Python爬虫动态ip代理防止被封的方法
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下怎么用IP代理防止被封
首先,设置等待时间:
常见的设置等待时间有两种,一种是显性等待时间(强制停几秒),一种是隐性等待时间(看具体情况,比如根据元素加载完成需要时间而等待)图1是显性等待时间设置,图2是隐性


第二步,修改请求头:
识别你是机器人还是人类浏览器浏览的重要依据就是User-Agent,比如人类用浏览器浏览就会使这个样子的User-Agent:'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'

第三步,采用代理ip/建代理ip池
直接看代码。利用动态ip代理,可以强有力地保障爬虫不会被封,能够正常运行。图1为使用代理ip的情况,图2是建ip代理池的代码,有没有必要需要看自己的需求,大型项目是必须用大量ip的。
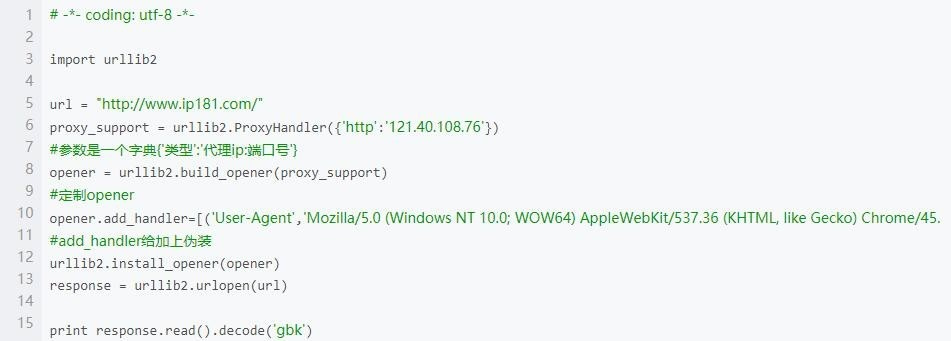
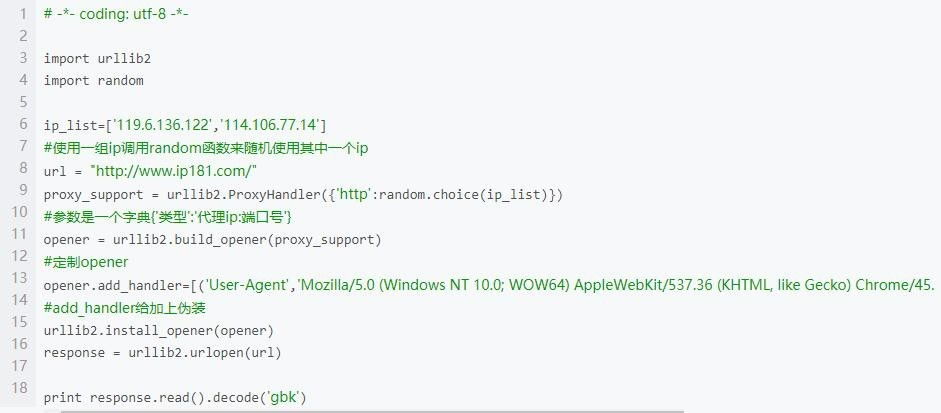
做好以上3个步骤,大致爬虫的运行就不成问题了。
做好以上3个步骤,大致爬虫的运行就不成问题了。
以上就是本次介绍的全部内容,感谢大家的学习和对我们的支持。
相关推荐
-
Python爬虫动态ip代理防止被封的方法
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下怎么用IP代理防止被封 首先,设置等待时间: 常见的设置等待时间有两种,一种是显性等待时间(强制停几秒),一种是隐性等待时间(看具体情况,比如根据元素加载完成需要时间而等待)图1是显性等待时间设置,图2是隐性 第二步,修改请求头: 识别你是机器人还是人类浏览器浏览的重要依据就是User-Agent,比如人类用浏览器浏览就会使这个样子的User-Agent:'Mozilla/5.0 (Win
-
Python爬虫设置ip代理过程解析
1.get方式:如何为爬虫添加ip代理,设置Request header(请求头) import urllib import urllib.request import urllib.parse import random import time from fake_useragent import UserAgent ua = UserAgent() url = "http://www.baidu.com" ######################################
-
Python爬虫抓取代理IP并检验可用性的实例
经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太频繁了,所以被封IP了. 但是,还是可以去IP巴士试试的,条条大路通罗马嘛,不能吊死在一棵树上. 不废话,上代码. #!/usr/bin/env python # -*- coding:utf8 -*- import urllib2 import time
-

python利用proxybroker构建爬虫免费IP代理池的实现
前言 写爬虫的小伙伴可能遇到过这种情况: 正当悠闲地喝着咖啡,满意地看着屏幕上的那一行行如流水般被爬下来的数据时,突然一个Error弹出,提示抓不到数据了... 然后你反复检查,确信自己代码莫得问题之后,发现居然连浏览器也无法正常访问网页了... 难道是网站被我爬瘫痪了? 然后你用手机浏览所爬网站,惊奇地发现居然能访问! 才原来我的IP被网站给封了,拒绝了我的访问 这时只能用IP代理来应对禁IP反爬策略了,但是网上高速稳定的代理IP大多都收费,看了看皱皱的钱包后,一个大胆的想法冒出 我要白嫖!
-
python 爬虫 批量获取代理ip的实例代码
实例如下所示: import urllib.request import os, re,sys,time try: from StringIO import StringIO except ImportError: from io import StringIO loca = re.compile(r"""ion":"\D+", "ti""") #伪装成浏览器 header = {'User-Agent':
-
python爬虫设置每个代理ip的简单方法
python爬虫设置每个代理ip的方法: 1.添加一段代码,设置代理,每隔一段时间换一个代理. urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy.假如一个网站它会检测某一段时间某个 IP 的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,网站君都不知道是谁在捣鬼了,这酸爽! 下面一段代码说明了代理的设置用法. import urllib2 enable_proxy = True proxy_h
-
Python爬虫实现搭建代理ip池
目录 前言 一.User-Agent 二.发送请求 三.解析数据 四.构建ip代理池,检测ip是否可用 五.完整代码 总结 前言 在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip来继续爬虫测试.下面就开始来简单地介绍一下爬取免费的代理ip来搭建自己的代理ip池: 本次爬取免费ip代理的网址:http://www.ip3366.net/free/ 提示:以下是本篇文章正文内容,下面案例可供参考
-
python爬虫框架scrapy代理中间件掌握学习教程
目录 代理的使用场景 使用 HttpProxyMiddleware 中间件 代理的使用场景 编写爬虫代码的程序员,永远绕不开就是使用代理,在编码过程中,你会碰到如下情形: 网络不好,需要代理: 目标站点国内访问不了,需要代理: 网站封杀了你的 IP,需要代理. 使用 HttpProxyMiddleware 中间件 本次的测试站点依旧使用 http://httpbin.org/,通过访问 http://httpbin.org/ip 可以获取当前请求的 IP 地址. HttpProxyMiddlew
-
python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
python爬虫租房信息在地图上显示的方法
本人初学python是菜鸟级,写的不好勿喷. python爬虫用了比较简单的urllib.parse和requests,把爬来的数据显示在地图上.接下里我们话不多说直接上代码: 1.安装python环境和编辑器(自行度娘) 2.本人以58品牌公寓为例,爬取在杭州地区价格在2000-4000的公寓. #-*- coding:utf-8 -*- from bs4 import BeautifulSoup from urllib.parse import urljoin import requests