记录mysql性能查询过程的使用方法
一切源于一个实验,请看下面的例子:
CREATE TABLE IF NOT EXISTS `foo` (
`a` int(10) unsigned NOT NULL AUTO_INCREMENT,
`b` int(10) unsigned NOT NULL,
`c` varchar(100) NOT NULL,
PRIMARY KEY (`a`),
KEY `bar` (`b`,`a`)
) ENGINE=InnoDB;
CREATE TABLE IF NOT EXISTS `foo2` (
`a` int(10) unsigned NOT NULL AUTO_INCREMENT,
`b` int(10) unsigned NOT NULL,
`c` varchar(100) NOT NULL,
PRIMARY KEY (`a`),
KEY `bar` (`b`,`a`)
) ENGINE=MyISAM;
我往两个表中插入了30w的数据(插入的时候性能差别InnoDB比MyISAM慢)
代码如下:
<?php
$host = '192.168.100.166';
$dbName = 'test';
$user = 'root';
$password = '';
$db = mysql_connect($host, $user, $password) or die('DB connect failed');
mysql_select_db($dbName, $db);
echo '===================InnoDB=======================' . "\r\n";
$start = microtime(true);
mysql_query("SELECT SQL_NO_CACHE SQL_CALC_FOUND_ROWS * FROM foo WHERE b = 1 LIMIT 1000, 10");
$end = microtime(true);
echo $end - $start . "\r\n";
echo '===================MyISAM=======================' . "\r\n";
$start = microtime(true);
mysql_query("SELECT SQL_NO_CACHE SQL_CALC_FOUND_ROWS * FROM foo2 WHERE b = 1 LIMIT 1000, 10");
$end = microtime(true);
echo $end - $start . "\r\n";
返回结果:
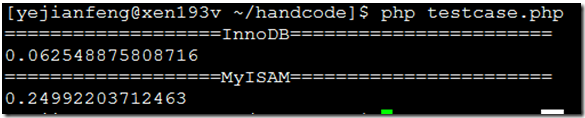
一次查询就会差别这么多!!InnoDB和MyISAM,赶紧分析分析为什么。
首先是使用explain来进行查看
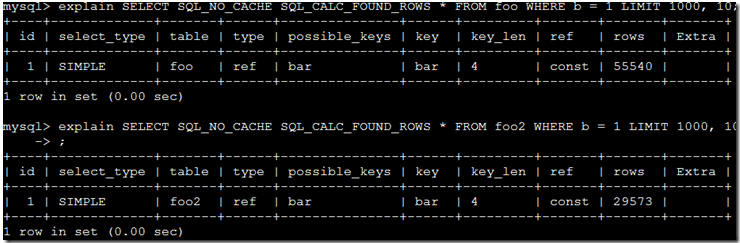
确定两边都没有使用index,第二个查询查的rows,并且MyISAM的查询rows还比InnoDB少这么多,反而是查询慢于InnoDB!!这Y的有点奇怪。
没事,还有一个牛掰工具profile
具体使用可以参考:http://dev.mysql.com/doc/refman/5.0/en/show-profile.html
使用方法简单来说:
Mysql > set profiling = 1;
Mysql>show profiles;
Mysql>show profile for query 1;
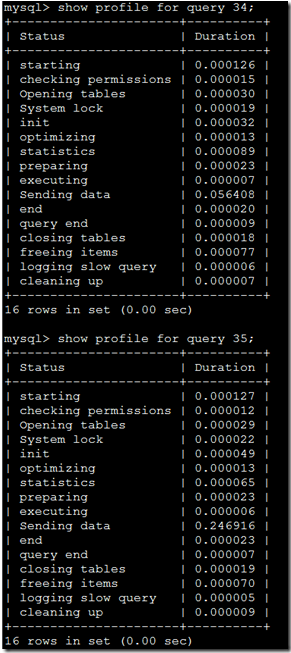
这个数据中就可以看到MyISAM的Sending data比InnoDB的Sending data费时太多了。查看mysql文档
http://dev.mysql.com/doc/refman/5.0/en/general-thread-states.html
Sending data
The thread is reading and processing rows for a SELECT statement, and sending data to the client. Because operations occurring during this this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query.
Sending data是去磁盘中读取select的结果,然后将结果返回给客户端。这个过程会有大量的IO操作。你可以使用show profile cpu for query XX;来进行查看,发现MyISAM的CPU_system比InnnoDB大很多。至此可以得出结论是MyISAM进行表查询(区别仅仅使用索引就可以完成的查询)比InnoDB慢。
相关推荐
-
MySql查询时间段的方法
本文实例讲述了MySql查询时间段的方法.分享给大家供大家参考.具体方法如下: MySql查询时间段的方法未必人人都会,下面为您介绍两种MySql查询时间段的方法,供大家参考. MySql的时间字段有date.time.datetime.timestamp等,往往我们在存储数据的时候将整个时间存在一个字段中,采用datetime类型:也可能采用将日期和时间分离,即一个字段存储date,一个字段存储时间time.无论怎么存储,在实际应用中,很可能会出现包含"时间段"类型的查询,比如一个访
-
mysql如何查询某一时间段内没有卖出的商品
前端时间,室友拿来一道关于mysql查询的问题: 有3张表: 1,zd_product 产品表 zp_id主键(产品id) inputtime(产品发布时间) 2,zd_order订单表 zp_id外键(产品id)zo_id主键(订单id) zo_voer_time( 订单完成时间) 3,zd_ord_pro产品订单表 zo_id外键(订单id)zp_id(产品id) 问:通过这3张表查找从产品发布到"一个月内""没有"被卖出过的产品? 在这里我也不说我们是如何讨论
-
MySQL大表中重复字段的高效率查询方法
MySQL大表重复字段应该如何查询到呢?这是很多人都遇到的问题,下面就教您一个MySQL大表重复字段的查询方法,供您参考. 数据库中有个大表,需要查找其中的名字有重复的记录id,以便比较.如果仅仅是查找数据库中name不重复的字段,很容易 复制代码 代码如下: SELECT min(`id`),`name` FROM `table` GROUP BY `name`; 但是这样并不能得到说有重复字段的id值.(只得到了最小的一个id值)查询哪些字段是重复的也容易 复制代码 代码如下: SELEC
-
MySQL查询随机数据的4种方法和性能对比
下面从以下四种方案分析各自的优缺点.方案一: 复制代码 代码如下: SELECT * FROM `table` ORDER BY RAND() LIMIT 0,1; 这种方法的问题就是非常慢.原因是因为MySQL会创建一张零时表来保存所有的结果集,然后给每个结果一个随机索引,然后再排序并返回.有几个方法可以让它快起来.基本思想就是先获取一个随机数,然后使用这个随机数来获取指定的行.由于所有的行都有一个唯一的id,我们将只取最小和最大id之间的随机数,然后获取id为这个数行.为了让这个方法当id不
-
mysql 按照时间段来获取数据的方法
时间格式为2013-03-12 查询出当天数据: 复制代码 代码如下: SELECT * FROM `table` WHERE date(时间字段) = curdate(); 查询出当月字段: 复制代码 代码如下: SELECT * FROM `table` WHERE month( 时间字段) = month( now( ) ) ; 时间格式为1219876-- UNIX时间,只要应用"FROM_UNIXTIME( )"函数 例如查询当月: 复制代码 代码如下: SELECT * F
-
MySql 按时间段查询数据方法(实例说明)
时间格式为2008-06-16 查询出当天数据: SELECT * FROM `table` WHERE date(时间字段) = curdate(); 查询出当月字段: SELECT * FROM `table` WHERE month( 时间字段) = month( now( ) ) ; 时间格式为1219876-- UNIX时间,只要应用"FROM_UNIXTIME( )"函数 例如查询当月: SELECT * FROM `table` WHERE month( from_uni
-
mysql嵌套查询和联表查询优化方法
嵌套查询糟糕的优化在上面我提到过,不考虑特殊的情况,联表查询要比嵌套查询更有效.尽管两条查询表达的是同样的意思,尽管你的计划是告诉服务器要做什么,然后让它决定怎么做,但有时候你非得告诉它改怎么做.否则优化器可能会做傻事.我最近就碰到这样的情况.这几个表是三层分级关系:category, subcategory和item.有几千条记录在category表,几百条记录在subcategory表,以及几百万条在item表.你可以忽略category表了,我只是交代一下背景,以下查询语句都不涉及到它.这
-
MySQL 查询结果取交集的实现方法
1 MySQL中如何实现以下SQL查询 (SELECT S.Name FROM STUDENT S, TRANSCRIPT T WHERE S.StudId = T.StudId AND T.CrsCode = 'CS305') INTERSECT (SELECT S.Name FROM STUDENT S, TRANSCRIPT T WHERE S.StudId = T.StudId AND T.CrsCode = 'CS315') 请各位不吝赐教,小弟先谢过~ 解: 取交集 select a
-
MySql实现跨表查询的方法详解
复制代码 代码如下: SELECT c.id, c.order_id, c.title, c.content, c.create_time, o.last_pic FROM `orders` o , `case` c WHERE c.order_id = o.order_id ORDER BY c.id DESC LIMIT 15; 关于跨表提取字段的方法!利用order_id相同字段,提取case中的id,order_id,title,content,create_time:orders表中的
-
mysql随机查询若干条数据的方法
在mysql中查询5条不重复的数据,使用以下: 复制代码 代码如下: SELECT * FROM `table` ORDER BY RAND() LIMIT 5 就可以了.但是真正测试一下才发现这样效率非常低.一个15万余条的库,查询5条数据,居然要8秒以上搜索Google,网上基本上都是查询max(id) * rand()来随机获取数据. 复制代码 代码如下: SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * (SELECT MAX
-

Mysql中分页查询的两个解决方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 复制代码 代码如下: SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM foo WHERE b = 1 LIMIT 100,10; 另外一种是使用SQL_CALC_FOUND_ROWS 复制代码 代码如下: SELECT SQL_CALC_FOUND_ROWS a FROM foo WHERE b = 1 LIMIT 100, 10; SELECT FOUND_
-
清空mysql 查询缓存的可行方法
对一条sql进行优化时,发现原本很慢的一条sql(将近1分钟) 在第二次运行时, 瞬间就完成了(0.00sec) 这是因为mysql对同一条sql进行了缓存,服务器直接从上次的查询结果缓存中读取数据,而不是重新分析.执行sql. 可通过如下方法清空查询缓存 reset query cache;