浅析mysql迁移到clickhouse的5种方法
数据迁移需要从mysql导入clickhouse, 总结方案如下,包括clickhouse自身支持的三种方式,第三方工具两种。
create table engin mysql
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
官方文档: https://clickhouse.yandex/docs/en/operations/table_engines/mysql/
注意,实际数据存储在远端mysql数据库中,可以理解成外表。
可以通过在mysql增删数据进行验证。
insert into select from
-- 先建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
-- 导入数据
INSERT INTO [db.]table [(c1, c2, c3)] select 列或者* from mysql('host:port', 'db', 'table_name', 'user', 'password')
可以自定义列类型,列数,使用clickhouse函数对数据进行处理,比如
select toDate(xx) from mysql("host:port","db","table_name","user_name","password")
create table as select from
CREATE TABLE [IF NOT EXISTS] [db.]table_name
ENGINE =Log
AS
SELECT *
FROM mysql('host:port', 'db', 'article_clientuser_sum', 'user', 'password')
网友文章: http://jackpgao.github.io/2018/02/04/ClickHouse-Use-MySQL-Data/
不支持自定义列,参考资料里的博主写的 ENGIN=MergeTree 测试失败。
可以理解成 create table 和 insert into select 的组合
Altinity/clickhouse-mysql-data-reader
Altinity公司开源的一个python工具,用来从mysql迁移数据到clickhouse(支持binlog增量更新和全量导入),但是官方readme和代码脱节,根据quick start跑不通。
## 创建表 clickhouse-mysql \ --src-host=127.0.0.1 \ --src-user=reader \ --src-password=Qwerty1# \ --table-templates-with-create-database \ --src-table=airline.ontime > create_clickhouse_table_template.sql ## 修改脚本 vim create_clickhouse_table_template.sql ## 导入建表 clickhouse-client -mn < create_clickhouse_table_template.sql ## 数据导入 clickhouse-mysql \ --src-host=127.0.0.1 \ --src-user=reader \ --src-password=Qwerty1# \ --table-migrate \ --dst-host=127.0.0.1 \ --dst-table=logunified \ --csvpool
注意,上述三种都是从mysql导入clickhouse,如果数据量大,对于mysql压力还是挺大的。下面介绍两种离线方式(streamsets支持实时,也支持离线)
csv
## 忽略建表 clickhouse-client \ -h host \ --query="INSERT INTO [db].table FORMAT CSV" < test.csv
但是如果源数据质量不高,往往会有问题,比如包含特殊字符(分隔符,转义符),或者换行。被坑的很惨。
自定义分隔符, --format_csv_delimiter="|" 遇到错误跳过而不中止, --input_format_allow_errors_num=10 最多允许10行错误, --input_format_allow_errors_ratio=0.1 允许10%的错误 csv 跳过空值(null) ,报 Code: 27. DB::Exception: Cannot parse input: expected , before: xxxx: (at row 69) ERROR: garbage after Nullable(Date): "8,002<LINE FEED>0205" sed ' :a;s/,,/,\\N,/g;ta' |clickhouse-client -h host --query "INSERT INTO [db].table FORMAT CSV" 将 ,, 替换成 ,\N, python clean_csv.py --src=src.csv --dest=dest.csv --chunksize=50000 --cols --encoding=utf-8 --delimiter=,
clean_csv.py参考我另外一篇032-csv文件容错处理
streamsets
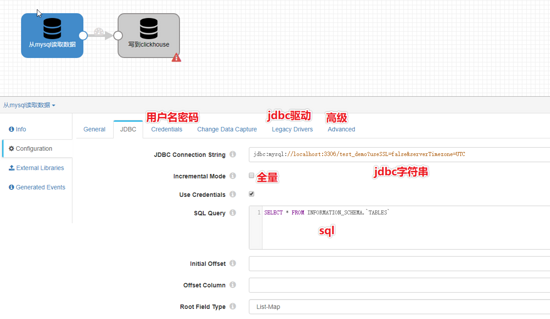
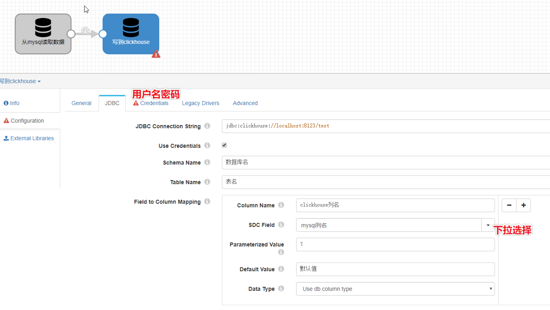
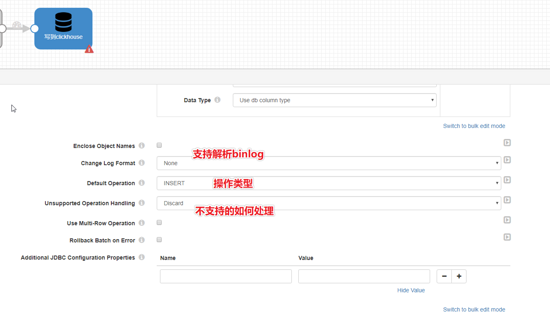
streamsets支持从mysql或者读csv全量导入,也支持订阅binlog增量插入,参考我另外一篇 025-大数据ETL工具之StreamSets安装及订阅mysql binlog 。
本文只展示从mysql全量导入clickhouse
本文假设你已经搭建起streamsets服务
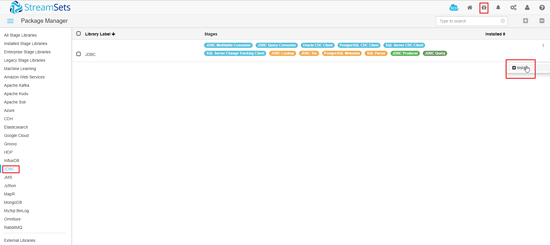
启用并重启服务
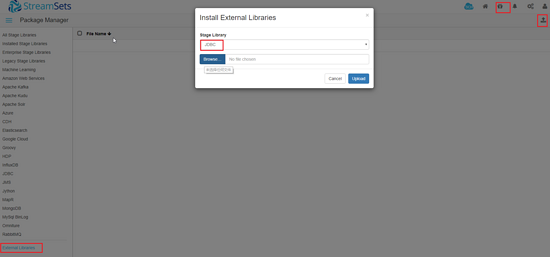
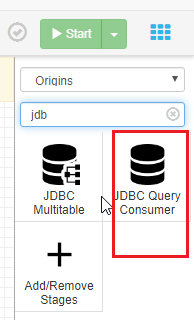
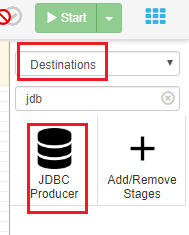
上传mysql和clickhouse的jdbc jar和依赖包
便捷方式,创建pom.xml,使用maven统一下载
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.anjia</groupId> <artifactId>demo</artifactId> <packaging>jar</packaging> <version>1.0-SNAPSHOT</version> <name>demo</name> <url>http://maven.apache.org</url> <dependencies> <dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.1.54</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> </dependencies> </project>
如果本地装有maven,执行如下命令
mvn dependency:copy-dependencies -DoutputDirectory=lib -DincludeScope=compile
所有需要的jar会下载并复制到lib目录下
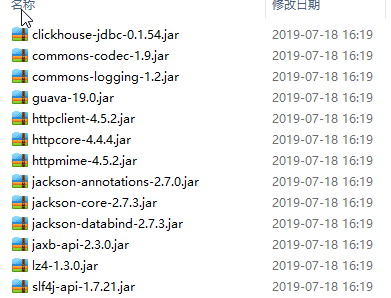
然后拷贝到 streamsets /opt/streamsets-datacollector-3.9.1/streamsets-libs-extras/streamsets-datacollector-jdbc-lib/lib/ 目录下
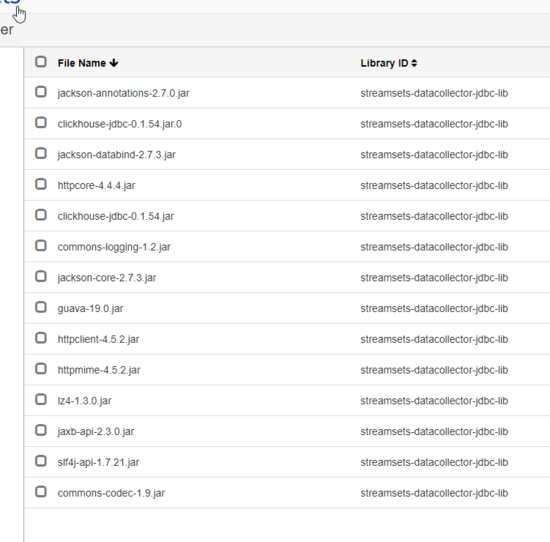
重启streamsets服务
总结
以上所述是小编给大家介绍的mysql迁移到clickhouse的5种方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

SpringBoot整合Elasticsearch7.2.0的实现方法
Spring boot 2.1.X整合Elasticsearch最新版的一处问题 新版本的Spring boot 2的spring-boot-starter-data-elasticsearch中支持的Elasticsearch版本是2.X,但Elasticsearch实际上已经发展到7.2.X版本了,为了更好的使用Elasticsearch的新特性,所以弃用了spring-boot-starter-data-elasticsearch依赖,而改为直接使用Spring-data-elastics
-
SpringBoot2 整合 ClickHouse数据库案例解析
一.ClickHouse简介 1.基础简介 Yandex开源的数据分析的数据库,名字叫做ClickHouse,适合流式或批次入库的时序数据.ClickHouse不应该被用作通用数据库,而是作为超高性能的海量数据快速查询的分布式实时处理平台,在数据汇总查询方面(如GROUP BY),ClickHouse的查询速度非常快. 2.数据分析能力 OLAP场景特征 · 大多数是读请求 · 数据总是以相当大的批(> 1000 rows)进行写入 · 不修改已添加的数据 · 每次查询都从数据库中读取大量的行,
-
Spring Boot整合Swagger2的完整步骤详解
前言 swagger,中文"拽"的意思.它是一个功能强大的api框架,它的集成非常简单,不仅提供了在线文档的查阅, 而且还提供了在线文档的测试.另外swagger很容易构建restful风格的api. 一.Swagger概述 Swagger是一组围绕OpenAPI规范构建的开源工具,可帮助设计.构建.记录和使用REST API. 简单说下,它的出现就是为了方便进行测试后台的restful形式的接口,实现动态的更新,当我们在后台的接口 修改了后,swagger可以实现自动的更新,而不需要
-
SpringBoot2整合Drools规则引擎及案例详解
一.Drools引擎简介 1.基础简介 Drools是一个基于java的规则引擎,开源的,可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中,使得规则的变更不需要修正代码重启机器就可以立即在线上环境生效.具有易于访问企业策略.易于调整以及易于管理的特点,作为开源业务规则引擎,符合业内标准,速度快.效率高. 2.规则语法 (1).演示drl文件格式 package droolRule ; import org.slf4j.Logger import org.slf4j.Logge
-
SpringBoot2.0整合jackson配置日期格式化和反序列化的实现
网上杂七杂八的说法不一,大多数都是抄来抄去,没有实践,近期在项目频繁遇到boot+jackson处理日期的问题,故开此贴. 首先是POM <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
-
springboot2.0整合dubbo的示例代码
写在前面: 使用springboot作为web框架,方便开发许多,做分布式开发,dubbo又不可少,那么怎么整合在一起呢, 跟我学一遍,至少会用 注意,springboot2.0和springboot1.x与dubbo整合不一样, 1.环境 1.新建一个空的maven项目,作为父工程,新建moudle,,service(接口层,及实现层,没有具体分,),web(web层,springboot项目) 项目结构如下 父pom如下 <properties> <project.build.sou
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
SpringBoot2.0整合SpringCloud Finchley @hystrixcommand注解找不到解决方案
hystrix参数使用方法 通过注解@HystrixCommand的commandProperties去配置, 如下就是hystrix命令超时时间命令执行超时时间,为1000ms和执行是不启用超时 @RestController public class MovieController { @Autowired private RestTemplate restTemplate; @GetMapping("/movie/{id}") @HystrixCommand(commandPro
-
浅析mysql迁移到clickhouse的5种方法
数据迁移需要从mysql导入clickhouse, 总结方案如下,包括clickhouse自身支持的三种方式,第三方工具两种. create table engin mysql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIAL
-
浅析Mysql 数据回滚错误的解决方法
MYSQL的事务处理主要有两种方法.1.用begin,rollback,commit来实现begin 开始一个事务rollback 事务回滚commit 事务确认 2.直接用set来改变mysql的自动提交模式MYSQL默认是自动提交的,也就是你提交一个QUERY,它就直接执行!我们可以通过set autocommit=0 禁止自动提交set autocommit=1 开启自动提交来实现事务的处理. 当你用 set autocommit=0 的时候,你以后所有的SQL都将做为事务处理,直到你用c
-
lnmp重置mysql数据库root密码的两种方法
第一种方法:用军哥的一键修改LNMP环境下MYSQL数据库密码脚本 一键脚本肯定是非常方便.具体执行以下命令: wget http://soft.vpser.net/lnmp/ext/reset_mysql_root_password.sh sh reset_mysql_root_password.sh 方便吧! 第二种方法:通过命令修改,具体如下: a.停止MySQL服务 执行:/etc/init.d/mysql stop b.跳过验证启动MySQL /usr/local/mysql/bin/
-
浅析JS动态创建元素【两种方法】
前言: 创建元素有两种方法 1)将需要创建的元素,以字符串的形式拼接:找到父级元素,直接对父级元素的innnerHTML进行赋值. 2)使用Document.Element对象自带的一些函数,来实现动态创建元素(创建元素 => 找到父级元素 => 在指定位置插入元素) 一.字符串拼接形式 为了更好的理解,设定一个应用场景. 随机生成一组数字,将这组数据渲染为条形图的形式,放在div[id="container"]中,如下图 <div id="containe
-
CentOS下MySQL的彻底卸载的几种方法
本文介绍了CentOS下MySQL的彻底卸载的几种方法,分享给大家,具体如下: 1:查看MySQL是否安装: 方式1: [root@localhost usr]# yum list installed mysql* Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.yun-idc.com * extras: mirror.neu.edu.cn * updates: mi
-
mysql大批量插入数据的4种方法示例
前言 本文主要给大家介绍了关于mysql大批量插入数据的4种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 方法一:循环插入 这个也是最普通的方式,如果数据量不是很大,可以使用,但是每次都要消耗连接数据库的资源. 大致思维如下 (我这里写伪代码,具体编写可以结合自己的业务逻辑或者框架语法编写) for($i=1;$i<=100;$i++){ $sql = 'insert...............'; //querysql } foreach($arr as $key =
-
防止MySQL重复插入数据的三种方法
新建表格 CREATE TABLE `person` ( `id` int NOT NULL COMMENT '主键', `name` varchar(64) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '姓名', `age` int NULL DEFAULT NULL COMMENT '年龄', `address` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin N
-
MySQL导入sql文件的三种方法小结
目录 一.使用工具Navicat for MySQL导入 1.打开localhost_3306,选中右击“新建数据库” 2.指定数据库名和字符集(可根据sql文件的字符集类型自行选择) 3.选中数据库下的表运行SQL文件 4.选中路径导入 二.使用官方工具MySQL Workbench导入 1.第一种方法 2.第二种方法 三.使用命令行导入 总结 一.使用工具Navicat for MySQL导入 工具的具体下载及使用方法推荐的一篇文章:https://www.jb51.net/article/
-
MySQL过滤重复数据的两种方法示例
目录 方法1:加关键字 DISTINCT 方法2:用GROUP By 分组 最后 方法1:加关键字 DISTINCT 在mysql中,可以利用“SELECT”语句和“DISTINCT”关键字来进行去重查询,过滤掉重复的数据,语法“SELECT DISTINCT 字段名 FROM 数据表名;”. DISTINCT 关键字的语法格式为: SELECT DISTINCT <字段名> FROM <表名>; 其中,“字段名”为需要消除重复记录的字段名称,多个字段时用逗号隔开. 示例 -- 示
-
MySQL中创建表的三种方法汇总
目录 CREATE TABLE CREATE TABLE … LIKE CREATE TABLE … SELECT 总结 SQL 标准使用 CREATE TABLE 语句创建数据表:MySQL 则实现了三种创建表的方法,支持自定义表结构或者通过复制已有的表结构来创建新表,本文给大家分别介绍一下这些方法的使用和注意事项. CREATE TABLE CREATE TABLE 语句的基本语法如下: CREATE TABLE [IF NOT EXISTS] table_name ( column1 da