python自动保存百度盘资源到百度盘中的实例代码
本实例的实现逻辑是,应用selenium UI自动化登录百度盘,读取存储百度分享地址和提取码的txt文档,打开百度盘分享地址,填入提取码,然后保存到指定的目录中
全部代码如下:
# -*-coding:utf8-*-
# encoding:utf-8
import time
from selenium import webdriver
browser = webdriver.Chrome()
def loginphont():
browser.get("https://pan.baidu.com/")#打开链接
browser.maximize_window()
browser.find_element_by_id("TANGRAM__PSP_4__footerULoginBtn").click()
browser.find_element_by_id("TANGRAM__PSP_4__userName").send_keys("百度盘账号")
browser.find_element_by_id("TANGRAM__PSP_4__password").send_keys("百度盘密码")
browser.find_element_by_id("TANGRAM__PSP_4__submit").click()
time.sleep(3)
browser.find_element_by_id("TANGRAM__23__button_send_mobile").click()#发送验证码
time.sleep(20)
loginphont()
def keep():
for line in open('C:\\Users\\Beckham\\Desktop\\python\\1.txt'):#循环读取百度地址和提取码
address = line[0:47]#分离出百度盘地址
code = line[47:51]#分割出提取码
browser.get(address)#打开链接
browser.find_element_by_id("ksrmwk1v").send_keys(code)#输入提取码
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'提取文件')]").click()
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'保存到网盘')]").click()
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'存储文件目录')]").click()
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'确定')]").click()
time.sleep(5)
keep()
def over():
print("game over")
over()
百度盘资源的链接和提取码的爬取来源请参考这一实例:https://www.jb51.net/article/168449.htm
爬取后生成的txt文档如下图
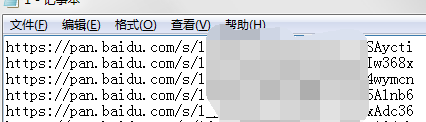
每一条数据的后4位为提取码,其余前面的内容为百度分享链接,所以有了下面的步骤,分离出分享地址和提取码
for line in open('C:\\Users\\Beckham\\Desktop\\python\\1.txt'):#循环读取百度地址和提取码
address = line[0:47]#分离出百度盘地址
code = line[47:51]#分割出提取码
browser.get(address)#打开链接
过程,步骤都相对简单,就不用每一步都讲解拉
总结
以上所述是小编给大家介绍的python自动保存百度盘资源到百度盘中的实例代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python抓取豆瓣图片并自动保存示例学习
环境Python 2.7.6,BS4,在powershell或命令行均可运行.请确保安装了BS模块 复制代码 代码如下: # -*- coding:utf8 -*-# 2013.12.36 19:41 wnlo-c209# 抓取dbmei.com的图片. from bs4 import BeautifulSoupimport os, sys, urllib2 # 创建文件夹,昨天刚学会path = os.getcwd() # 获取此脚本所在目录new_path = os.pat
-
python自动保存百度盘资源到百度盘中的实例代码
本实例的实现逻辑是,应用selenium UI自动化登录百度盘,读取存储百度分享地址和提取码的txt文档,打开百度盘分享地址,填入提取码,然后保存到指定的目录中 全部代码如下: # -*-coding:utf8-*- # encoding:utf-8 import time from selenium import webdriver browser = webdriver.Chrome() def loginphont(): browser.get("https://pan.baidu.com
-
python使用pil进行图像处理(等比例压缩、裁剪)实例代码
PIL中设计的几个基本概念 1.通道(bands):即使图像的波段数,RGB图像,灰度图像 以RGB图像为例: >>>from PIL import Image >>>im = Image.open('*.jpg') # 打开一张RGB图像 >>>im_bands = im.g etbands() # 获取RGB三个波段 >>>len(im_bands) >>>print im_bands[0,1,2] # 输出RG
-
python 与GO中操作slice,list的方式实例代码
python 与GO中操作slice,list的方式实例代码 GO代码中遍历slice,寻找某个slice,统计个数. type Element interface{} func main() { a := []int{1, 2, 3, 4, 1} for _, i := range a { fmt.Println(i) } for i := 0; i < len(a); i++ { //fmt.Println(i) } fmt.Println(index0(a, 3)) fmt.Println
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW
-

Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python面向对象多线程爬虫爬取搜狐页面的实例代码
首先我们需要几个包:requests, lxml, bs4, pymongo, redis 1. 创建爬虫对象,具有的几个行为:抓取页面,解析页面,抽取页面,储存页面 class Spider(object): def __init__(self): # 状态(是否工作) self.status = SpiderStatus.IDLE # 抓取页面 def fetch(self, current_url): pass # 解析页面 def parse(self, html_page): pass
-
python两个_多个字典合并相加的实例代码
这只是符合比较正常的需求和场景. #一.适用合并两个字典(key不能相同否则会被覆盖),简单,好用. A = {'a': 11, 'b': 22} B = {'c': 48, 'd': 13} #update() 把字典B的键/值对更新到A里 A.update(B) print(A) #二.适用多种场合,多字典存在相同key需要合并相加的场景比较适用. def sum_dict(a,b): temp = dict() # python3,dict_keys类似set: | 并集 for key
-
python判断两个序列的成员是否一样的实例代码
目的:判断两个序列的成员是否一样,如:list1 = [1, 2],list2 = [2, 1],则两个序列的成员是一样的. 实现:借助集合set()的性质实现. 代码如下: if __name__ == "__main__": l = [[2, 1], [3, 4]] for i in l: print (i) tmp = set(i) print (tmp) if tmp == {1, 2}: print ("yes") else: print ('no') 输
-
利用python+ffmpeg合并B站视频及格式转换的实例代码
利用python+ffmpeg合并B站视频及格式转换 B站客户端下载的视频一般有两种格式:早期的多为blv格式(由flv格式转换而来,音视频轨道在同一文件下). 如今的多为m4s格式,音频轨视频轨分开 以下为利用ffmpeg简单对文件处理,使其转换为大多数播放器能正常播放的mp4格式 前提:已正常安装ffmpeg import tkinter as tk from tkinter import filedialog import os import tkinter.messagebox from
-
python wav模块获取采样率 采样点声道量化位数(实例代码)
安装: pip install wave 在wav 模块中 ,主要介绍一种方法:getparams(),该方法返回的结果如下: _wave_params(nchannels=1, sampwidth=2, framerate=48000, nframes=171698592, comptype='NONE', compname='not compressed') 参数解释: nchannels:声道数 sampwidth:量化位数(byte) framerate:采样频率 nframes:采样点