详解Pytorch中的tensor数据结构
目录
- torch.Tensor
- Tensor 数据类型
- view 和 reshape 的区别
- Tensor 与 ndarray
- 创建 Tensor
- 传入维度的方法
torch.Tensor
torch.Tensor 是一种包含单一数据类型元素的多维矩阵,类似于 numpy 的 array。
Tensor 可以使用 torch.tensor() 转换 Python 的 list 或序列数据生成,生成的是dtype 默认是 torch.FloatTensor。
注意
torch.tensor()总是拷贝 data。如果你有一个 Tensor data 并且仅仅想改变它的requires_grad属性,可用requires_grad_()或者detach()来避免拷贝。如果你有一个numpy数组并且想避免拷贝,请使用torch.as_tensor()。
1,指定数据类型的 Tensor 可以通过传递参数 torch.dtype 和/或者 torch.device 到构造函数生成:
注意为了改变已有的 tensor 的 torch.device 和/或者 torch.dtype, 考虑使用
to()方法.
>>> torch.ones([2,3], dtype=torch.float64, device="cuda:0")
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0', dtype=torch.float64)
>>> torch.ones([2,3], dtype=torch.float32)
tensor([[1., 1., 1.],
[1., 1., 1.]])
2,Tensor 的内容可以通过 Python索引或者切片访问以及修改:
>>> matrix = torch.tensor([[2,3,4],[5,6,7]])
>>> print(matrix[1][2])
tensor(7)
>>> matrix[1][2] = 9
>>> print(matrix)
tensor([[2, 3, 4],
[5, 6, 9]])
3,使用 torch.Tensor.item() 或者 int() 方法从只有一个值的 Tensor中获取 Python Number:
>>> x = torch.tensor([[4.5]]) >>> x tensor([[4.5000]]) >>> x.item() 4.5 >>> int(x) 4
4,Tensor可以通过参数 requires_grad=True 创建, 这样 torch.autograd 会记录相关的运算实现自动求导:
>>> x = torch.tensor([[1., -1.], [1., 1.]], requires_grad=True) >>> out = x.pow(2).sum() >>> out.backward() >>> x.grad tensor([[ 2.0000, -2.0000], [ 2.0000, 2.0000]])
5,每一个 tensor都有一个相应的 torch.Storage 保存其数据。tensor 类提供了一个多维的、strided 视图, 并定义了数值操作。
Tensor 数据类型
Torch 定义了七种 CPU tensor 类型和八种 GPU tensor 类型:

torch.Tensor 是默认的 tensor 类型(torch.FloatTensor)的简称,即 32 位浮点数数据类型。
Tensor 的属性
Tensor 有很多属性,包括数据类型、Tensor 的维度、Tensor 的尺寸。
- 数据类型:可通过改变 torch.tensor() 方法的 dtype 参数值,来设定不同的 tensor 数据类型。
- 维度:不同类型的数据可以用不同维度(dimension)的张量来表示。标量为 0 维张量,向量为 1 维张量,矩阵为 2 维张量。彩色图像有 rgb 三个通道,可以表示为 3 维张量。视频还有时间维,可以表示为 4 维张量,有几个中括号 [ 维度就是几。可使用 dim() 方法 获取 tensor 的维度。
- 尺寸:可以使用 shape属性或者 size()方法查看张量在每一维的长度,可以使用 view()方法或者reshape() 方法改变张量的尺寸。
样例代码如下:
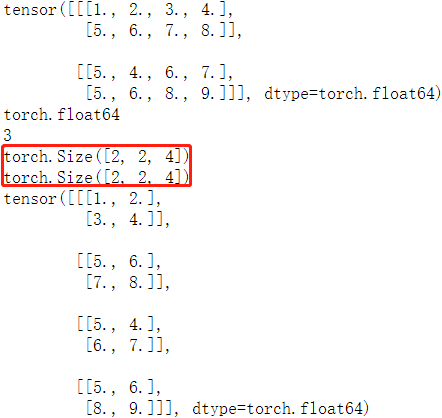
matrix = torch.tensor([[[1,2,3,4],[5,6,7,8]],
[[5,4,6,7], [5,6,8,9]]], dtype = torch.float64)
print(matrix) # 打印 tensor
print(matrix.dtype) # 打印 tensor 数据类型
print(matrix.dim()) # 打印 tensor 维度
print(matrix.size()) # 打印 tensor 尺寸
print(matrix.shape) # 打印 tensor 尺寸
matrix2 = matrix.view(4, 2, 2) # 改变 tensor 尺寸
print(matrix2)
程序输出结果如下:
view 和 reshape 的区别
两个方法都是用来改变 tensor 的 shape,view() 只适合对满足连续性条件(contiguous)的 tensor 进行操作,而 reshape() 同时还可以对不满足连续性条件的 tensor 进行操作。在满足 tensor 连续性条件(contiguous)时,a.reshape() 返回的结果与a.view() 相同,都不会开辟新内存空间;不满足 contiguous 时, 直接使用 view() 方法会失败,reshape() 依然有用,但是会重新开辟内存空间,不与之前的 tensor 共享内存,即返回的是 ”副本“(等价于先调用 contiguous() 方法再使用 view() 方法)。
更多理解参考这篇文章
Tensor 与 ndarray
1,张量和 numpy 数组。可以用 .numpy() 方法从 Tensor 得到 numpy 数组,也可以用 torch.from_numpy 从 numpy 数组得到Tensor。这两种方法关联的 Tensor 和 numpy 数组是共享数据内存的。可以用张量的 clone方法拷贝张量,中断这种关联。
arr = np.random.rand(4,5) print(type(arr)) tensor1 = torch.from_numpy(arr) print(type(tensor1)) arr1 = tensor1.numpy() print(type(arr1)) """ <class 'numpy.ndarray'> <class 'torch.Tensor'> <class 'numpy.ndarray'> """
2,item() 方法和 tolist() 方法可以将张量转换成 Python 数值和数值列表
# item方法和tolist方法可以将张量转换成Python数值和数值列表 scalar = torch.tensor(5) # 标量 s = scalar.item() print(s) print(type(s)) tensor = torch.rand(3,2) # 矩阵 t = tensor.tolist() print(t) print(type(t)) """ 1.0 <class 'float'> [[0.8211846351623535, 0.20020723342895508], [0.011571824550628662, 0.2906131148338318]] <class 'list'> """
创建 Tensor
创建 tensor ,可以传入数据或者维度,torch.tensor() 方法只能传入数据,torch.Tensor() 方法既可以传入数据也可以传维度,强烈建议 tensor() 传数据,Tensor() 传维度,否则易搞混。
传入维度的方法
| 方法名 | 方法功能 | 备注 |
|---|---|---|
torch.rand(*sizes, out=None) → Tensor |
返回一个张量,包含了从区间 [0, 1) 的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。 |
推荐 |
torch.randn(*sizes, out=None) → Tensor |
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。 | 不推荐 |
torch.normal(means, std, out=None) → Tensor |
返回一个张量,包含了从指定均值 means 和标准差 std 的离散正态分布中抽取的一组随机数。标准差 std 是一个张量,包含每个输出元素相关的正态分布标准差。 |
多种形式,建议看源码 |
torch.rand_like(a) |
根据数据 a 的 shape 来生成随机数据 |
不常用 |
torch.randint(low=0, high, size) |
生成指定范围(low, hight)和 size 的随机整数数据 |
常用 |
torch.full([2, 2], 4) |
生成给定维度,全部数据相等的数据 | 不常用 |
torch.arange(start=0, end, step=1, *, out=None) |
生成指定间隔的数据 | 易用常用 |
torch.ones(*size, *, out=None) |
生成给定 size 且值全为1 的矩阵数据 | 简单 |
zeros()/zeros_like()/eye() |
全 0 的 tensor 和 对角矩阵 |
简单 |
样例代码:
>>> torch.rand([1,1,3,3])
tensor([[[[0.3005, 0.6891, 0.4628],
[0.4808, 0.8968, 0.5237],
[0.4417, 0.2479, 0.0175]]]])
>>> torch.normal(2, 3, size=(1, 4))
tensor([[3.6851, 3.2853, 1.8538, 3.5181]])
>>> torch.full([2, 2], 4)
tensor([[4, 4],
[4, 4]])
>>> torch.arange(0,10,2)
tensor([0, 2, 4, 6, 8])
>>> torch.eye(3,3)
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
参考资料
详解torch.rand和torch.randn和torch.normal和linespace()
到此这篇关于Pytorch中的tensor数据结构的文章就介绍到这了,更多相关Pytorch tensor数据结构内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch创建tensor函数详情
目录 1.通过复制数据构造张量 1.1 torch.tensor() 1.2 将numpy的ndarray转为tensor 2.生成全0或者全1的tensor 3.生成序列 3.1. 生成一个指定步长的等差序列 3.2 生成一个指定步数的等差数列 4.生成指定大小的单位矩阵 5.生成一个指定大小张量 6. 创建一个指定大小的张量.张量的数据是填充的指定值 1.通过复制数据构造张量 1.1 torch.tensor() torch.tensor([[0.1, 1.2], [2.2, 3.1], [
-
pytorch: Parameter 的数据结构实例
一般来说,pytorch 的Parameter是一个tensor,但是跟通常意义上的tensor有些不一样 1) 通常意义上的tensor 仅仅是数据 2) 而Parameter所对应的tensor 除了包含数据之外,还包含一个属性:requires_grad(=True/False) 在Parameter所对应的tensor中获取纯数据,可以通过以下操作: param_data = Parameter.data 测试代码: #-*-coding:utf-8-*- import torch im
-

详解Pytorch中的tensor数据结构
目录 torch.Tensor Tensor 数据类型 view 和 reshape 的区别 Tensor 与 ndarray 创建 Tensor 传入维度的方法 torch.Tensor torch.Tensor 是一种包含单一数据类型元素的多维矩阵,类似于 numpy 的 array.Tensor 可以使用 torch.tensor() 转换 Python 的 list 或序列数据生成,生成的是dtype 默认是 torch.FloatTensor. 注意 torch.tensor() 总是
-
详解pytorch中squeeze()和unsqueeze()函数介绍
squeeze的用法主要就是对数据的维度进行压缩或者解压. 先看torch.squeeze() 这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,比如是一行或者一列这种,一个一行三列(1,3)的数去掉第一个维数为一的维度之后就变成(3)行.squeeze(a)就是将a中所有为1的维度删掉.不为1的维度没有影响.a.squeeze(N) 就是去掉a中指定的维数为一的维度.还有一种形式就是b=torch.squeeze(a,N) a中去掉指定的定的维数为一的维度. 再看torch.unsque
-
详解PyTorch中Tensor的高阶操作
条件选取:torch.where(condition, x, y) → Tensor 返回从 x 或 y 中选择元素的张量,取决于 condition 操作定义: 举个例子: >>> import torch >>> c = randn(2, 3) >>> c tensor([[ 0.0309, -1.5993, 0.1986], [-0.0699, -2.7813, -1.1828]]) >>> a = torch.ones(2,
-
PyTorch中torch.tensor与torch.Tensor的区别详解
PyTorch最近几年可谓大火.相比于TensorFlow,PyTorch对于Python初学者更为友好,更易上手. 众所周知,numpy作为Python中数据分析的专业第三方库,比Python自带的Math库速度更快.同样的,在PyTorch中,有一个类似于numpy的库,称为Tensor.Tensor自称为神经网络界的numpy. 一.numpy和Tensor二者对比 对比项 numpy Tensor 相同点 可以定义多维数组,进行切片.改变维度.数学运算等 可以定义多维数组,进行切片.改变
-
详解pytorch tensor和ndarray转换相关总结
在使用pytorch的时候,经常会涉及到两种数据格式tensor和ndarray之间的转换,这里总结一下两种格式的转换: 1. tensor cpu 和tensor gpu之间的转化: tensor cpu 转为tensor gpu: tensor_gpu = tensor_cpu.cuda() >>> tensor_cpu = torch.ones((2,2)) tensor([[1., 1.], [1., 1.]]) >>> tensor_gpu = tensor_
-
详解Angular中$cacheFactory缓存的使用
最近在学习使用angular,慢慢从jquery ui转型到用ng开发,发现了很多不同点,继续学习吧: 首先创建一个服务,以便在项目中的controller中引用,服务有几种存在形式,factory();service();constant();value();provider();其中provider是最基础的,其他服务都是基于这个写的,具体区别这里就不展开了,大家可以看看源码:服务是各个controller之间通话的重要形式,在实际项目中会用的很多,下面是代码: angular.module
-
详解Java中hashCode的作用
详解Java中hashCode的作用 以下是关于HashCode的官方文档定义: hashcode方法返回该对象的哈希码值.支持该方法是为哈希表提供一些优点,例如,java.util.Hashtable 提供的哈希表. hashCode 的常规协定是: 在 Java 应用程序执行期间,在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是对象上 equals 比较中所用的信息没有被修改.从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致. 如果根据
-
详解Java中AbstractMap抽象类
jdk1.8.0_144 下载地址:http://www.jb51.net/softs/551512.html AbstractMap抽象类实现了一些简单且通用的方法,本身并不难.但在这个抽象类中有两个方法非常值得关注,keySet和values方法源码的实现可以说是教科书式的典范. 抽象类通常作为一种骨架实现,为各自子类实现公共的方法.上一篇我们讲解了Map接口,此篇对AbstractMap抽象类进行剖析研究. Java中Map类型的数据结构有相当多,AbstractMap作为它们的骨架实现实
-
详解python中GPU版本的opencv常用方法介绍
引言 本篇是以python的视角介绍相关的函数还有自我使用中的一些问题,本想在这篇之前总结一下opencv编译的全过程,但遇到了太多坑,暂时不太想回看做过的笔记,所以这里主要总结python下GPU版本的opencv. 主要函数说明 threshold():二值化,但要指定设定阈值 blendLinear():两幅图片的线形混合 calcHist() createBoxFilter ():创建一个规范化的2D框过滤器 canny边缘检测 createGaussianFilter():创建一个Ga
-
详解Python 中的容器 collections
写在之前 我们都知道 Python 中内置了许多标准的数据结构,比如列表,元组,字典等.与此同时标准库还提供了一些额外的数据结构,我们可以基于它们创建所需的新数据结构. Python 附带了一个「容器」模块 collections,它包含了很多的容器数据类型,今天我们来讨论其中几个常用的容器数据类型,掌握了这几个可以减少我们重复造轮子所带来的烦扰. namedtuple 相信你已经熟悉了元组.一个元组相当于一个不可变的列表,你可以存储一个数据的序列.这里要说的 namedtuple(命名元组)和