关于PyTorch 自动求导机制详解
自动求导机制
从后向中排除子图
每个变量都有两个标志:requires_grad和volatile。它们都允许从梯度计算中精细地排除子图,并可以提高效率。
requires_grad
如果有一个单一的输入操作需要梯度,它的输出也需要梯度。相反,只有所有输入都不需要梯度,输出才不需要。如果其中所有的变量都不需要梯度进行,后向计算不会在子图中执行。
>>> x = Variable(torch.randn(5, 5)) >>> y = Variable(torch.randn(5, 5)) >>> z = Variable(torch.randn(5, 5), requires_grad=True) >>> a = x + y >>> a.requires_grad False >>> b = a + z >>> b.requires_grad True
这个标志特别有用,当您想要冻结部分模型时,或者您事先知道不会使用某些参数的梯度。
autograd是专门为了BP算法设计的,所以这autograd只对输出值为标量的有用,因为损失函数的输出是一个标量。如果y是一个向量,那么backward()函数就会失效。
model = torchvision.models.resnet18(pretrained=True) for param in model.parameters(): param.requires_grad = False # Replace the last fully-connected layer # Parameters of newly constructed modules have requires_grad=True by default model.fc = nn.Linear(512, 100) # Optimize only the classifier optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
上面的optim.SGD()只需要传入需要优化的参数即可。
volatile
纯粹的inference模式(可以理解为只需要进行前向)下推荐使用volatile,当你确定你甚至不会调用.backward()时。它比任何其他自动求导的设置更有效——它将使用绝对最小的内存来评估模型。volatile也决定了require_grad is False。
volatile不同于require_grad的传递。如果一个操作甚至只有有一个volatile的输入,它的输出也将是volatile。Volatility比“不需要梯度”更容易传递——只需要一个volatile的输入即可得到一个volatile的输出,相对的,需要所有的输入“不需要梯度”才能得到不需要梯度的输出。使用volatile标志,您不需要更改模型参数的任何设置来用于inference。创建一个volatile的输入就够了,这将保证不会保存中间状态。
>>> regular_input = Variable(torch.randn(5, 5)) >>> volatile_input = Variable(torch.randn(5, 5), volatile=True) >>> model = torchvision.models.resnet18(pretrained=True) >>> model(regular_input).requires_grad True >>> model(volatile_input).requires_grad False >>> model(volatile_input).volatile True >>> model(volatile_input).creator is None True
自动求导如何编码历史信息
每个变量都有一个.creator属性,它指向把它作为输出的函数。这是一个由Function对象作为节点组成的有向无环图(DAG)的入口点,它们之间的引用就是图的边。每次执行一个操作时,一个表示它的新Function就被实例化,它的forward()方法被调用,并且它输出的Variable的创建者被设置为这个Function。然后,通过跟踪从任何变量到叶节点的路径,可以重建创建数据的操作序列,并自动计算梯度。
variable和function它们是彼此不分开的,先上图:
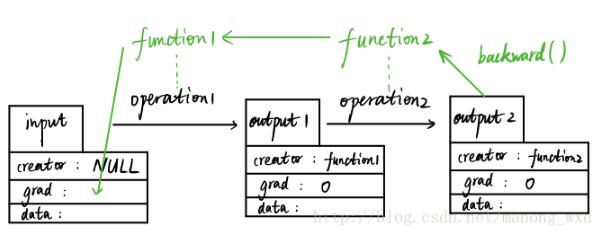
如图,假设我们有一个输入变量input(数据类型为Variable)input是用户输入的,所以其创造者creator为null值,input经过第一个数据操作operation1(比如加减乘除运算)得到output1变量(数据类型仍为Variable),这个过程中会自动生成一个function1的变量(数据类型为Function的一个实例),而output1的创造者就是这个function1。随后,output1再经过一个数据操作生成output2,这个过程也会生成另外一个实例function2,output2的创造者creator为function2。
在这个向前传播的过程中,function1和function2记录了数据input的所有操作历史,当output2运行其backward函数时,会使得function2和function1自动反向计算input的导数值并存储在grad属性中。
creator为null的变量才能被返回导数,比如input,若把整个操作流看成是一张图(Graph),那么像input这种creator为null的被称之为图的叶子(graph leaf)。而creator非null的变量比如output1和output2,是不能被返回导数的,它们的grad均为0。所以只有叶子节点才能被autograd。
>>> from torch.autograd import Variable >>> import torch >>> x = Variable(torch.ones(2), requires_grad = >>> True) >>> z=4*x*x >>> y=z.norm() >>> y Variable containing: 5.6569 [torch.FloatTensor of size 1] >>> y.backward() >>> x.grad Variable containing: 5.6569 5.6569 [torch.FloatTensor of size 2] >>> z.grad >>> y.grad
Variable上的In-place操作
in-place计算,类似'+='运算,表示内部直接替换,in-place操作都使用_作为后缀。例如,x.copy_(y)
>>> a = torch.Tensor(3,4) >>> a 0 0 0 0 0 0 0 0 0 0 0 0 [torch.FloatTensor of size 3x4] >>> a.fill_(2.5) 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 [torch.FloatTensor of size 3x4] >>> b = a.add(4.0) >>> b 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 [torch.FloatTensor of size 3x4] >>> a 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 2.5000 [torch.FloatTensor of size 3x4] >>> c = a.add_(4.0) >>> c 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 [torch.FloatTensor of size 3x4] >>> a 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 6.5000 [torch.FloatTensor of size 3x4]
在自动求导中支持in-place操作是一件很困难的事情,我们在大多数情况下都不鼓励使用它们。Autograd的缓冲区释放和重用非常高效,并且很少场合下in-place操作能实际上明显降低内存的使用量。除非您在内存压力很大的情况下,否则您可能永远不需要使用它们。
限制in-place操作适用性主要有两个原因:
1.覆盖梯度计算所需的值。这就是为什么变量不支持log_。它的梯度公式需要原始输入,而虽然通过计算反向操作可以重新创建它,但在数值上是不稳定的,并且需要额外的工作,这往往会与使用这些功能的目的相悖。
2.每个in-place操作实际上需要实现重写计算图。不合适的版本只需分配新对象并保留对旧图的引用,而in-place操作则需要将所有输入的creator更改为表示此操作的Function。这就比较棘手,特别是如果有许多变量引用相同的存储(例如通过索引或转置创建的),并且如果被修改输入的存储被任何其他Variable引用,则in-place函数实际上会抛出错误。
In-place正确性检查
每个变量保留有version counter,它每次都会递增,当在任何操作中被使用时。当Function保存任何用于后向的tensor时,还会保存其包含变量的version counter。一旦访问self.saved_tensors,它将被检查,如果它大于保存的值,则会引起错误。
以上这篇关于PyTorch 自动求导机制详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pytorch反向求导更新网络参数的方法
方法一:手动计算变量的梯度,然后更新梯度 import torch from torch.autograd import Variable # 定义参数 w1 = Variable(torch.FloatTensor([1,2,3]),requires_grad = True) # 定义输出 d = torch.mean(w1) # 反向求导 d.backward() # 定义学习率等参数 lr = 0.001 # 手动更新参数 w1.data.zero_() # BP求导更新参数之前,需先对导
-
关于PyTorch 自动求导机制详解
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile.它们都允许从梯度计算中精细地排除子图,并可以提高效率. requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度.相反,只有所有输入都不需要梯度,输出才不需要.如果其中所有的变量都不需要梯度进行,后向计算不会在子图中执行. >>> x = Variable(torch.randn(5, 5)) >>> y = Variable(torch.rand
-
python人工智能自定义求导tf_diffs详解
目录 自定义求导:(近似求导数的方法) 多元函数的求导 在tensorflow中的求导 使用tf.GradientTape() 对常量求偏导 求二阶导数的方法 结合optimizers进行梯度下降法 自定义求导:(近似求导数的方法) 让x向左移动eps得到一个点,向右移动eps得到一个点,这两个点形成一条直线,这个点的斜率就是x这个位置的近似导数. eps足够小,导数就足够真. def f(x): return 3. * x ** 2 + 2. * x - 1 def approximate_d
-

Pytorch自动求导函数详解流程以及与TensorFlow搭建网络的对比
一.定义新的自动求导函数 在底层,每个原始的自动求导运算实际上是两个在Tensor上运行的函数.其中,forward函数计算从输入Tensor获得的输出Tensors.而backward函数接收输出,Tensors对于某个标量值得梯度,并且计算输入Tensors相对于该相同标量值得梯度. 在Pytorch中,可以容易地通过定义torch.autograd.Function的子类实现forward和backward函数,来定义自动求导函数.之后就可以使用这个新的自动梯度运算符了.我们可以通过构造一
-
Pytorch中的自动求梯度机制和Variable类实例
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性:Varibale的Tensor本身的.data,对应Tensor的梯度.grad,以及这个Variable是通过什么方式得到的.grad_fn,根据最新消息,在pytorch0.4更新后,torch和torch.autograd.Variab
-
TensorFlow的自动求导原理分析
原理: TensorFlow使用的求导方法称为自动微分(Automatic Differentiation),它既不是符号求导也不是数值求导,而类似于将两者结合的产物. 最基本的原理就是链式法则,关键思想是在基本操作(op)的水平上应用符号求导,并保持中间结果(grad). 基本操作的符号求导定义在\tensorflow\python\ops\math_grad.py文件中,这个文件中的所有函数都用RegisterGradient装饰器包装了起来,这些函数都接受两个参数op和grad,参数op是
-
在 pytorch 中实现计算图和自动求导
前言: 今天聊一聊 pytorch 的计算图和自动求导,我们先从一个简单例子来看,下面是一个简单函数建立了 yy 和 xx 之间的关系 然后我们结点和边形式表示上面公式: 上面的式子可以用图的形式表达,接下来我们用 torch 来计算 x 导数,首先我们创建一个 tensor 并且将其requires_grad设置为True表示随后反向传播会对其进行求导. x = torch.tensor(3.,requires_grad=True) 然后写出 y = 3*x**2 + 4*x + 2 y.ba
-
pytorch中的上采样以及各种反操作,求逆操作详解
import torch.nn.functional as F import torch.nn as nn F.upsample(input, size=None, scale_factor=None,mode='nearest', align_corners=None) r"""Upsamples the input to either the given :attr:`size` or the given :attr:`scale_factor` The algorith
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
Pytorch Tensor基本数学运算详解
1. 加法运算 示例代码: import torch # 这两个Tensor加减乘除会对b自动进行Broadcasting a = torch.rand(3, 4) b = torch.rand(4) c1 = a + b c2 = torch.add(a, b) print(c1.shape, c2.shape) print(torch.all(torch.eq(c1, c2))) 输出结果: torch.Size([3, 4]) torch.Size([3, 4]) tensor(1, dt
-
PyTorch中的Variable变量详解
一.了解Variable 顾名思义,Variable就是 变量 的意思.实质上也就是可以变化的量,区别于int变量,它是一种可以变化的变量,这正好就符合了反向传播,参数更新的属性. 具体来说,在pytorch中的Variable就是一个存放会变化值的地理位置,里面的值会不停发生片花,就像一个装鸡蛋的篮子,鸡蛋数会不断发生变化.那谁是里面的鸡蛋呢,自然就是pytorch中的tensor了.(也就是说,pytorch都是有tensor计算的,而tensor里面的参数都是Variable的形式).如果