Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索!
一、安装环境:
1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令是:pip install xlrd
2:安装pandas模块还需要一定的编码环境,所以我们自己在安装的时候,确保你的电脑有这些环境:Net.4 、VC-Compiler以及winsdk_web,如果大家没有这些软件~可以咨询我们的辅导员索要相关安装工具。
3:步骤1和2 准备好了之后,我们就可以开始安装pandas了,安装命令是:pip install pandas
一切准备就绪,就可以开始愉快的玩耍咯!
ps:在这个过程中,可能会遇到安装不顺利的情况,万能的度娘有N种解决方案,你这么大应该要学着自己解决问题。
二、pandas操作Excel表单
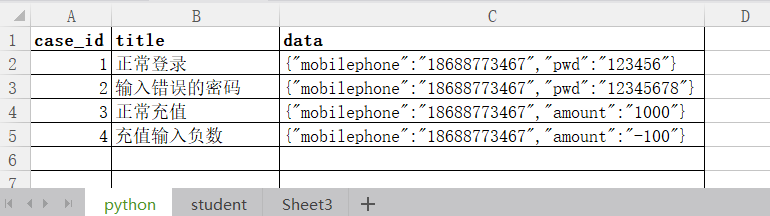
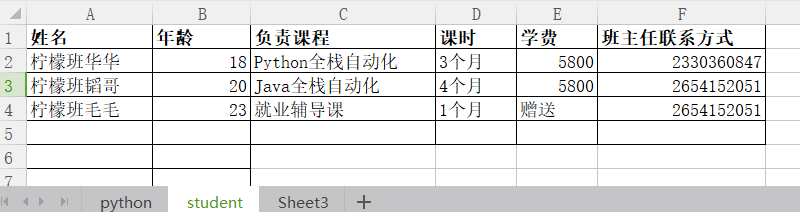
数据准备,有一个Excel文件:lemon.xlsx有两个表单,表单名分别为:Python 以及student,
Python的表单数据如下所示:
student的表单数据如下所示:
1:在利用pandas模块进行操作前,可以先引入这个模块,如下:
import pandas as pd
2:读取Excel文件的两种方式:
#方法一:默认读取第一个表单
df=pd.read_excel('lemon.xlsx')#这个会直接默认读取到这个Excel的第一个表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出
得到的结果是一个二维矩阵,如下所示:

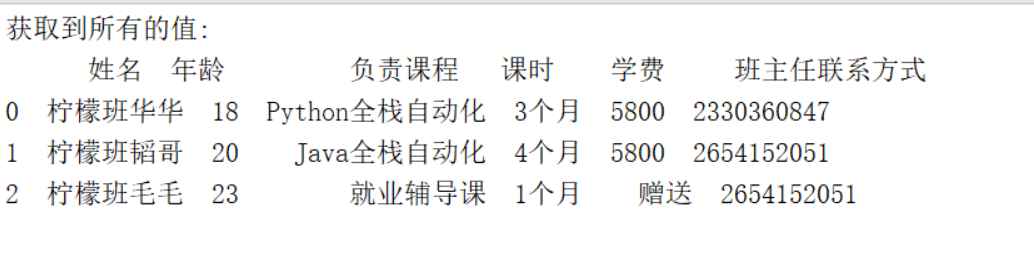
#方法二:通过指定表单名的方式来读取
df=pd.read_excel('lemon.xlsx',sheet_name='student')#可以通过sheet_name来指定读取的表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出
得到的结果如下所示,也是一个二维矩阵:
#方法三:通过表单索引来指定要访问的表单,0表示第一个表单
#也可以采用表单名和索引的双重方式来定位表单
#也可以同时定位多个表单,方式都罗列如下所示
df=pd.read_excel('lemon.xlsx',sheet_name=['python','student'])#可以通过表单名同时指定多个
# df=pd.read_excel('lemon.xlsx',sheet_name=0)#可以通过表单索引来指定读取的表单
# df=pd.read_excel('lemon.xlsx',sheet_name=['python',1])#可以混合的方式来指定
# df=pd.read_excel('lemon.xlsx',sheet_name=[1,2])#可以通过索引 同时指定多个
data=df.values#获取所有的数据,注意这里不能用head()方法哦~
print("获取到所有的值:\n{0}".format(data))#格式化输出
具体结果是怎样的,同学们可以自己一个一个的去尝试,这个结果是非常有意思的,但是同时同学们也发现了,这个数据是一个二维矩阵,对于我们去做自动化测试,并不能很顺利的处理,所以接下来,我们就会详细的讲解,如何来读取行号和列号以及每一行的内容 以及制定行列的内容。
三、pandas操作Excel的行列
1:读取指定的单行,数据会存在列表里面
#1:读取指定行
df=pd.read_excel('lemon.xlsx')#这个会直接默认读取到这个Excel的第一个表单
data=df.ix[0].values#0表示第一行 这里读取数据并不包含表头,要注意哦!
print("读取指定行的数据:\n{0}".format(data))
得到的结果如下所示:
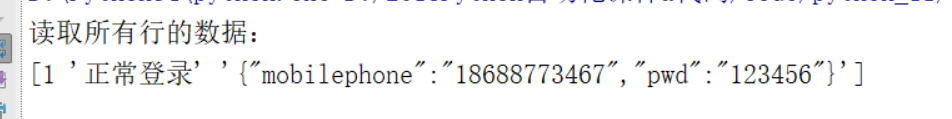
2:读取指定的多行,数据会存在嵌套的列表里面:
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2]].values#读取指定多行的话,就要在ix[]里面嵌套列表指定行数
print("读取指定行的数据:\n{0}".format(data))
3:读取指定的行列:
df=pd.read_excel('lemon.xlsx')
data=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
4:读取指定的多行多列值:
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2],['title','data']].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
5:获取所有行的指定列
df=pd.read_excel('lemon.xlsx')
data=df.ix[:,['title','data']].values#读所有行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
6:获取行号并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出行号列表",df.index.values)
输出结果是:
输出行号列表 [0 1 2 3]
7:获取列名并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出列标题",df.columns.values)
运行结果如下所示:
输出列标题 ['case_id' 'title' 'data']
8:获取指定行数的值:
df=pd.read_excel('lemon.xlsx')
print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法
输出值
[[2 '输入错误的密码' '{"mobilephone":"18688773467","pwd":"12345678"}']
[3 '正常充值' '{"mobilephone":"18688773467","amount":"1000"}']
[1 '正常登录' '{"mobilephone":"18688773467","pwd":"123456"}']]
9:获取指定列的值:
df=pd.read_excel('lemon.xlsx')
print("输出值\n",df['data'].values)
四:pandas处理Excel数据成为字典
我们有这样的数据,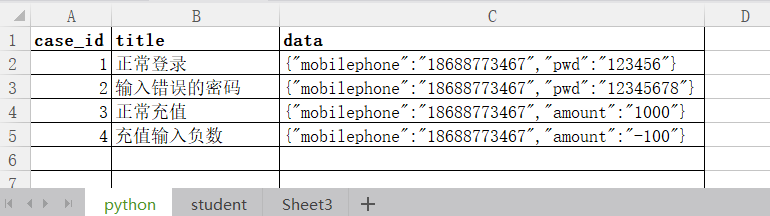 ,处理成列表嵌套字典,且字典的key为表头名。
,处理成列表嵌套字典,且字典的key为表头名。
实现的代码如下所示:
df=pd.read_excel('lemon.xlsx')
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['case_id','module','title','http_method','url','data','expected']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
最后得到的结果是:
最终获取到的数据是:
[{'title': '正常登录', 'case_id': 1, 'data': '{"mobilephone":"18688773467","pwd":"123456"}'},
{'title': '输入错误的密码', 'case_id': 2, 'data': '{"mobilephone":"18688773467","pwd":"12345678"}'},
{'title': '正常充值', 'case_id': 3, 'data': '{"mobilephone":"18688773467","amount":"1000"}'},
{'title': '充值输入负数', 'case_id': 4, 'data': '{"mobilephone":"18688773467","amount":"-100"}'}]
关于pandas的学习,今天就告一段落啦!赶紧打开pycharm跑起来!!!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
解决Python pandas df 写入excel 出现的问题
学习Python数据分析挖掘实战一书时,在数据预处理阶段,有一节要使用拉格朗日插值法对缺失值补充,代码如下: #-*- coding:utf-8 -*- import pandas as pd import matplotlib.pyplot as plt from scipy.interpolate import lagrange#导入拉格朗日插值函数 inputfile="catering_sale.xls" outputfile="H:\python\file\pyth
-
Python 中pandas.read_excel详细介绍
Python 中pandas.read_excel详细介绍 #coding:utf-8 import pandas as pd import numpy as np filefullpath = r"/home/geeklee/temp/all_gov_file/pol_gov_mon/downloads/1.xls" #filefullpath = r"/home/geeklee/temp/all_gov_file/pol_gov_mon/downloads/26368f3
-
python利用pandas将excel文件转换为txt文件的方法
python将数据换为txt的方法有很多,可以用xlrd库实现.本人比较懒,不想按太多用的少的插件,利用已有库pandas将excel文件转换为txt文件. 直接上代码: ''' function:将excel文件转换为text author:Nstock date:2018/3/1 ''' import pandas as pd import re import codecs #将excel转化为txt文件 def exceltotxt(excel_dir, txt_dir): with co
-

用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
python pandas实现excel转为html格式的方法
如下所示: #!/usr/bin/env Python # coding=utf-8 import pandas as pd import codecs xd = pd.ExcelFile('/Users/wangxingfan/Desktop/1.xlsx') df = xd.parse() with codecs.open('/Users/wangxingfan/Desktop/1.html','w','utf-8') as html_file: html_file.write(df.to_
-
对Python 2.7 pandas 中的read_excel详解
导入pandas模块: import pandas as pd 使用import读入pandas模块,并且为了方便使用其缩写pd指代. 读入待处理的excel文件: df = pd.read_excel('log.xls') 通过使用read_excel函数读入excel文件,后面需要替换成excel文件所在的路径.读入之后变为pandas的DataFrame对象.DataFrame是一个面向列(column-oriented)的二维表结构,且含有列表和行标,对excel文件的操作就转换为对Da
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Windows下Python使用Pandas模块操作Excel文件的教程
安装Python环境 ANACONDA是一个Python的发行版本,包含了400多个Python最常用的库,其中就包括了数据分析中需要经常使用到的Numpy和Pandas等.更重要的是,不论在哪个平台上,都可以一键安装,自动配置好环境,不需要用户任何的额外操作,非常方便.因此,安装Python环境就只需要到ANACONDA网站上下载安装文件,双击安装即可. ANACONDA官方下载地址:https://www.continuum.io/downloads 安装完成之后,使用windows + r
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
python sklearn与pandas实现缺失值数据预处理流程详解
注:代码用 jupyter notebook跑的,分割线线上为代码,分割线下为运行结果 1.导入库生成缺失值 通过pandas生成一个6行4列的矩阵,列名分别为'col1','col2','col3','col4',同时增加两个缺失值数据. import numpy as np import pandas as pd from sklearn.impute import SimpleImputer #生成缺失数据 df=pd.DataFrame(np.random.randn(6,4),colu
-
对python xlrd读取datetime类型数据的方法详解
使用xlrd读取出来的时间字段是类似41410.5083333的浮点数,在使用时需要转换成对应的datetime类型,下面代码是转换的方法: 首先需要引入xldate_as_tuple函数 from xlrd import xldate_as_tuple 使用方法如下: #d是从excel中读取出来的浮点数 xldate_as_tuple(d,0) xldate_as_tuple第二个参数有两种取值,0或者1,0是以1900-01-01为基准的日期,而1是1904-01-01为基准的日期.该函数
-
对python requests发送json格式数据的实例详解
requests是常用的请求库,不管是写爬虫脚本,还是测试接口返回数据等.都是很简单常用的工具. 这里就记录一下如何用requests发送json格式的数据,因为一般我们post参数,都是直接post,没管post的数据的类型,它默认有一个类型的,貌似是 application/x-www-form-urlencoded. 但是,我们写程序的时候,最常用的接口post数据的格式是json格式.当我们需要post json格式数据的时候,怎么办呢,只需要添加修改两处小地方即可. 详见如下代码: i
-
Python实现批量采集商品数据的示例详解
目录 本次目的 知识点 开发环境 代码 本次目的 python批量采集某商品数据 知识点 requests 发送请求 re 解析网页数据 json 类型数据提取 csv 表格数据保存 开发环境 python 3.8 pycharm requests 代码 导入模块 import json import random import time import csv import requests import re import pymysql 核心代码 # 连接数据库 def save_sql(t
-
Python实现监控远程主机实时数据的示例详解
目录 0 简述 1 程序说明文档 1.1 服务端 1.2 客户端 2 代码 0 简述 实时监控应用程序,使用Python的Socket库和相应的第三方库来监控远程主机的实时数据,比如CPU使用率.内存使用率.网络带宽等信息.可以允许多个用户同时访问服务端.注:部分指令响应较慢,请耐心等待. 1 程序说明文档 1.1 服务端 本程序为一个基于TCP协议的服务端程序,可以接收客户端发送的指令并执行相应的操作,最终将操作结果返回给客户端.程序运行在localhost(即本机)的8888端口. 主要功能
-
对pandas处理json数据的方法详解
今天展示一个利用pandas将json数据导入excel例子,主要利用的是pandas里的read_json函数将json数据转化为dataframe. 先拿出我要处理的json字符串: strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529
-
Python利用全连接神经网络求解MNIST问题详解
本文实例讲述了Python利用全连接神经网络求解MNIST问题.分享给大家供大家参考,具体如下: 1.单隐藏层神经网络 人类的神经元在树突接受刺激信息后,经过细胞体处理,判断如果达到阈值,则将信息传递给下一个神经元或输出.类似地,神经元模型在输入层输入特征值x之后,与权重w相乘求和再加上b,经过激活函数判断后传递给下一层隐藏层或输出层. 单神经元的模型只有一个求和节点(如左下图所示).全连接神经网络(Full Connected Networks)如右下图所示,中间层有多个神经元,并且每层的每个
-
Node.js利用js-xlsx处理Excel文件的方法详解
简介 本文介绍用 Node.js 中的 js-xlsx 库来处理 Excel 文件. js-xlsx 库是目前 Github 上 star 数量最多的处理 Excel 的库,功能强大,但上手难度稍大.文档有些乱,不适合快速上手. 本文对 js-xlsx 库进行一定的总结,并提供几个实用的例子供读者测试,学习,交流. 安装 $ npm install xlsx 一些概念 在使用这个库之前,先介绍库中的一些概念. workbook 对象,指的是整份 Excel 文档.我们在使用 js-xlsx 读取