python正则中最短匹配实现代码
下面从一个例子入手:
利用正则表达式解析下面的XML/HTML标签:
<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>
希望自动格式化重写为:
composer: Wolfgang Amadeus Mozart
author: Samuel Beckett
city: London
一个代码是这样的形式:
#coding:utf-8
import re
s="""<composer>WolfgangAmadeus Mozart</composer>
<author>SamuelBeckett</author>
<city>London</city>"""
pattern1=re.compile("<\w+>") #匹配<>中任意的字符
pattern2=re.compile(">.+</") #匹配><中任意的字符
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
这个代码运行后结果是可以的。
下面我们修改下s的格式:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>"
pattern1=re.compile("<\w+>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile(">.+</") #匹配><中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
得到的答案如下所示:
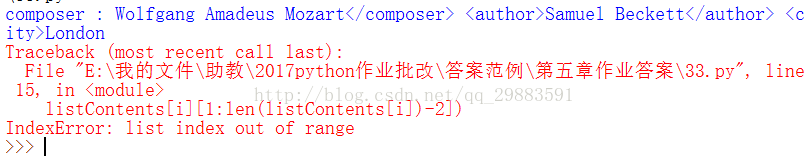
我们打印一下匹配到的两个结果看一下,修改代码如下:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>"
pattern1=re.compile("<\w+>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile(">.+</") #匹配><中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
print(listNames)
print(listContents)
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
显示结果如下:

从第一个箭头显示可以看出,这个处理是对的,那么看第二个箭头,这个匹配的结果显然是不对的了,那么是什么原因呢?
这是因为在正则中,‘*'、‘+'、‘?'这些是贪婪匹配,如用 a*,操作结果是尽可能多地匹配模式。所以当你试着匹配一对对称的定界符,如 HTML 标志中的尖括号。匹配单个 HTML 标志的模式不能正常工作,因为 .* 的本质是“贪婪”的 。在这种情况下,解决方案是使用不贪婪的限定符 *?、+?、?? 或 {m,n}?,尽可能匹配小的文本。
那么代码可以修改如下:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>"
pattern1=re.compile("<\w+?>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile(">.+?</") #匹配><中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
最后,用分组对代码的正则进行优化一下,如下:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer><author>Samuel Beckett</author><city>London</city>"
pattern1=re.compile("<(\w+?)>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile("<\w+?>(.+?)</\w+?>") #匹配<a>...</a>中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
print(listNames[i],":",
listContents[i])
这篇文章就介绍到这,大家可以多参考我们以前发布的关于python 正则表达式的相关内容。
相关推荐
-
Python正则表达式教程之一:基础篇
前言 之前有人提了一个需求,我一看此需求用正则表达式最合适不过.考虑到之前每次使用正则表达式,都是临时抱佛脚,于是这次我就一边完成任务一边系统的学习了一遍正则表达式.主要参考PyCon2016上的一个视频Regular Expressions. 我将分几篇文章对正则表达式进行总结. 以下是第一部分,基础: 基础部分 这里总结了正则表达式最基础的用法,其中大部分内容对我(以及大部分程序员)来说都是平时经常用到的,所以我就一笔带过了,只对其中的几处用例子说明. . 除了换行之外
-

python3爬虫之入门基础和正则表达式
前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享:爬虫说的简单,就是去抓取网路的数据进行分析处理:这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式: 用python抓取指定页面: 代码如下: import urllib.request url= "http://www.baidu.com" data = urllib.request.urlopen(url).read()# d
-
零基础写python爬虫之神器正则表达式
接下来准备用糗百做一个爬虫的小例子. 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容. 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器. 一. 正则表达式基础 1.1.概念介绍 正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下
-
Python基础教程之正则表达式基本语法以及re模块
什么是正则: 正则表达式是可以匹配文本片段的模式. 正则表达式'Python'可以匹配'python' 正则是个很牛逼的东西,python中当然也不会缺少. 所以今天的Python就跟大家一起讨论一下python中的re模块. re模块包含对正则表达式的支持. 通配符 .表示匹配任何字符: '.ython'可以匹配'python'和'fython' 对特殊字符进行转义: 'python\.org'匹配'python.org' 字符集 '[pj]ython'能够匹配'python'和'jython
-
Python正则表达式之基础篇
正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下图展示了使用正则表达式进行匹配的流程: 1.1介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.得益于这一点,在提供了
-
python正则中最短匹配实现代码
下面从一个例子入手: 利用正则表达式解析下面的XML/HTML标签: <composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city> 希望自动格式化重写为: composer: Wolfgang Amadeus Mozart author: Samuel Beckett city: London 一个代码是
-
在Python web中实现验证码图片代码分享
系统版本: CentOS 7.4 Python版本: Python 3.6.1 在现在的WEB中,为了防止爬虫类程序提交表单,图片验证码是最常见也是最简单的应对方法之一. 1.验证码图片的生成 在python中,图片验证码一般用PIL或者Pillow库实现,下面就是利用Pillow生成图片验证码的代码: #!/usr/bin/env python3 #- * -coding: utf - 8 - * -#@Author: Yang#@ Time: 2017 / 11 / 06 1: 04 i
-
python golang中grpc 使用示例代码详解
python 1.使用前准备,安装这三个库 pip install grpcio pip install protobuf pip install grpcio_tools 2.建立一个proto文件hello.proto // [python quickstart](https://grpc.io/docs/quickstart/python.html#run-a-grpc-application) // python -m grpc_tools.protoc --python_out=. -
-
Python获取图像中像素点坐标实例代码
在图片处理过程中,有时候我们想要确定图片中某一像素的坐标,可以通过下面方法得到.点击运行程序,用鼠标点击我们想要获取坐标的区域,即可获得其坐标.结束方式是,敲击键盘“q”,回车,即可结束程序. # -*- coding: utf-8 -*- """ Created on Mon Jan 10 13:58:57 2022 @author: 2540817538(有问题联系此QQ) """ import cv2 img=cv2.imread('C:/
-
正则表达式中最短匹配模式的用法浅析
前言 最近有一次想用正则表达式从网页里面抓取一些东西出来,内容不复杂却出现不少问题.下面话不多说,来一起看看详细的介绍: 当我们用正则表达式去匹配一个标签的首尾的时候,比如匹配 <h1>hello world</h1> 中的 h1 的开始和闭合标签 可能很多人会这样写 /<.*h1>/g 但是这样真的可以吗? 因为 * 匹配符是匹配前面一个字符的零到多个,而且它是贪婪匹配的 所以你得到的就会是下面的结果了. 显然这并不是我们想要的,那么怎么把贪婪匹配换成最小匹配呢, /
-
js正则表达式最长匹配(贪婪匹配)和最短匹配(懒惰匹配)用法分析
本文实例分析了js正则表达式最长匹配(贪婪匹配)和最短匹配(懒惰匹配)用法.分享给大家供大家参考,具体如下: 最近在阅读RequireJS 2.1.15源码,源码开始处定义了一系列的变量,有4个正则表达式: var commentRegExp = /(\/\*([\s\S]*?)\*\/|([^:]|^)\/\/(.*)$)/mg, cjsRequireRegExp = /[^.]\s*require\s*\(\s*["']([^'"\s]+)["']\s*\)/g, jsS
-
Erlang中的匹配模式总结
一.赋值时匹配 原子匹配 复制代码 代码如下: atom = atom % atom another = another % another atom = another % exception error 变量匹配 复制代码 代码如下: Var = 2. % 2 Var = 3 - 1.
-
python正则实现提取电话功能
本文实例为大家分享了python正则提取电话的具体代码,供大家参考,具体内容如下 主要用到正则 import re import xlrd def is_number(s):#是否数字 try: x = int(s)#如果可以取整,说明是数字. return(True) except Exception as e: return False data=xlrd.open_workbook(r'C:\Users\123456\Desktop\手机号/号主.xlsx','utf-8') table
-
python正则匹配抓取豆瓣电影链接和评论代码分享
复制代码 代码如下: import urllib.requestimport reimport time def movie(movieTag): tagUrl=urllib.request.urlopen(url) tagUrl_read = tagUrl.read().decode('utf-8') return tagUrl_read def subject(tagUrl_read): ''' 这里还存在问题: ①这只针对单独的一页进行排序,而没有
-
Python正则匹配判断手机号是否合法的方法
正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),是计算机科学的一个概念.正则表达式使用单个字符串来描述.匹配一系列匹配某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索.替换那些匹配某个模式的文本. # 需求 # 定义一个函数,用于判断输入的手机号是否合法 # 并判断它的运营商 # 思路步骤: # 1.首先了解三大运营商的号段分布 # 2.获取用户输入内容 #