从零开始学习SQL查询语句执行顺序
SQL查询语句执行顺序如下:
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
前期准备工作
1、新建一个测试数据库
create database testData;
2、创建测试表,并插入数据如下:
用户表

订单表

准备SQL逻辑查询测试语句
SELECT a.user_id,COUNT(b.order_id) as total_orders FROM user as a LEFT JOIN orders as b ON a.user_id = b.user_id WHERE a.city = 'beijing' GROUP BY a.user_id HAVING COUNT(b.order_id) < 2 ORDER BY total_orders desc
使用上述SQL查询语句来获得来自北京,并且订单数少于2的客户;
在这些SQL语句的执行过程中,都会产生一个虚拟表,用来保存SQL语句的执行结果
一、执行FROM语句
第一步,执行FROM语句。我们首先需要知道最开始从哪个表开始的,这就是FROM告诉我们的。现在有了<left_table>和<right_table>两个表,我们到底从哪个表开始,还是从两个表进行某种联系以后再开始呢?它们之间如何产生联系呢?——笛卡尔积
经过FROM语句对两个表执行笛卡尔积,会得到一个虚拟表,VT1(vitual table 1),内容如下:
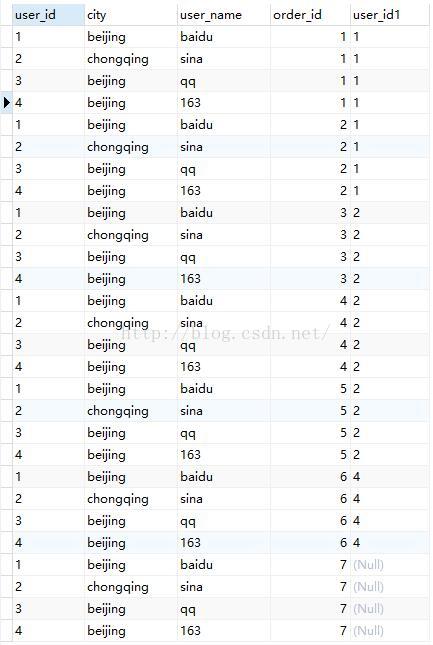
总共有28(user的记录条数 * orders的记录条数)条记录。这就是VT1的结果,接下来的操作就在VT1的基础上进行
二、执行ON过滤
执行完笛卡尔积以后,接着就进行ON a.user_id = b.user_id条件过滤,根据ON中指定的条件,去掉那些不符合条件的数据,得到VT2如下:
select * from user as a inner JOIN orders as b ON a.user_id = b.user_id;

三、添加外部行
这一步只有在连接类型为OUTER JOIN时才发生,如LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。在大多数的时候,我们都是会省略掉OUTER关键字的,但OUTER表示的就是外部行的概念。
LEFT OUTER JOIN把左表记为保留表:即左表的数据会被全部查询出来,若右表中无对应数据,会用NULL来填充:

RIGHT OUTER JOIN把右表记为保留表:即右表的数据会被全部查询出来,若左表中无对应数据,则用NULL补充;

FULL OUTER JOIN把左右表都作为保留表,但在Mysql中不支持全连接,可以通过以下方式实现全连接:

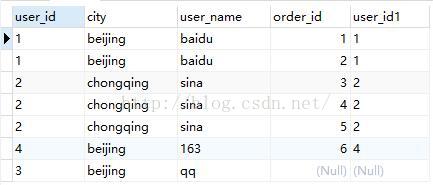
由于我在准备的测试SQL查询逻辑语句中使用的是LEFT JOIN,得到的VT3表如下:
四、执行where条件过滤
对添加了外部行的数据进行where条件过滤,只有符合<where_condition>条件的记录会被筛选出来,执行WHERE a.city = 'beijing' 得到VT4如下:

但是在使用WHERE子句时,需要注意以下两点:
1、由于数据还没有分组,因此现在还不能在where过滤条件中使用where_condition=MIN(col)这类对分组统计的过滤;
2、由于还没有进行列的选取操作,因此在select中使用列的别名也是不被允许的,如:select city as c from table1 wherec='beijing' 是不允许的
五、执行group by分组语句
GROU BY子句主要是对使用WHERE子句得到的虚拟表进行分组操作,执行GROUP BY a.user_id得到VT5如下:

六、执行having
HAVING子句主要和GROUP BY子句配合使用,对分组得到VT5的数据进行条件过滤,执行 HAVING COUNT(b.order_id) < 2,得到VT6如下:

七、select列表
现在才会执行到SELECT子句,不要以为SELECT子句被写在第一行,就是第一个被执行的。
我们执行测试语句中的SELECT a.user_id,user_name,COUNT(b.order_id) as total_orders,从VT6中选择出我们需要的内容,得到VT7如下:
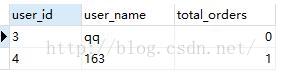
八、执行distinct去重复数据
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张临时表的表结构和上一步产生的虚拟表是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来除重复数据。测试SQL中没有DISTINCT字句,所以不会执行
九、执行order by字句
对虚拟表VT7中的内容按照指定的列进行排序,然后返回一个新的虚拟表,我们执行测试SQL语句中的ORDER BY total_orders DESC ,得到结果如下:
DESC倒序排序,ASC升序排序

十、执行limit字句
LIMIT子句从上一步得到的虚拟表中选出从指定位置开始的指定行数据,常用来做分页;
MySQL数据库的LIMIT支持如下形式的选择:limit n,m
表示从第n条记录开始选择m条记录。对于小数据,使用LIMIT子句没有任何问题,当数据量非常大的时候,使用LIMIT n, m是非常低效的。因为LIMIT的机制是每次都是从头开始扫描,如果需要从第60万行开始,读取3条数据,就需要先扫描定位到60万行,然后再进行读取,而扫描的过程是一个非常低效的过程。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
MySQL查询语句大全集锦
1:使用SHOW语句找出在服务器上当前存在什么数据库: mysql> SHOW DATABASES; 2:2.创建一个数据库MYSQLDATA mysql> CREATE DATABASE MYSQLDATA; 3:选择你所创建的数据库 mysql> USE MYSQLDATA; (按回车键出现Database changed 时说明操作成功!) 4:查看现在的数据库中存在什么表 mysql> SHOW TABLES; 5:创建一个数据库表 mysql> CREATE TAB
-
PHP使用mysqli同时执行多条sql查询语句的实例
PHP数据库操作中,mysqli相对于mysql有很大的优势,建议大家使用:之前我们有介绍过如何在PHP5中使用mysqli的prepare操作数据库,使用mysqli更是支持多查询特性,请看下面这段php代码: <?php $mysqli = new mysqli("localhost","root","","123456"); $mysqli->query("set names 'utf8'"
-
最全的mysql查询语句整理
-- 基本查询 select * from pet -- 列出指定的列 select name, owner form pet -- 直接进行算术运算,对字段起别名 select sin(1+2) as sin --where 条件 select * from pet where (birth>'1980' and species='dog') or species='bird' -- 对null 的条件 select * from pet where sex is not null -- 所有
-

MySQL查询语句过程和EXPLAIN语句基本概念及其优化
网站或服务的性能关键点很大程度在于数据库的设计(假设你选择了合适的语言开发框架)以及如何查询数据上. 我们知道MySQL的性能优化方法,一般有建立索引.规避复杂联合查询.设置冗余字段.建立中间表.查询缓存等,也知道用EXPLAIN来查看执行计划. 但对MySQL复杂查询语句执行过程和内部机制,MySQL Optimizer本身所做优化以及查询语句调整对性能所产生的影响及其原因知之甚少. 本文试图对其中的一些关键概念如执行过程.索引使用等做比较深入的探讨,知其然,知其所以然, 这样可以避免在原本通
-
从零开始学习SQL查询语句执行顺序
SQL查询语句执行顺序如下: (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_
-
Mysql系列SQL查询语句书写顺序及执行顺序详解
目录 1.一个完整SQL查询语句的书写顺序 2.一个完整的SQL语句执行顺序 3.关于select和having执行顺序谁前谁后的说明 1.一个完整SQL查询语句的书写顺序 -- "mysql语句编写顺序" 1 select distinct * 2 from 表(或结果集) 3 where - 4 group by -having- 5 order by - 6 limit start,count -- 注:1.2属于最基本语句,必须含有. -- 注:1.2可以与3.4.5.6中任一
-
SQL查询语句执行的过程
目录 MySQL基本架构 Server 层 1.连接器 2.查询缓存 3.分析器 4.优化器 5.执行器 SQL语句举例: SELECT * FROM `test` WHERE `id`=1; 当我们输入一条SQL语句,返回一个结果时,那这条语句在 MySQL 内部的执行过程是怎么的呢? MySQL基本架构 下面给出的是 MySQL 的基本架构示意图(图片来自网络),从下图中我们可以比较清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程. 从上图直观的来看,MySQL 可分为 S
-
MySQL中一条SQL查询语句是如何执行的
目录 前言 1. 处理连接 1.1 客户端和服务端的通信方式 1.1.1 TCP/IP协议 1.1.2 UNIX域套接字 1.1.3 命名管道和共享内存 1.2 权限验证 1.3 查看MySQL连接 2. 解析与优化 2.1 查询缓存 2.2 解析器 & 预处理器(Parser & Preprocessor) 2.2.1 词法解析 2.2.2 语法分析 2.2.3 预处理器 2.3 查询优化器(Optimizer)与查询执行计划 2.3.1 什么是查询优化器? 2.3.2 优化器究竟做了什
-
15个初学者必看的基础SQL查询语句
本文将分享15个初学者必看的基础SQL查询语句,都很基础,但是你不一定都会,所以好好看看吧. 1.创建表和数据插入SQL 我们在开始创建数据表和向表中插入演示数据之前,我想给大家解释一下实时数据表的设计理念,这样也许能帮助大家能更好的理解SQL查询. 在数据库设计中,有一条非常重要的规则就是要正确建立主键和外键的关系. 现在我们来创建几个餐厅订单管理的数据表,一共用到3张数据表,Item Master表.Order Master表和Order Detail表. 创建表: 创建Item Maste
-
sql和MySQL的语句执行顺序分析
今天遇到一个问题就是mysql中insert into 和update以及delete语句中能使用as别名吗?目前还在查看,但是在查阅资料时发现了一些有益的知识,给大家分享一下,就是关于sql以及MySQL语句执行顺序: sql和mysql执行顺序,发现内部机制是一样的.最大区别是在别名的引用上. 一.sql执行顺序 (1)from (2) on (3) join (4) where (5)group by(开始使用select中的别名,后面的语句中都可以使用) (6) avg,sum....
-
SQL语句执行顺序详解
我们做软件开发的,大部分人都离不开跟数据库打交道,特别是erp开发的,跟数据库打交道更是频繁,由于SQL 不同于与其他编程语言的最明显特征是处理代码的顺序.在大数编程语言中,代码按编码顺序被处理,但是在SQL语言中,第一个被处理的子句是FROM子句,尽管SELECT语句第一个出现,但是几乎总是最后被处理. 每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入.这些虚拟表对调用者(客户端应用程序或者外部查询)不可用.只是最后一步生成的表才会返回 给调用者.如果没有在查询中指定某一子句,将跳过
-
分析mysql中一条SQL查询语句是如何执行的
目录 一.MySQL 逻辑架构概览 二.连接器(Connector) 三.查询缓存(Query Cache) 四.解析器(Parser) 五.优化器(Optimizer) 六.执行器 七.小结 一.MySQL 逻辑架构概览 MySQL 最重要.最与众不同的特性就是它的可插拔存储引擎架构(pluggable storage engine architecture),这种架构的设计将查询处理及其他系统任务和数据的存储/提取分离开来.来看官网的解释: The MySQL pluggable stora
-
MySQL索引失效原因以及SQL查询语句不走索引原因详解
目录 前言 1. 隐式的类型转换,索引失效 2. 查询条件包含 or,可能导致索引失效 3. like 通配符可能导致索引失效 4. 查询条件不满足联合索引的最左匹配原则 5. 在索引列login_time上使用 mysql 的内置函数 6. 对索引列age进行列运算(如,+.-.*./), 索引不生效 7. 索引字段age上使用(!= 或者 < >, not in),索引可能失效 8. 索引字段上使用 is null, is not null,索引可能失效 (查询结果行数) 9. 左右joi
-
日常收集常用SQL查询语句大全
常用sql查询语句如下所示: 一.简单查询语句 1. 查看表结构 SQL>DESC emp; 2. 查询所有列 SQL>SELECT * FROM emp; 3. 查询指定列 SQL>SELECT empmo, ename, mgr FROM emp; SQL>SELECT DISTINCT mgr FROM emp; 只显示结果不同的项 4. 查询指定行 SQL>SELECT * FROM emp WHERE job='CLERK'; 5. 使用算术表达式 SQL>S