python回归分析逻辑斯蒂模型之多分类任务详解
目录
- 逻辑斯蒂回归模型多分类任务
- 1.ovr策略
- 2.one vs one策略
- 3.softmax策略
- 逻辑斯蒂回归模型多分类案例实现
逻辑斯蒂回归模型多分类任务
上节中,我们使用逻辑斯蒂回归完成了二分类任务,针对多分类任务,我们可以采用以下措施,进行分类。
我们以三分类任务为例,类别分别为a,b,c。
1.ovr策略
我们可以训练a类别,非a类别的分类器,确认未来的样本是否为a类; 同理,可以训练b类别,非b类别的分类器,确认未来的样本是否为b类; 同理,可以训练c类别,非c类别的分类器,确认未来的样本是否为c类;这样我们通过增加分类器的数量,K类训练K个分类器,完成多分类任务。
2.one vs one策略
我们将样本根据类别进行划分,分别训练a与b、a与c、b与c之间的分类器,通过多个分类器判断结果的汇总打分,判断未来样本的类别。 同样使用了增加分类的数量的方法,需要注意训练样本的使用方法不同,K类训练K(K-1)/2个分类器,完成多分类任务
3.softmax策略
通过计算各个类别的概率,比较最高概率后,确定最终的类别。
对于类别互斥的情况,建议使用softmax,而不同类别之间关联性较强时,建议使用增加多个分类器的策略。
逻辑斯蒂回归模型多分类案例实现
本例我们使用sklearn数据集,鸢尾花数据。
1.加载数据
- 样本总量:150组
- 预测类别:山鸢尾,杂色鸢尾,弗吉尼亚鸢尾三类,各50组。
- 样本特征4种:花萼长度sepal length (cm) 、花萼宽度sepal width (cm)、花瓣长度petal length (cm)、花瓣宽度petal width (cm)。
2.使用seaborn提供的pairplot方法,可视化展示特征与标签
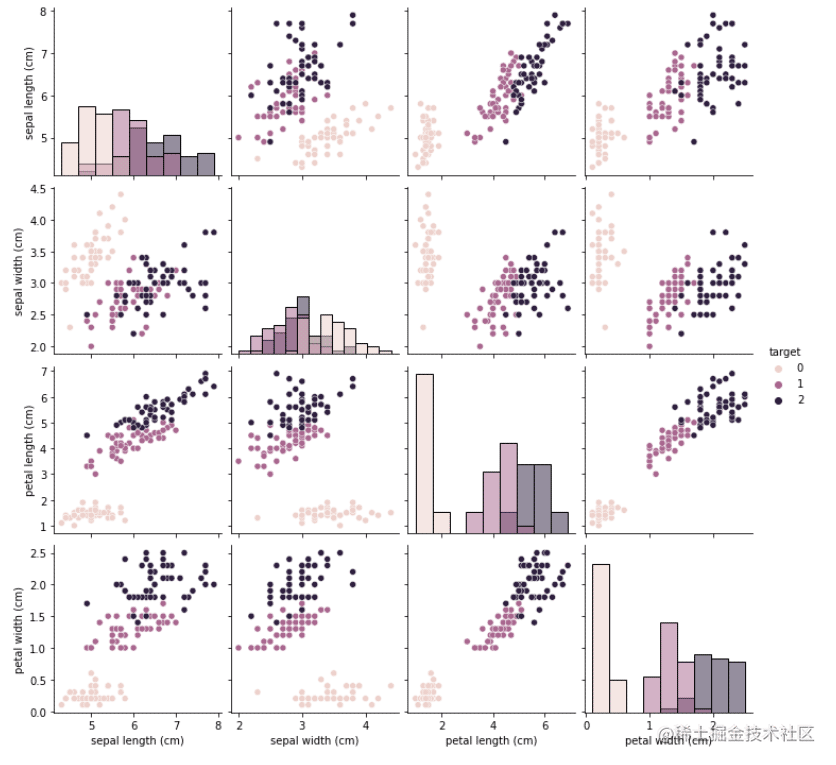
3.训练模型
from sklearn.datasets import load_iris
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
#加载数据
data = load_iris()
iris_target = data.target #
iris_df = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式
iris_df['target'] = iris_target
## 特征与标签组合的散点可视化
sns.pairplot(data=iris_df,diag_kind='hist', hue= 'target')
plt.show()
#划分数据集
X=iris_df.iloc[:,:-1]
y=iris_df.iloc[:,-1]
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
## 创建逻辑回归模型
clf = LogisticRegression(random_state=0, solver='lbfgs')
''' 优化算法选择参数:solver\
solver参数决定了我们对逻辑回归损失函数的优化方法,有4种算法可以选择,分别是:
a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
从上面的描述可以看出,newton-cg, lbfgs和sag这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear通吃L1正则化和L2正则化。
同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
从上面的描述,大家可能觉得,既然newton-cg, lbfgs和sag这么多限制,如果不是大样本,我们选择liblinear不就行了嘛!错,因为liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。郁闷的是liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。
'''
clf.fit(x_train, y_train)
## 查看自变量对应的系数w
print('the weight of Logistic Regression:\n',clf.coef_)
## 查看常数项对应的系数w0
print('the intercept(w0) of Logistic Regression:\n',clf.intercept_)
#模型1的变量重要性排序
coef_c1 = pd.DataFrame({'var' : pd.Series(x_test.columns),
'coef_abs' : abs(pd.Series(clf.coef_[0].flatten()))
})
coef_c1 = coef_c1.sort_values(by = 'coef_abs',ascending=False)
print(coef_c1)
#模型2的变量重要性排序
coef_c2 = pd.DataFrame({'var' : pd.Series(x_test.columns),
'coef_abs' : abs(pd.Series(clf.coef_[1].flatten()))
})
coef_c2 = coef_c2.sort_values(by = 'coef_abs',ascending=False)
print(coef_c2)
#模型3的变量重要性排序
coef_c3 = pd.DataFrame({'var' : pd.Series(x_test.columns),
'coef_abs' : abs(pd.Series(clf.coef_[2].flatten()))
})
coef_c3 = coef_c3.sort_values(by = 'coef_abs',ascending=False)
print(coef_c3)
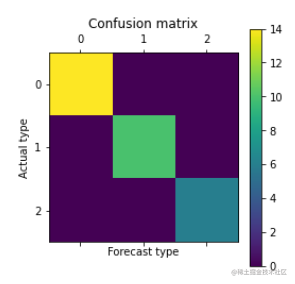
4.对模型进行评价:模型得分、交叉验证得分、混淆矩阵
from sklearn.metrics import accuracy_score,recall_score
## 模型评价
score = clf.score(x_train,y_train)#Return the mean accuracy on the given test data and labels.
print(score)#0.628125
#模型在训练集上的得分
train_score = accuracy_score(y_train,clf.predict(x_train))
print(train_score)#0.628125
#模型在测试集上的得分
test_score = clf.score(x_test,y_test)
print(test_score)#0.6
#预测
y_predict = clf.predict(x_test)
#训练集的召回率
train_recall = recall_score(y_train, clf.predict(x_train), average='macro')
print("训练集召回率",train_recall)#0.47934382086167804
#测试集的召回率
test_recall = recall_score(y_test, clf.predict(x_test), average='macro')
print("测试集召回率",test_recall)#0.5002736726874658
from sklearn.metrics import classification_report
print('测试数据指标:\n',classification_report(y_test,y_predict,digits=4))
#k-fold交叉验证得分
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clf,x_train,y_train,cv=10,scoring='accuracy')
print('十折交叉验证:每一次的得分',scores)
#结果:每一次的得分 [0.59375 0.59375 0.6875 0.59375 0.53125 0.5625 0.65625 0.625 0.71875 0.625 ]
print('十折交叉验证:平均得分', scores.mean())
#结果:平均得分 0.61875
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix
import pandas as pd
labelEncoder = LabelEncoder()
labelEncoder.fit(y)##对变量y进行硬编码,将标签变为数字
cm = confusion_matrix(y_test, y_predict)
cm_pd = pd.DataFrame(data = cm,columns=labelEncoder.classes_, index=labelEncoder.classes_)
print("混淆矩阵")
print(cm_pd)
import matplotlib.pyplot as plt
plt.matshow(confusion_matrix(y_test, y_predict))
plt.title('Confusion matrix')
plt.colorbar()
plt.ylabel('Actual type') #实际类型
plt.xlabel('Forecast type') #预测类型
以上就是python回归分析逻辑斯蒂模型之多分类任务详解的详细内容,更多关于python逻辑斯蒂模型的资料请关注我们其它相关文章!
相关推荐
-
关于多元线性回归分析——Python&SPSS
原始数据在这里 1.观察数据 首先,用Pandas打开数据,并进行观察. import numpy import pandas as pd import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('Folds5x2_pp.csv') data.head() 会看到数据如下所示: 这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力).我
-

使用python画出逻辑斯蒂映射(logistic map)中的分叉图案例
逻辑斯蒂映射在混沌数学中是一个很经典的例子,它可以说明混沌可以从很简单的非线性方程中产生. 逻辑斯蒂映射公式如下: x_n表示当前人口与最大人口数量的比值,mu为参数,相当于人口增长速率. 分叉图描绘的是不同mu情况下,x收敛的值的分布图. 参考地址 python代码如下: from tqdm import tqdm import matplotlib.pyplot as plt import numpy as np def LogisticMap(): mu = np.arange(2, 4,
-
Python 线性回归分析以及评价指标详解
废话不多说,直接上代码吧! """ # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据集中的特征值总共10项, 如下: # 年龄 # 性别 #体质指数 #血压 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围. #验证就会发现任
-
PyTorch零基础入门之逻辑斯蒂回归
目录 学习总结 一.sigmoid函数 二.和Linear的区别 三.逻辑斯蒂回归(分类)PyTorch实现 Reference 学习总结 (1)和上一讲的模型训练是类似的,只是在线性模型的基础上加个sigmoid,然后loss函数改为交叉熵BCE函数(当然也可以用其他函数),另外一开始的数据y_data也从数值改为类别0和1(本例为二分类,注意x_data和y_data这里也是矩阵的形式). 一.sigmoid函数 logistic function是一种sigmoid函数(还有其他sigmo
-
python 线性回归分析模型检验标准--拟合优度详解
建立完回归模型后,还需要验证咱们建立的模型是否合适,换句话说,就是咱们建立的模型是否真的能代表现有的因变量与自变量关系,这个验证标准一般就选用拟合优度. 拟合优度是指回归方程对观测值的拟合程度.度量拟合优度的统计量是判定系数R^2.R^2的取值范围是[0,1].R^2的值越接近1,说明回归方程对观测值的拟合程度越好:反之,R^2的值越接近0,说明回归方程对观测值的拟合程度越差. 拟合优度问题目前还没有找到统一的标准说大于多少就代表模型准确,一般默认大于0.8即可 拟合优度的公式:R^2 = 1
-
python回归分析逻辑斯蒂模型之多分类任务详解
目录 逻辑斯蒂回归模型多分类任务 1.ovr策略 2.one vs one策略 3.softmax策略 逻辑斯蒂回归模型多分类案例实现 逻辑斯蒂回归模型多分类任务 上节中,我们使用逻辑斯蒂回归完成了二分类任务,针对多分类任务,我们可以采用以下措施,进行分类. 我们以三分类任务为例,类别分别为a,b,c. 1.ovr策略 我们可以训练a类别,非a类别的分类器,确认未来的样本是否为a类: 同理,可以训练b类别,非b类别的分类器,确认未来的样本是否为b类: 同理,可以训练c类别,非c类别的分类器,确认
-
Python实现随机森林RF模型超参数的优化详解
目录 1 代码分段讲解 1.1 数据与模型准备 1.2 超参数范围给定 1.3 超参数随机匹配择优 1.4 超参数遍历匹配择优 1.5 模型运行与精度评定 2 完整代码 本文介绍基于Python的随机森林(Random Forest,RF)回归代码,以及模型超参数(包括决策树个数与最大深度.最小分离样本数.最小叶子节点样本数.最大分离特征数等)自动优化的代码. 本文是在上一篇文章Python实现随机森林RF并对比自变量的重要性的基础上完成的,因此本次仅对随机森林模型超参数自动择优部分的代码加以详
-
Python函数参数匹配模型通用规则keyword-only参数详解
Python3对函数参数的排序规则更加通用化了,即Python3 keyword-only参数,该参数即为必须只按照关键字传递而不会有一个位置参数来填充的参数.该规则在处理人一多个参数是很有用的. keyword-only kword_only(1, 2, 3, c=4) print('-' * 20) kword_only(a=1, c=3) 示例结果: 1 (2, 3) 4 -------------------- 1 () 3 在 *args 之后的参数都需要在调用中使用关键字的方式传递,
-
Python机器学习应用之基于线性判别模型的分类篇详解
目录 一.Introduction 1 LDA的优点 2 LDA的缺点 3 LDA在模式识别领域与自然语言处理领域的区别 二.Demo 三.基于LDA 手写数字的分类 四.小结 一.Introduction 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. LDA的思想可以用一句话概括,就是"投影后类内方差最小,类间方
-
python脚本调用iftop 统计业务应用流量的思路详解
因公司服务器上部署应用较多,在有大并发访问.业务逻辑有问题的情况下反复互相调用或者有异常流量访问的时候,需要对业务应用进行故障定位,所以利用python调用iftop命令来获取应用进程流量,结合zabbix,可帮助定位分析问题.,以下是脚本内容,大概思路是: 利用iftop命令 iftop -t -P -N -n -s 2 来获取流量信息 对获取的流量信息进行处理,单位换算,同一个应用程序的所有链接流量进行合计(因为一个应用会有很多链接,每一个链接都有流量,全部相加即可得出这个应用的总流量) #
-
Tensorflow 使用pb文件保存(恢复)模型计算图和参数实例详解
一.保存: graph_util.convert_variables_to_constants 可以把当前session的计算图串行化成一个字节流(二进制),这个函数包含三个参数:参数1:当前活动的session,它含有各变量 参数2:GraphDef 对象,它描述了计算网络 参数3:Graph图中需要输出的节点的名称的列表 返回值:精简版的GraphDef 对象,包含了原始输入GraphDef和session的网络和变量信息,它的成员函数SerializeToString()可以把这些信息串行
-
tensorflow的ckpt及pb模型持久化方式及转化详解
使用tensorflow训练模型的时候,模型持久化对我们来说非常重要. 如果我们的模型比较复杂,需要的数据比较多,那么在模型的训练时间会耗时很长.如果在训练过程中出现了模型不可预期的错误,导致训练意外终止,那么我们将会前功尽弃.为了解决这一问题,我们可以使用模型持久化(保存为ckpt文件格式)来保存我们在训练过程中的临时数据.. 如果我们训练出的模型需要提供给用户做离线预测,那么我们只需要完成前向传播过程.这个时候我们就可以使用模型持久化(保存为pb文件格式)来只保存前向传播过程中的变量并将变量
-
Python中关于元组 集合 字符串 函数 异常处理的全面详解
目录 元组 集合 字符串 1.字符串的驻留机制 2.常用操作 函数 1.函数的优点: 2.函数的创建:def 函数名([输入参数]) 3.函数的参数传递: 4.函数的返回值: 5.函数的参数定义: 6.变量的作用区域 7.递归函数:函数体内套用该函数本身 8.将函数存储在模块中 9.函数编写指南: Bug 1.Bug常见类型 2.常见异常类型 3.python异常处理机制 pycharm开发环境的调试 编程思想 (1)两种编程思想 (2)类和对象的创建 元组 元组是不可变序列 多任务环境下,同时