Python基于机器学习方法实现的电影推荐系统实例详解
推荐算法在互联网行业的应用非常广泛,今日头条、美团点评等都有个性化推荐,推荐算法抽象来讲,是一种对于内容满意度的拟合函数,涉及到用户特征和内容特征,作为模型训练所需维度的两大来源,而点击率,页面停留时间,评论或下单等都可以作为一个量化的 Y 值,这样就可以进行特征工程,构建出一个数据集,然后选择一个合适的监督学习算法进行训练,得到模型后,为客户推荐偏好的内容,如头条的话,就是咨询和文章,美团的就是生活服务内容。
可选择的模型很多,如协同过滤,逻辑斯蒂回归,基于DNN的模型,FM等。我们使用的方式是,基于内容相似度计算进行召回,之后通过FM模型和逻辑斯蒂回归模型进行精排推荐,下面就分别说一下,我们做这个电影推荐系统过程中,从数据准备,特征工程,到模型训练和应用的整个过程。
我们实现的这个电影推荐系统,爬取的数据实际上维度是相对少的,特别是用户这一侧的维度,正常推荐系统涉及的维度,诸如页面停留时间,点击频次,收藏等这些维度都是没有的,以及用户本身的维度也相对要少,没有地址、年龄、性别等这些基本的维度,这样我们爬取的数据只有打分和评论这些信息,所以之后我们又从这些信息里再拿出一些统计维度来用。我们爬取的电影数据(除电影详情和图片信息外)是如下这样的形式:
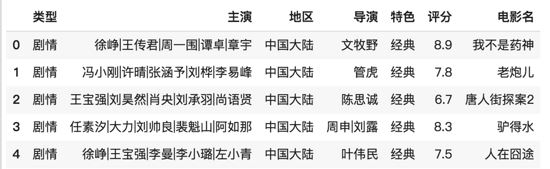
这里的数据是有冗余的,又通过如下的代码,对数据进行按维度合并,去除冗余数据条目:
# 处理主函数,负责将多个冗余数据合并为一条电影数据,将地区,导演,主演,类型,特色等维度数据合并
def mainfunc():
try:
unable_list = []
with connection.cursor() as cursor:
sql='select id,name from movie'
cout=cursor.execute(sql)
print("数量: "+str(cout))
for row in cursor.fetchall():
#print(row[1])
movieinfo = df[df['电影名'] == row[1]]
if movieinfo.shape[0] == 0:
disable_movie(row[0])
print('disable movie ' + str(row[1]))
else:
g = lambda x:movieinfo[x].iloc[0]
types = movieinfo['类型'].tolist()
types = reduce(lambda x,y:x+'|'+y,list(set(types)))
traits = movieinfo['特色'].tolist()
traits = reduce(lambda x,y:x+'|'+y,list(set(traits)))
update_one_movie_info(type_=types, actors=g('主演'), region=g('地区'), director=g('导演'), trait=traits, rat=g('评分'), id_=row[0])
connection.commit()
finally:
connection.close()
之后开始准备用户数据,我们从用户打分的数据中,统计出每一个用户的打分的最大值,最小值,中位数值和平均值等,从而作为用户的一个附加属性,存储于userproex表中:
'insert into userproex(userid, rmax, rmin, ravg, rcount, rsum, rmedian) values(\'%s\', %s, %s, %s, %s, %s, %s)' % (userid, rmax, rmin, ravg, rcount, rsum, rmedium) 'update userproex set rmax=%s, rmin=%s, ravg=%s, rmedian=%s, rcount=%s, rsum=%s where userid=\'%s\'' % (rmax, rmin, ravg, rmedium, rcount, rsum, userid)
以上两个SQL是最终插入表的时候用到的,代表准备用户数据的最终步骤,其余细节可以参考文末的github仓库,不在此赘述,数据处理还用到了一些SQL,以及其他处理细节。
系统上线运行时,第一次是全量的数据处理,之后会是增量处理过程,这个后面还会提到。
我们目前把用户数据和电影的数据的原始数据算是准备好了,下一步开始特征工程。做特征工程的思路是,对type, actors, director, trait四个类型数据分别构建一个频度统计字典,用于之后的one-hot编码,代码如下:
def get_dim_dict(df, dim_name):
type_list = list(map(lambda x:x.split('|') ,df[dim_name]))
type_list = [x for l in type_list for x in l]
def reduce_func(x, y):
for i in x:
if i[0] == y[0][0]:
x.remove(i)
x.append(((i[0],i[1] + 1)))
return x
x.append(y[0])
return x
l = filter(lambda x:x != None, map(lambda x:[(x, 1)], type_list))
type_zip = reduce(reduce_func, list(l))
type_dict = {}
for i in type_zip:
type_dict[i[0]] = i[1]
return type_dict
涉及到的冗余数据也要删除
df_ = df.drop(['ADD_TIME', 'enable', 'rat', 'id', 'name'], axis=1)
将电影数据转换为字典列表,由于演员和导演均过万维,实际计算时过于稀疏,当演员或导演只出现一次时,标记为冷门演员或导演
movie_dict_list = []
for i in df_.index:
movie_dict = {}
#type
for s_type in df_.iloc[i]['type'].split('|'):
movie_dict[s_type] = 1
#actors
for s_actor in df_.iloc[i]['actors'].split('|'):
if actors_dict[s_actor] < 2:
movie_dict['other_actor'] = 1
else:
movie_dict[s_actor] = 1
#regios
movie_dict[df_.iloc[i]['region']] = 1
#director
for s_director in df_.iloc[i]['director'].split('|'):
if director_dict[s_director] < 2:
movie_dict['other_director'] = 1
else:
movie_dict[s_director] = 1
#trait
for s_trait in df_.iloc[i]['trait'].split('|'):
movie_dict[s_trait] = 1
movie_dict_list.append(movie_dict)
使用DictVectorizer进行向量化,做One-hot编码
v = DictVectorizer() X = v.fit_transform(movie_dict_list)
这样的数据,下面做余弦相似度已经可以了,这是特征工程的基本的一个处理,模型所使用的数据,需要将电影,评分,用户做一个数据拼接,构建训练样本,并保存CSV,注意这个CSV不用每次全量构建,而是除第一次外都是增量构建,通过mqlog中类型为'c'的消息,增量构建以comment(评分)为主的训练样本,拼接之后的形式如下:
USERID cf2349f9c01f9a5cd4050aebd30ab74f movieid 10533913 type 剧情|奇幻|冒险|喜剧 actors 艾米·波勒|菲利丝·史密斯|理查德·坎德|比尔·哈德尔|刘易斯·布莱克 region 美国 director 彼特·道格特|罗纳尔多·德尔·卡门 trait 感人|经典|励志 rat 8.7 rmax 5 rmin 2 ravg 3.85714 rcount 7 rmedian 4 TIME_DIS 15
这个数据的actors等字段和上面的处理是一样的,为了之后libfm的使用,在这里需要转换为libsvm的数据格式
dump_svmlight_file(train_X_scaling, train_y_, train_file)
模型使用上遵循先召回,后精排的策略,先通过余弦相似度计算一个相似度矩阵,然后根据这个矩阵,为用户推荐相似的M个电影,在通过训练好的FM,LR模型,对这个M个电影做偏好预估,FM会预估一个用户打分,LR会预估一个点击概率,综合结果推送给用户作为推荐电影。
模块列表
- recsys_ui: 前端技术(html5+JavaScript+jquery+ajax)
- recsys_web: 后端技术(Java+SpringBoot+mysql)
- recsys_spider: 网络爬虫(python+BeautifulSoup)
- recsys_sql: 使用SQL数据处理
- recsys_model: pandas, libFM, sklearn. pandas数据分析和数据清洗,使用libFM,sklearn对模型初步搭建
- recsys_core: 使用pandas, libFM, sklearn完整的数据处理和模型构建、训练、预测、更新的程序
- recsys_etl:ETL 处理爬虫增量数据时使用kettle ETL便捷处理数据
为了能够输出一个可感受的系统,我们采购了阿里云服务器作为数据库服务器和应用服务器,在线上搭建了电影推荐系统的第一版,地址是:
可以注册,也可以使用已有用户:
| 用户名 | 密码 |
|---|---|
| gavin | 123 |
| gavin2 | 123 |
| wuenda | 123 |
欢迎登录使用感受一下。
设计思路
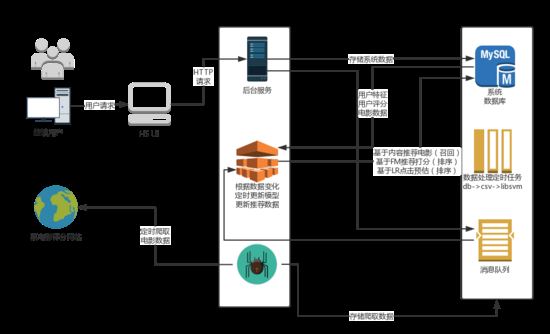
用简单地方式表述一下设计思路,
1.后端服务recsys_web依赖于系统数据库的推荐表‘recmovie'展示给用户推荐内容
2.用户对电影打分后(暂时没有对点击动作进行响应),后台应用会向mqlog表插入一条数据(消息)。
3.新用户注册,系统会插入mqlog中一条新用户注册消息
4.新电影添加,系统会插入mqlog中一条新电影添加消息
5.推荐模块recsys_core会拉取用户的打分消息,并且并行的做以下操作:
a.增量的更新训练样本
b.快速(因服务器比较卡,目前设定了延时)对用户行为进行基于内容推荐的召回
c.训练样本更新模型
d.使用FM,LR模型对Item based所召回的数据进行精排
e.处理新用户注册消息,监听到用户注册消息后,对该用户的属性初始化(统计值)。
f.处理新电影添加消息,更新基于内容相似度而生成的相似度矩阵
注:
由于线上资源匮乏,也不想使系统增加复杂度,所以没有直接使用MQ组件,而是以数据库表作为代替。
项目源码地址: https://github.com/GavinHacker/recsys_core
模型相关的模块介绍
增量的处理用户comment,即增量处理评分模块
这个模块负责监听来自mqlog的消息,如果消息类型是用户的新的comment,则对消息进行拉取,并相应的把新的comment合并到总的训练样本集合,并保存到一个临时目录
然后更新数据库的config表,把最新的样本集合(csv格式)的路径更新上去
运行截图
消息队列的截图
把csv处理为libsvm数据
这个模块负责把最新的csv文件,异步的处理成libSVM格式的数据,以供libFM和LR模型使用,根据系统的性能确定任务的间隔时间
运行截图
基于内容相似度推荐
当监听到用户有新的comment时,该模块将进行基于内容相似度的推荐,并按照电影评分推荐
运行截图
libFM预测
对已有的基于内容推荐召回的电影进行模型预测打分,呈现时按照打分排序
如下图为打分更新
逻辑回归预测
对样本集中的打分做0,1处理,根据正负样本平衡,> 3分为喜欢 即1, <=3 为0 即不喜欢,这样使用逻辑回归做是否喜欢的点击概率预估,根据概率排序
相关推荐
-
python机器学习之贝叶斯分类
一.贝叶斯分类介绍 贝叶斯分类器是一个统计分类器.它们能够预测类别所属的概率,如:一个数据对象属于某个类别的概率.贝叶斯分类器是基于贝叶斯定理而构造出来的.对分类方法进行比较的有关研究结果表明:简单贝叶斯分类器(称为基本贝叶斯分类器)在分类性能上与决策树和神经网络都是可比的.在处理大规模数据库时,贝叶斯分类器已表现出较高的分类准确性和运算性能.基本贝叶斯分类器假设一个指定类别中各属性的取值是相互独立的.这一假设也被称为:类别条件独立,它可以帮助有效减少在构造贝叶斯分类器时所需要进行的计算. 二.
-
编写Python爬虫抓取豆瓣电影TOP100及用户头像的方法
抓取豆瓣电影TOP100 一.分析豆瓣top页面,构建程序结构 1.首先打开网页http://movie.douban.com/top250?start,也就是top页面 然后试着点击到top100的页面,注意带top100的链接依次为 http://movie.douban.com/top250?start=0 http://movie.douban.com/top250?start=25 http://movie.douban.com/top250?start=50 http://movie
-
基于python实现的抓取腾讯视频所有电影的爬虫
我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装.下载.运行起来不会花你5分钟时间. # -*- coding: utf-8 -*- # by awakenjoys. my site: www.dianying.at import re import urllib2 from bs4 import BeautifulSoup import string, time import pymongo NUM = 0 #全局变量,电影数量 m_ty
-
python正则匹配抓取豆瓣电影链接和评论代码分享
复制代码 代码如下: import urllib.requestimport reimport time def movie(movieTag): tagUrl=urllib.request.urlopen(url) tagUrl_read = tagUrl.read().decode('utf-8') return tagUrl_read def subject(tagUrl_read): ''' 这里还存在问题: ①这只针对单独的一页进行排序,而没有
-

Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
python机器学习之随机森林(七)
机器学习之随机森林,供大家参考,具体内容如下 1.Bootstraping(自助法) 名字来自成语"pull up by your own bootstraps",意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法.其核心思想和基本步骤如下: (1) 采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样. (2) 根据抽出的样本计算给定的统计量T. (3) 重复上述N次(一般大于100
-
Python机器学习库scikit-learn安装与基本使用教程
本文实例讲述了Python机器学习库scikit-learn安装与基本使用.分享给大家供大家参考,具体如下: 引言 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上能够为用户提供各种机器学习算法接口,可以让用户简单.高效地进行数据挖掘和数据分析. scikit-learn安装 python 中安装许多模板库之前都有依赖关系,安装 scikit-learn 之前需要以下先决条件: Python(>= 2.6 or >= 3
-
实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7).官方文档中介绍了三种方法进行安装,我采用的是使用 easy_install 进行安装,首先是下载Windows版本的setuptools(下载地址:http://pypi.python.org/pypi/setuptools),下载完后一路NEXT就可以了. 安装完setuptool以后.执行CMD,然后运行一下命令: easy_i
-
使用Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. 先来简单介绍一下,网络爬虫的基本实现原理吧.一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新的URL插入到队列中作为下一次爬取的起点.这样不断地循环,一直到获得你想得到的所有的信息爬虫的任务
-
Python基于机器学习方法实现的电影推荐系统实例详解
推荐算法在互联网行业的应用非常广泛,今日头条.美团点评等都有个性化推荐,推荐算法抽象来讲,是一种对于内容满意度的拟合函数,涉及到用户特征和内容特征,作为模型训练所需维度的两大来源,而点击率,页面停留时间,评论或下单等都可以作为一个量化的 Y 值,这样就可以进行特征工程,构建出一个数据集,然后选择一个合适的监督学习算法进行训练,得到模型后,为客户推荐偏好的内容,如头条的话,就是咨询和文章,美团的就是生活服务内容. 可选择的模型很多,如协同过滤,逻辑斯蒂回归,基于DNN的模型,FM等.我们使用的方式
-
Python基于Floyd算法求解最短路径距离问题实例详解
本文实例讲述了Python基于Floyd算法求解最短路径距离问题.分享给大家供大家参考,具体如下: Floyd算法和Dijkstra算法,相信大家都不陌生,在最短路径距离的求解中应该算得上是最为基础和经典的两个算法了,今天就用一点时间来重新实现一下,因为本科的时候学习数据结构才开始接触的这个算法,当时唯一会用的就是C语言了,现在的话,C语言几乎已经离我远去了,个人感觉入手机器学习以来python更得我心,因为太通俗易懂了,带给你的体验自然也是非常不错的. 当然网上 有很多的算法讲解教程,我不会在
-
Python 基于FIR实现Hilbert滤波器求信号包络详解
在通信领域,可以通过希尔伯特变换求解解析信号,进而求解窄带信号的包络. 实现希尔伯特变换有两种方法,一种是对信号做FFT,单后只保留单边频谱,在做IFFT,我们称之为频域方法:另一种是基于FIR根据传递函数设计一个希尔伯特滤波器,我们称之为时域方法. # -*- coding:utf8 -*- # @TIME : 2019/4/11 18:30 # @Author : SuHao # @File : hilberfilter.py import scipy.signal as signal im
-
Python基于keras训练实现微笑识别的示例详解
目录 一.数据预处理 二.训练模型 创建模型 训练模型 训练结果 三.预测 效果 四.源代码 pretreatment.py train.py predict.py 一.数据预处理 实验数据来自genki4k 提取含有完整人脸的图片 def init_file(): num = 0 bar = tqdm(os.listdir(read_path)) for file_name in bar: bar.desc = "预处理图片: "
-
Python基于纹理背景和聚类算法实现图像分割详解
目录 一.基于纹理背景的图像分割 二.基于K-Means聚类算法的区域分割 三.总结 一.基于纹理背景的图像分割 该部分主要讲解基于图像纹理信息(颜色).边界信息(反差)和背景信息的图像分割算法.在OpenCV中,GrabCut算法能够有效地利用纹理信息和边界信息分割背景,提取图像目标物体.该算法是微软研究院基于图像分割和抠图的课题,它能有效地将目标图像分割提取,如图1所示[1]. GrabCut算法原型如下所示: mask, bgdModel, fgdModel = grabCut(img,
-
Python数据类型之列表和元组的方法实例详解
引言 我们前面的文章介绍了数字和字符串,比如我计算今天一天的开销花了多少钱我可以用数字来表示,如果是整形用 int ,如果是小数用 float ,如果你想记录某件东西花了多少钱,应该使用 str 字符串型,如果你想记录表示所有开销的物品名称,你应该用什么表示呢? 可能有人会想到我可以用一个较长的字符串表示,把所有开销物品名称写进去,但是问题来了,如果你发现你记录错误了,想删除掉某件物品的名称,那你是不是要在这个长字符串中去查找到,然后删除,这样虽然可行,那是不是比较麻烦呢. 这种情况下,你是不是
-
Python读取文件的四种方式的实例详解
目录 学生数量特别少的情况 停车场空间不够时怎么办? 怎么加快执行效率? 怎么加快处理速度? 结语 故事背景:最近在处理Wikipedia的数据时发现由于数据量过大,之前的文件读取和数据处理方法几乎不可用,或耗时非常久.今天学校安排统一核酸检查,刚好和文件读取的过程非常相似.正好借此机会和大家一起从头梳理一下几种文件读取方法. 故事设定:现在学校要求对所有同学进行核酸采集,每位同学先在宿舍内等候防护人员(以下简称“大白”)叫号,叫到自己时去停车场排队等候大白对自己进行采集,采集完之后的样本由大白
-
基于Bootstrap3表格插件和分页插件实例详解
首先看下实现效果图,如果觉得还不错,请参考实现代码. 上面数据 下面分页 使用方法 1 导入bootstrap的css <link rel="stylesheet" href="css/v3/bootstrap.min.css"> 2 导入jquery <script src="js/jquery-1.10.1.min.js" type="text/javascript"></script>
-
python dict 字典 以及 赋值 引用的一些实例(详解)
最近在做一个很大的数据库方面的东东,要用到根据数值来查找,于是想到了python中的字典,平时没用过dict这个东东 用的最多的还是 list 和 tuple (网上查 用法一大堆) 看了一下创建字典的方法: 方法1: dict = {'name': 'earth', 'port': 80} 方法2: fdict = dict((['x', 1], ['y', 2])) 方法3: ddict = {}.fromkeys(('x', 'y'), -1) 都实验了一下这些方法,发现不好用,做不出来自
-
python里使用正则的findall函数的实例详解
python里使用正则的findall函数的实例详解 在前面学习了正则的search()函数,这个函数可以找到一个匹配的字符串返回,但是想找到所有匹配的字符串返回,怎么办呢?其实得使用findall()函数.如下例子: #python 3. 6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'abbaaabbbbaaaaa' pattern = 'ab' for match in r