Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交、地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构、路网规划、公交选址等。但是,这类数据往往掌握在特定部门中,很难获取。互联网地图上有大量的信息,包含公交、地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集。闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交、地铁站点和数据。
首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线。可以通过图吧公交、公交网、8684、本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称。Python写个简单的爬虫就能采集,可参看WenWu_Both的文章,博主详细介绍了如何利用python爬取8684上某城市所有的公交站点数据。该博主采集了站点详细的信息,包括,但是缺少了公交站点的坐标、公交线路坐标数据。这就让人抓狂了,没有空间坐标怎么落图,怎么分析,所以,本文重点介绍的是站点坐标、线路的获取。
以图吧公交为例,点击某一公交后,出现该路公交的详细站点信息和地图信息。博主顿感兴奋,觉得马上就要成功了,各种抓包,发现并不能解析。可能博主技术所限,如有大神能从中抓到站点和线路的坐标信息,请不宁赐教。这TM就让人绝望了啊,到嘴的肥肉吃不了。
天无绝人之路,尝试找找某地图的API,发现可以调用,通过解析,能够找到该数据的后台地址。熟悉前端的可以试试,博主前端也就只会个hello world,不献丑了。这是一种思路,实践证明是可以的。
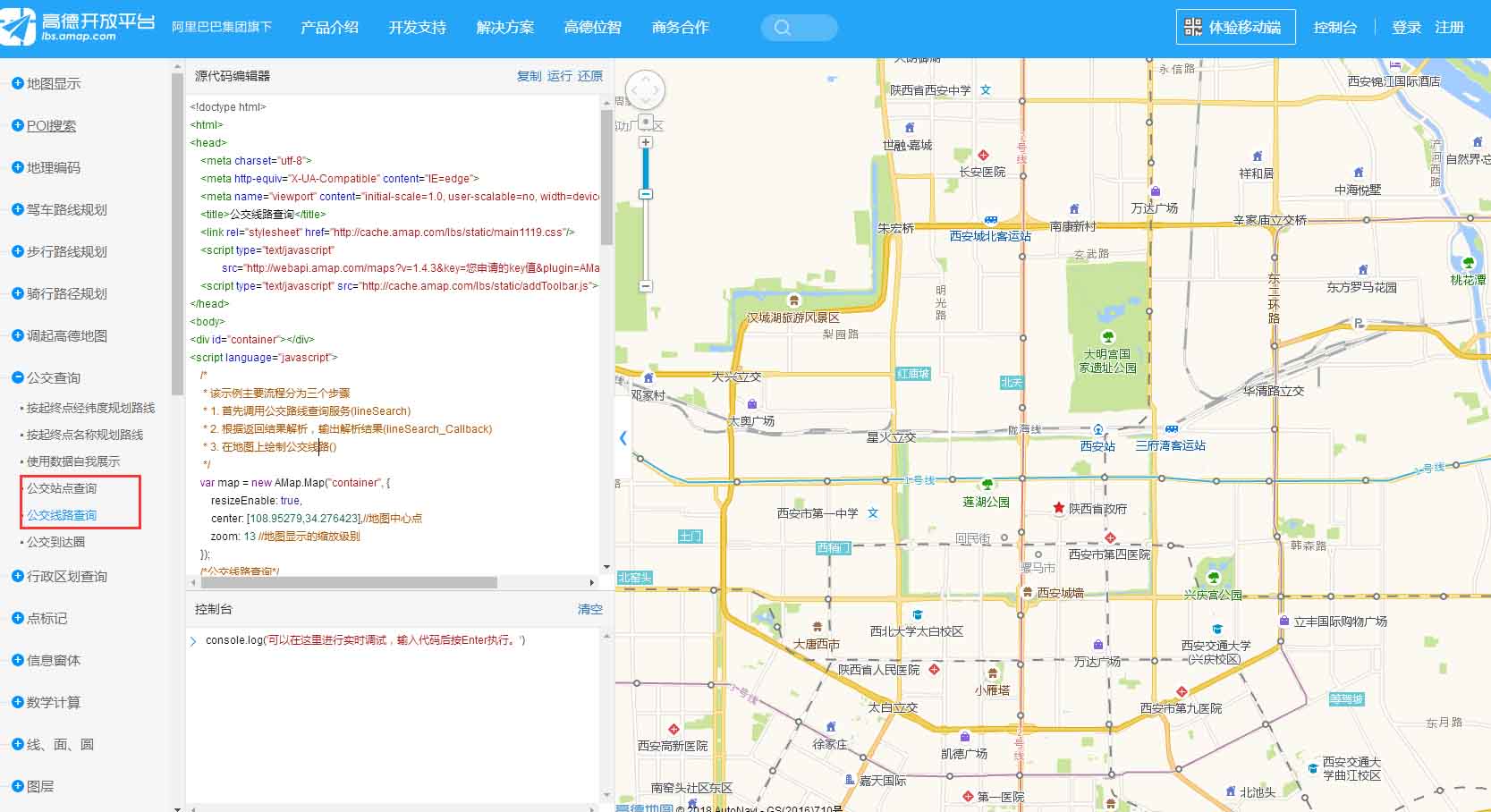
地图API可以,那么通过地图抓包呢?打开某图主页,直接输入某市公交名称,通过抓包,成功找到站点和线路信息。具体抓包信息如下图所示,busline_list中详细列出了站点和线路的信息,其中有两条,是同一趟公交不同方向的数据,略有差别,需注意。找到入口过后,接下来爬虫就要大显身手了。
主要爬取代码如下,其实也很简单,主函数如下。首先需要构建传入的参数,主要的包括路线名称,城市编码,地理范围,缩放尺度。地理范围可以通过坐标拾取器获取,参数经url编码后,发送请求,判断返回数据是否符合要求(注:可能该线路地图上停运或不存在,也可能是访问速度过快,反爬虫机制需要人工验证,博主爬取的时候碰到过,所以后面设置了随机休眠)。接下来,就是解析json数据了。代码中的extratStations和extractLine,就是提取需要的字段,怎么样,是不是很简单。最后,就是保存了,站点和路线分别存储。
def main():
df = pd.read_excel("线路名称.xlsx",)
BaseUrl = "https://ditu.amap.com/service/poiInfo?query_type=TQUERY&pagesize=20&pagenum=1&qii=true&cluster_state=5&need_utd=true&utd_sceneid=1000&div=PC1000&addr_poi_merge=true&is_classify=true&"
for bus in df[u"线路"]:
params = {
'keywords':'11路',
'zoom': '11',
'city':'610100',
'geoobj':'107.623|33.696|109.817|34.745'
}
print(bus)
paramMerge = urllib.parse.urlencode(params)
#print(paramMerge)
targetUrl = BaseUrl + paramMerge
stationFile = "./busStation/" + bus + ".csv"
lineFile = "./busLine/" + bus + ".csv"
req = urllib.request.Request(targetUrl)
res = urllib.request.urlopen(req)
content = res.read()
jsonData = json.loads(content)
if (jsonData["data"]["message"]) and jsonData["data"]["busline_list"]:
busList = jsonData["data"]["busline_list"] ##busline 列表
busListSlt = busList[0] ## busList共包含两条线,方向不同的同一趟公交,任选一趟爬取
busStations = extratStations(busListSlt)
busLine = extractLine(busListSlt)
writeStation(busStations, stationFile)
writeLine(busLine, lineFile)
sleep(random.random() * random.randint(0,7) + random.randint(0,5)) #设置随机休眠
else:
continue
附上博主的解析函数:
def extratStations(busListSlt):
busName = busListSlt["name"]
stationSet = []
stations = busListSlt["stations"]
for bs in stations:
tmp = []
tmp.append(bs["station_id"])
tmp.append(busName)
tmp.append(bs["name"])
cor = bs["xy_coords"].split(";")
tmp.append(cor[0])
tmp.append(cor[1])
wgs84cor1 = gcj02towgs84(float(cor[0]),float(cor[1]))
tmp.append(wgs84cor1[0])
tmp.append(wgs84cor1[1])
stationSet.append(tmp)
return stationSet
def extractLine(busListSlt):
## busList共包含两条线,备注名称
keyName = busListSlt["key_name"]
busName = busListSlt["name"]
fromName = busListSlt["front_name"]
toName = busListSlt["terminal_name"]
lineSet = []
Xstr = busListSlt["xs"]
Ystr = busListSlt["ys"]
Xset = Xstr.split(",")
Yset = Ystr.split(",")
length = len(Xset)
for i in range(length):
tmp = []
tmp.append(keyName)
tmp.append(busName)
tmp.append(fromName)
tmp.append(toName)
tmp.append(Xset[i])
tmp.append(Yset[i])
wgs84cor2 = gcj02towgs84(float(Xset[i]),float(Yset[i]))
tmp.append(wgs84cor2[0])
tmp.append(wgs84cor2[1])
lineSet.append(tmp)
return lineSet
爬虫采集原始数据如下:
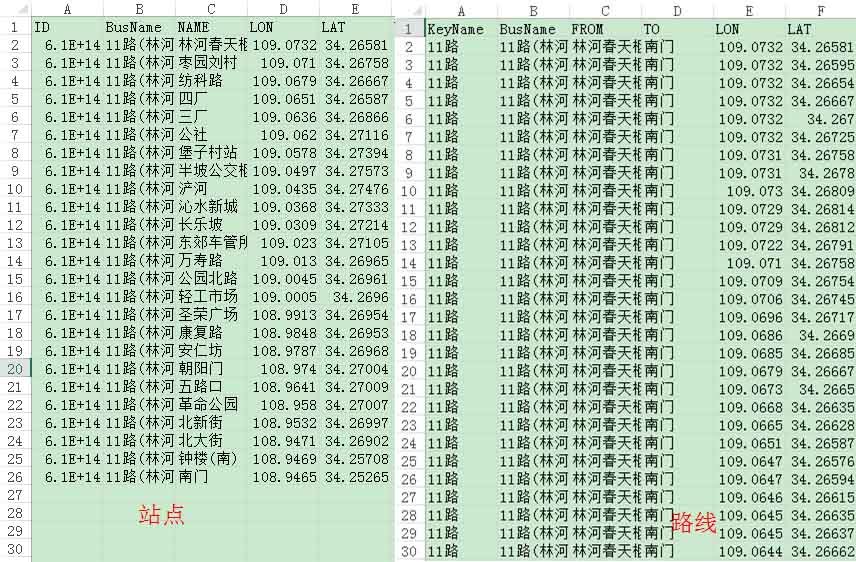
以下是某一条公交站点和线路的处理后的数据展示。由于不同的地图商采用不同的坐标系,会有不同程度的偏差,需要坐标纠偏。下一步,博主将详细介绍如何批量将这些站点和坐标进行坐标纠正和矢量化。
您可能感兴趣的文章:
- python实现博客文章爬虫示例
- 基于python爬虫数据处理(详解)
- 零基础写python爬虫之爬虫编写全记录
- Python多线程爬虫实战_爬取糗事百科段子的实例
相关推荐
-
python实现博客文章爬虫示例
复制代码 代码如下: #!/usr/bin/python#-*-coding:utf-8-*-# JCrawler# Author: Jam <810441377@qq.com> import timeimport urllib2from bs4 import BeautifulSoup # 目标站点TargetHost = "http://adirectory.blog.com"# User AgentUserAgent = 'Mozilla/5.0 (X11; Lin
-

零基础写python爬虫之爬虫编写全记录
先来说一下我们学校的网站: http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html 查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分. 显然这样手动计算绩点是一件非常麻烦的事情.所以我们可以用python做一个爬虫来解决这个问题. 1.决战前夜 先来准备一下工具:HttpFox插件. 这是一款http协议分析插件,分析页面请求和响应的时间.内容.以及浏览器用到的COOKIE等. 以我为例,安装在火狐上即可,效果如图:
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
Python多线程爬虫实战_爬取糗事百科段子的实例
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike.com/8hr/page/页码/ 多线程爬虫也就和JAVA的多线程差不多,直接上代码 ''' #此处代码为普通爬虫 import urllib.request import urllib.error import re headers = ("User-Agent","Mozilla/5.0
-
Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息,包含公交.地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集.闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交.地铁站点和数据. 首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线.可以通过图吧公交.公交网.8684.本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称.Pyth
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
利用python爬取城市公交站点
目录 页面分析 爬虫 数据清洗 Excel PQ 数据清洗 python数据清洗 QGIS坐标纠偏 导入csv文件 坐标纠偏 总结 利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得到我们的公交站点以后,我们利用高德api来获取站点的经纬度坐标,利用pandas解析json文件.接下来开干,我推荐使用面向对象的方法来写代码. import requ
-
python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
python爬虫_实现校园网自动重连脚本的教程
一.背景 最近学校校园网不知道是什么情况,总出现掉线的情况.每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录.系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网.每次掉线后,再打开任意网页就是这个页面. 二.实现代码 #-*- coding:utf-8 -*- __author__ = 'pf' import time import requests class Login: #初始化 def __init__(self): #检测间隔时间,单位
-
python 爬虫 实现增量去重和定时爬取实例
前言: 在爬虫过程中,我们可能需要重复的爬取同一个网站,为了避免重复的数据存入我们的数据库中 通过实现增量去重 去解决这一问题 本文还针对了那些需要实时更新的网站 增加了一个定时爬取的功能: 本文作者同开源中国(殊途同归_): 解决思路: 1.获取目标url 2.解析网页 3.存入数据库(增量去重) 4.异常处理 5.实时更新(定时爬取) 下面为数据库的配置 mysql_congif.py: import pymysql def insert_db(db_table, issue, time_s
-
Python爬虫爬取煎蛋网图片代码实例
这篇文章主要介绍了Python爬虫爬取煎蛋网图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天,试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代码: import urllib.request import os def url_open(url): req = urllib.reques
-
Python爬虫库BeautifulSoup的介绍与简单使用实例
一.介绍 BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器.利用它不用编写正则表达式即可方便地实现网页信息的提取. Python常用解析库 解析器 使用方法 优势 劣势 Python标准库 BeautifulSoup(markup, "html.parser") Python的内置标准库.执行速度适中 .文档容错能力强 Python 2.7.3 or 3.2.2)前的版本中文容错能力差 lxml HTML 解析器 BeautifulSoup(markup,
-
python爬虫智能翻页批量下载文件的实例详解
python爬虫遇到爬取文件内容时,需要一页页的翻页爬取,这样很是麻烦,其实可以获取每个列表信息下的文件名和文件链接,让文件名和文件链接处理为列表,保存后下载,实现智能翻页批量下载文件,本文以以京客隆为例,批量下载文件,如财务资料,他的每一份报告都是一份pdf格式的文档.以此页面为目标,下载他每个分类的文件python爬虫实战之智能翻页批量下载文件. 1.引入库 import requests import pandas as pd from lxml import etree import r