sql 中的 explode 函数. 这个函数如下: Code # !/usr/bin/env python # -*- coding:utf-8 -*- # create on 18/4/13 import pandas as pd def dataframe_explode(dataframe, fieldname): temp_fieldname = fieldname
-
详解pandas.DataFrame中删除包涵特定字符串所在的行
你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除包涵特定字符串所在的行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!