C#数据结构与算法揭秘二 线性结构
上文对数据结构与算法,有了一个简单的概述与介绍,这篇文章,我们介绍一中典型数据结构——线性结构。
什么是线性结构,线性结构是最简单、最基本、最常用的数据结构。线性表是线性结构的抽象(Abstract), 线性结构的特点是结构中的数据元素之间存在一对一的线性关系。 这
种一对一的关系指的是数据元素之间的位置关系,即: (1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素; (2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素。也就是说,数据元素是一个接一个的排列。因此,可以把线性结构想象为一种数据元素序列的数据结构。
线性结构(List)是由 n(n≥0)个相同类型的数据元素构成的有限序列。对于这个定义应该注意两个概念:一是“有限” ,指的是线性表中的数据元素的个数是有限的,线性表中的每一个数据元素都有自己的位置(Position)。本书不讨论数据元素个数无限的线性表。二是“相同类型” ,指的是线性表中的数据元素都属于同一种类型。这体现在我们常用的数据结构就是数组,泛型等等他们都是线性结构的。
他们之间的关系 是:线性表的形式化定义为:线性表(List)简记为 L,是一个二元组, L = (D, R) 其中:D 是数据元素的有限集合。 R 是数据元素之间关系的有限集合。
线性结构的基本操作如下:
public interface IListDS<T> {
int GetLength(); //求长度
void Clear(); //清空操作
bool IsEmpty(); //判断线性表是否为空
void Append(T item); //附加操作
void Insert(T item, int i); //插入操作
T Delete(int i); //删除操作
T GetElem(int i); //取表元
int Locate(T value); //按值查找
}
这里为什么是IListDS是与。net自带IList相区别。对每个方法解释如下:
1、求长度:GetLength()
初始条件:线性表存在;
操作结果:返回线性表中所有数据元素的个数。
2、清空操作:Clear()
初始条件:线性表存在且有数据元素;
操作结果:从线性表中清除所有数据元素,线性表为空。
3、判断线性表是否为空:IsEmpty()
初始条件:线性表存在;
操作结果:如果线性表为空返回 true,否则返回 false。
4、附加操作:Append(T item)
初始条件:线性表存在且未满;
操作结果:将值为 item 的新元素添加到表的末尾。
5、插入操作:Insert(T item, int i)
初始条件:线性表存在,插入位置正确()(1≤i≤n+1,n 为插入前的表长)。
操作结果:在线性表的第 i 个位置上插入一个值为 item 的新元素,这样使得原序号为 i,i+1,…,n 的数据元素的序号变为 i+1,i+2,…,n+1,插入后表长=原表长+1。
6、删除操作:Delete(int i)
初始条件:线性表存在且不为空,删除位置正确(1≤i≤n,n 为删除前的表长)。
操作结果:在线性表中删除序号为 i 的数据元素,返回删除后的数据元素。删除后使原序号为 i+1,i+2,…,n 的数据元素的序号变为 i,i+1,…,n-1,删除后表长=原表长-1。
7、取表元:GetElem(int i)
初始条件:线性表存在,所取数据元素位置正确(1≤i≤n,n 为线性表的表长) ; 操作结果:返回线性表中第 i 个数据元素。
8、按值查找:Locate(T value)
初始条件:线性表存在。
操作结果:在线性表中查找值为 value 的数据元素,其结果返回在线性表中首次出现的值为 value 的数据元素的序号,称为查找成功;否则,在线性表中未找到值为 value 的数据元素,返回一个特殊值表示查找失败。
先看最简单的线性结构——顺序表
什么是顺序表,线性结构的顺序存储是指在内存中用一块地址连续的空间依次存放线性表的数据元素,用这种方式存储的线性就叫顺序表(Sequence List)。
顺序表储存结构如图所示

假设顺序表中的每个数据元素占w个存储单元, 设第i个数据元素的存储地址为Loc(ai),则有: Loc(ai)= Loc(a1)+(i-1)*w 1≤i≤n 式中的Loc(a1)表示第一个数据元素a1的存储地址,也是顺序表的起始存储地址,称为顺序表的基地址(Base Address). 这里我们举个例子吧,比如你去酒店的时候,知道101号房间的基准的位置,你要去111号房间,你知道每个房间之间的距离是5,那里只需要前进50米。顺序表的地址运算就这么简单。
而顺序表是继承与线性结构,他的源代码又是这个样子的。
public class SeqList<T> : IListDS<T> {
private int maxsize; //顺序表的容量 顺序表的最大容量
private T[] data; //数组,用于存储顺序表中的数据元素 用于存储顺序表的结构
private int last; //指示顺序表最后一个元素的位置
//索引器
public T this[int index]
{
get
{
return data[index];
}
set
{
data[index] = value;
}
}
//最后一个数据元素位置属性
public int Last
{
get
{
return last;
}
}
//容量属性
public int Maxsize
{
get
{
return maxsize;
}
set
{
maxsize = value;
}
}
//构造器 进行函数初始化工作
public SeqList(int size)
{
data = new T[size];
maxsize = size;
last = -1;
}
//求顺序表的长度
public int GetLength()
{
return last+1;
}
//清空顺序表
//清除顺序表中的数据元素是使顺序表为空,此时,last 等于-1。
public void Clear()
{
last = -1;
}
//判断顺序表是否为空
//如果顺序表的 last 为-1,则顺序表为空,返回 true,否则返回 false。
public bool IsEmpty()
{
if (last == -1)
{
return true;
}
else
{
return false;
}
}
//判断顺序表是否为满
//如果顺序表为满,last 等于 maxsize-1,则返回 true,否则返回 false。
public bool IsFull()
{
if (last == maxsize-1)
{
return true;
}
else
{
return false;
}
}
//附加操作是在顺序表未满的情况下,在表的末端添加一个新元素,然后使顺序表的last加1。
//在顺序表的末尾添加新元素
public void Append(T item)
{
if(IsFull())
{
Console.WriteLine("List is full");
return;
}
data[++last] = item;
}
//顺序表的插入是指在顺序表的第i个位置插入一个值为item的新元素, 插入后使 原 表 长 为 n 的 表 (a1,a2, … ,ai-1,ai,ai+1, … ,an) 成 为 表 长 为 n+1 的 表(a1,a2,…,ai-1,item,ai,ai+1,…,an)。i的取值范围为 1≤i≤n+1,i为n+1 时,表示在顺序表的末尾插入数据元素。 顺序表上插入一个数据元素的步骤如下:
//(1)判断顺序表是否已满和插入的位置是否正确,表满或插入的位置不正确不能插入;
//(2)如果表未满和插入的位置正确,则将an~ai依次向后移动,为新的数据元素空出位置。在算法中用循环来实现;
//(3)将新的数据元素插入到空出的第 i 个位置上;
//(4)修改 last(相当于修改表长) ,使它仍指向顺序表的最后一个数据元素。
//在顺序表的第i个数据元素的位置插入一个数据元素
public void Insert(T item, int i)
{
if (IsFull())
{
Console.WriteLine("List is full");
return;
}
if(i<1 | i>last+2)
{
Console.WriteLine("Position is error!");
return;
}
if (i == last + 2)
{
data[last+1] = item;
}
else
{
for (int j = last; j>= i-1; --j)
{
data[j + 1] = data[j];
}
data[i-1] = item;
}
++last;
}
算法的时间复杂度分析:顺序表上的插入操作,时间主要消耗在数据的移动上, 在第i个位置插入一个元素, 从ai到an都要向后移动一个位置, 共需要移动n-i+1
个元素,而i的取值范围为 1≤i≤n+1,当i等于 1 时,需要移动的元素个数最多,为n个;当i为n+1 时,不需要移动元素。设在第i个位置做插入的概率为pi,则平
均移动数据元素的次数为n/2。这说明:在顺序表上做插入操作平均需要移动表中一半的数据元素,所以,插入操作的时间复杂度为O(n) 。
//顺序表的删除操作是指将表中第i个数据元素从顺序表中删除, 删除后使原表长 为 n 的 表 (a1,a2, … ,ai-1,ai, ai+1, … ,an) 变 为 表 长 为 n-1的 表(a1,a2,…,ai-1,ai+1,…,an)。i的取值范围为 1≤i≤n,i为n时,表示删除顺序表末尾的数据元素。
顺序表上删除一个数据元素的步骤如下:
(1)判断顺序表是否为空和删除的位置是否正确,表空或删除的位置不正
确不能删除;
(2)如果表未空和删除的位置正确,则将ai+1~an依次向前移动。在算法中
用循环来实现;
(3)修改 last(相当于修改表长) ,使它仍指向顺序表的最后一个元素。
//删除顺序表的第i个数据元素
public T Delete(int i)
{
T tmp = default(T);
if (IsEmpty())
{
Console.WriteLine("List is empty");
return tmp;
}
if (i < 1 | i > last+1)
{
Console.WriteLine("Position is error!");
return tmp;
}
if (i == last+1)
{
tmp = data[last--];
}
else
{
tmp = data[i-1];
for (int j = i; j <= last; ++j)
{
data[j] = data[j + 1];
}
}
--last;
return tmp;
}
算法的时间复杂度分析:顺序表上的删除操作与插入操作一样,时间主要消耗在数据的移动上。在第i个位置删除一个元素,从ai+1到an都要向前移动一个位置,共需要移动n-i个元素,而i的取值范围为 1≤i≤n,当i等于 1 时,需要移动的元素个数最多,为n-1 个;当i为n时,不需要移动元素。设在第i个位置做删除的概率为pi,则平均移动数据元素的次数为(n-1)/2。这说明在顺序表上做删除操作平均需要移动表中一半的数据元素,所以,删除操作的时间复杂度为O(n) 。
//取表元运算是返回顺序表中第 i 个数据元素,i 的取值范围是 1≤i≤last+1。由于表是随机存取的,所以,如果 i 的取值正确,则取表元运算的时间复杂度为O(1) 。
//获得顺序表的第i个数据元素
public T GetElem(int i)
{
if (IsEmpty() | | (i<1) | | (i>last+1))
{
Console.WriteLine("List is empty or Position is error!");
return default(T);
}
return data[i-1];
}
//顺序表中的按值查找是指在表中查找满足给定值的数据元素。
在顺序表中完成该运算最简单的方法是:从第一个元素起依次与给定值比较,如果找到,则返回在顺序表中首次出现与给定值相等的数据元素的序号,称为查找成功;否则,在顺序表中没有与给定值匹配的数据元素,返回一个特殊值表示查找失败。
//在顺序表中查找值为value的数据元素
public int Locate(T value)
{
if(IsEmpty())
{
Console.WriteLine("List is Empty!");
return -1;
}
int i = 0;
for (i = 0; i <= last; ++i)
{
if (value.Equals(data[i]))
{
break;
}
}
if (i > last)
{
return -1;
}
return i;
}
}
算法的时间复杂度分析:顺序表中的按值查找的主要运算是比较,比较的次数与给定值在表中的位置和表长有关。当给定值与第一个数据元素相等时,比较次数为 1;而当给定值与最后一个元素相等时,比较次数为 n。所以,平均比较次数为(n+1)/2,时间复杂度为 O(n) 。
如:已知顺序表 L,写一算法将其倒置,即实现如图 2.4 所示的操作,其中(a)为倒置前,(b)为倒置后。
我思考的思路就是以所在的中间数进行前后调换。相应的源代码如下:
public void ReversSeqList(SeqList<int> L)
{
int tmp = 0;
int len = L.GetLength();
for (int i = 0; i<= len/2; ++i)
{
tmp = L[i];
L[i] = L[len - i];
L[len - i] = tmp;
}
}
该算法只是对顺序表中的数据元素顺序扫描一遍即完成了倒置, 所以时间复杂度为 O(n)。其中运行效果如图所示:
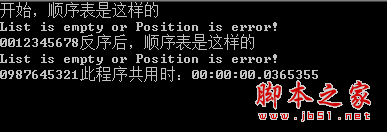
还譬如,我就我开发亲身经历而言 在俄罗斯方块这个项目中,我的顺序结构用的确实很多譬如初始化过程中。
// 初始化形状集合,共七种形状
_pieces = new List<PieceBase> { new I(), new L(), new I2(), new L2(), new N(), new N2(), new O(), new T() };
// 初始化方块容器(用 Block 对象填满整个容器)
Container = new Block[_rows, _columns];
for (int i = 0; i < _rows; i++)
{
for (int j = 0; j < _columns; j++)
{
var block = new Block();
block.Top = i * block.rectangle.ActualHeight;
block.Left = j * block.rectangle.ActualWidth;
block.Color = null;
Container[i, j] = block;
}
}
// 初始化下一个形状的容器(用 Block 对象将其填满)
NextContainer = new Block[4, 4];
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 4; j++)
{
var block = new Block();
block.Top = i * block.rectangle.ActualHeight;
block.Left = j * block.rectangle.ActualWidth;
block.Color = null;
NextContainer[i, j] = block;
}
}
// 创建一个新的形状
CreatePiece();
// 呈现当前创建出的形状
AddPiece(0, 0);
// Timer 用于定时向下移动形状
_timer = new DispatcherTimer();
_timer.Interval = TimeSpan.FromMilliseconds(_initSpeed);
_timer.Tick += _timer_Tick;
GameStatus = GameStatus.Ready;
你看看我用的初始化方块容器,这个容器是二维数组,这就是一种明显的顺序表。将他top位置,left位置赋值,进行一系列初始化工作。这就等同于顺序表初始化操作。这个算法的复杂度为O(n²)。
相关推荐
-
Python实现基本线性数据结构
数组 数组的设计 数组设计之初是在形式上依赖内存分配而成的,所以必须在使用前预先请求空间.这使得数组有以下特性: 1.请求空间以后大小固定,不能再改变(数据溢出问题): 2.在内存中有空间连续性的表现,中间不会存在其他程序需要调用的数据,为此数组的专用内存空间: 3.在旧式编程语言中(如有中阶语言之称的C),程序不会对数组的操作做下界判断,也就有潜在的越界操作的风险(比如会把数据写在运行中程序需要调用的核心部分的内存上). 因为简单数组强烈倚赖电脑硬件之内存,所以不适用于现代的程序设计.欲使用可
-
Python常见数据结构详解
本文详细罗列归纳了Python常见数据结构,并附以实例加以说明,相信对读者有一定的参考借鉴价值. 总体而言Python中常见的数据结构可以统称为容器(container).而序列(如列表和元组).映射(如字典)以及集合(set)是三类主要的容器. 一.序列(列表.元组和字符串) 序列中的每个元素都有自己的编号.Python中有6种内建的序列.其中列表和元组是最常见的类型.其他包括字符串.Unicode字符串.buffer对象和xrange对象.下面重点介绍下列表.元组和字符串. 1.列表 列表是
-

python实现bitmap数据结构详解
bitmap是很常用的数据结构,比如用于Bloom Filter中:用于无重复整数的排序等等.bitmap通常基于数组来实现,数组中每个元素可以看成是一系列二进制数,所有元素组成更大的二进制集合.对于Python来说,整数类型默认是有符号类型,所以一个整数的可用位数为31位. bitmap实现思路 bitmap是用于对每一位进行操作.举例来说,一个Python数组包含4个32位有符号整型,则总共可用位为4 * 31 = 124位.如果要在第90个二进制位上操作,则要先获取到操作数组的第几个元素,
-
python数据结构之二叉树的遍历实例
遍历方案 从二叉树的递归定义可知,一棵非空的二叉树由根结点及左.右子树这三个基本部分组成.因此,在任一给定结点上,可以按某种次序执行三个操作: 1).访问结点本身(N) 2).遍历该结点的左子树(L) 3).遍历该结点的右子树(R) 有次序: NLR.LNR.LRN 遍历的命名 根据访问结点操作发生位置命名:NLR:前序遍历(PreorderTraversal亦称(先序遍历)) --访问结点的操作发生在遍历其左右子树之前.LNR:中序遍历(InorderTraversal)
-
数据结构简明备忘录 线性表
线性表 线性表是线性结构的抽象,线性结构的特点是结构中的数据元素之间存在一对一的线性关系. 数据元素之间的位置关系是一个接一个的排列: .除第一个位置的数据元素外,其他数据元素位置的前面都只有一个数据元素. .除最后一个位置的外,其他数据元素位置的后面都只有一个元素. 线性表通常表示为:L=(D,R) D是数据元素的有限集合 R是数据元素之间关系的有限集合 线性表的基本操作: 复制代码 代码如下: public interface IListDS<T> { int GetLength(); /
-
python数据结构之二叉树的建立实例
先建立二叉树节点,有一个data数据域,left,right 两个指针域 复制代码 代码如下: # -*- coding: utf - 8 - *- class TreeNode(object): def __init__(self, left=0, right=0, data=0): self.left = left self.right = right self.data = data 复制代码 代码如下: class BTree(object):
-
Python中列表、字典、元组、集合数据结构整理
本文详细归纳整理了Python中列表.字典.元组.集合数据结构.分享给大家供大家参考.具体分析如下: 列表: 复制代码 代码如下: shoplist = ['apple', 'mango', 'carrot', 'banana'] 字典: 复制代码 代码如下: di = {'a':123,'b':'something'} 集合: 复制代码 代码如下: jihe = {'apple','pear','apple'} 元组: 复制代码 代码如下: t = 123,456,'hello' 1.列表 空
-
python数据结构树和二叉树简介
一.树的定义 树形结构是一类重要的非线性结构.树形结构是结点之间有分支,并具有层次关系的结构.它非常类似于自然界中的树.树的递归定义:树(Tree)是n(n≥0)个结点的有限集T,T为空时称为空树,否则它满足如下两个条件:(1)有且仅有一个特定的称为根(Root)的结点:(2)其余的结点可分为m(m≥0)个互不相交的子集Tl,T2,-,Tm,其中每个子集本身又是一棵树,并称其为根的子树(Subree). 二.二叉树的定义 二叉树是由n(n≥0)个结点组成的有限集合.每个结点最多有两个子树的有序树
-
C#数据结构与算法揭秘二 线性结构
上文对数据结构与算法,有了一个简单的概述与介绍,这篇文章,我们介绍一中典型数据结构--线性结构. 什么是线性结构,线性结构是最简单.最基本.最常用的数据结构.线性表是线性结构的抽象(Abstract), 线性结构的特点是结构中的数据元素之间存在一对一的线性关系. 这 种一对一的关系指的是数据元素之间的位置关系,即: (1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素: (2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素.也就是说,数据元素是一个接一个的排
-
C#数据结构与算法揭秘二
上文对数据结构与算法,有了一个简单的概述与介绍,这篇文章,我们介绍一中典型数据结构--线性结构. 什么是线性结构,线性结构是最简单.最基本.最常用的数据结构.线性表是线性结构的抽象(Abstract), 线性结构的特点是结构中的数据元素之间存在一对一的线性关系. 这 种一对一的关系指的是数据元素之间的位置关系,即: (1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素: (2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素.也就是说,数据元素是一个接一个的排
-
C#数据结构与算法揭秘一
这里,我们 来说一说C#的数据结构了. ①什么是数据结构.数据结构,字面意思就是研究数据的方法,就是研究数据如何在程序中组织的一种方法.数据结构就是相互之间存在一种或多种特定关系的数据元素的集合. 程序界有一点很经典的话,程序设计=数据结构+算法.用源代码来体现,数据结构,就是编程.他有哪些具体的关系了, (1) 集合(Set):如图 1.1(a)所示,该结构中的数据元素除了存在"同属于一个集合"的关系外,不存在任何其它关系. 集合与数学的集合类似,有无序性,唯一性,确定性. (2)
-
C#数据结构与算法揭秘三 链表
上文我们讨论了一种最简单的线性结构--顺序表,这节我们要讨论另一种线性结构--链表. 什么是链表了,不要求逻辑上相邻的数据元素在物理存储位置上也相邻存储的线性结构称之为链表.举个现实中的例子吧,假如一个公司召开了视频会议的吧,能在北京总公司人看到上海分公司的人,他们就好比是逻辑上相邻的数据元素,而物理上不相连.这样就好比是个链表. 链表分为①单链表,②单向循环链表,③双向链表,④双向循环链表. 介绍各种各样链表之前,我们要明白这样一个概念.什么是结点.在存储数据元素时,除了存储数据元素本身的信息
-
C#数据结构与算法揭秘五 栈和队列
这节我们讨论了两种好玩的数据结构,栈和队列. 老样子,什么是栈, 所谓的栈是栈(Stack)是操作限定在表的尾端进行的线性表.表尾由于要进行插入.删除等操作,所以,它具有特殊的含义,把表尾称为栈顶(Top) ,另一端是固定的,叫栈底(Bottom) .当栈中没有数据元素时叫空栈(Empty Stack).这个类似于送饭的饭盒子,上层放的是红烧肉,中层放的水煮鱼,下层放的鸡腿.你要把这些菜取出来,这就引出来了栈的特点先进后出(First in last out). 具体叙述,加下图. 栈通常记
-
C#数据结构与算法揭秘四 双向链表
首先,明白什么是双向链表.所谓双向链表是如果希望找直接前驱结点和直接后继结点的时间复杂度都是 O(1),那么,需要在结点中设两个引用域,一个保存直接前驱结点的地址,叫 prev,一个直接后继结点的地址,叫 next,这样的链表就是双向链表(Doubly Linked List).双向链表的结点结构示意图如图所示. 双向链表结点的定义与单链表的结点的定义很相似, ,只是双向链表多了一个字段 prev.其实,双向链表更像是一根链条一样,你连我,我连你,不清楚,请看图. 双向链表结点类的实现如下所示
-
Java数据结构与算法之稀疏数组与队列深入理解
目录 一.数据结构和算法简介 二.稀疏数组 稀疏数组的应用实例 二维数组与稀疏数组的转换 二维数组 转 稀疏数组的思路 稀疏数组 转 原始的二维数组的思路 三.队列 数组模拟队列 代码优化:数组模拟环形队列 之前学完了Java SE的知识,掌握了面向对象的编程思想,但对集合.多线程.反射.流的使用等内容理解的还不是很深入,打算再学习数据结构与算法的同时,在空闲的时间里去图书馆看<Java核心技术 卷 I>这本书,很多大佬对这本书很推崇,之前在图书馆也看过其他Java的书籍,经过对比,这本书确实
-
Java数据结构之栈的线性结构详解
目录 一:栈 二:栈的实现 三:栈的测试 四:栈的应用(回文序列的判断) 总结 一:栈 栈是限制插入和删除只能在一个位置上进行的表,此位置就是表的末端,叫作栈顶. 栈的基本操作分为push(入栈) 和 pop(出栈),前者相当于插入元素到表的末端(栈顶),后者相当于删除栈顶的元素. 二:栈的实现 public class LinearStack { /** * 栈的初始默认大小为10 */ private int size = 5; /** * 指向栈顶的数组下标 */ int top = -1
-
C语言数据结构与算法之链表(二)
目录 引入 模拟链表介绍 插入代码实现 代码实现 引入 在上一节的学习中我们介绍了C语言如何实现链表,但是,在这一章,我们将抛开令人头秃的指针和结构体,我们将另外使用一种数组来实现的方式,叫做模拟链表.让我们一起来看看. 模拟链表介绍 链表中的每一个结点都只有两个部分. 我们可以使用一个数组date来储存每序列中的每一个数.那每一个数右边的数是谁,这一点该如何解决呢?在上一章的内容中我们是使用指针来解决的,这里我们只需再用一个数组right来存放序列中每一个数右边的数是谁就可以了.具体要怎么
-
Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简