手把手教你python实现SVM算法
什么是机器学习 (Machine Learning)
机器学习是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。
机器学习的大致分类:
1)分类(模式识别):要求系统依据已知的分类知识对输入的未知模式(该模式的描述)作分析,以确定输入模式的类属,例如手写识别(识别是不是这个数)。
2)问题求解:要求对于给定的目标状态,寻找一个将当前状态转换为目标状态的动作序列。
SVM一般是用来分类的(一般先分为两类,再向多类推广一生二,二生三,三生万物哈)
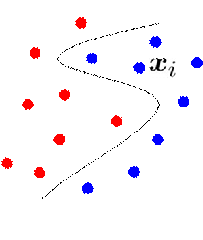
问题的描述
向量表示:假设一个样本有n个变量(特征):Ⅹ= (X1,X2,…,Xn)T
样本表示方法:

SVM线性分类器
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。
过两类样本中离分类面最近的点且平行于最优分类面的超平面上H1,H2的训练样本就叫做支持向量。
图例:

问题描述:
假定训练数据 :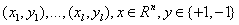
可以被分为一个超平面: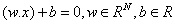
进行归一化: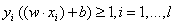
此时分类间隔等于: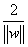
即使得:最大间隔最大等价于使 最小
最小
下面这两张图可以看一下,有个感性的认识。那个好?

看下面这张图:

下面我们要开始优化上面的式子,因为推导要用到拉格朗日定理和KKT条件,所以我们先了解一下相关知识。在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值;如果含有不等式约束,可以应用KKT条件去求取。当然,这两个方法求得的结果只是必要条件,只有当是凸函数的情况下,才能保证是充分必要条件。KKT条件是拉格朗日乘子法的泛化。之前学习的时候,只知道直接应用两个方法,但是却不知道为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够起作用,为什么要这样去求取最优值呢?
拉格朗日乘子法和KKT条件
定义:给定一个最优化问题:
最小化目标函数: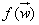
制约条件: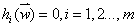
定义拉格朗日函数为:
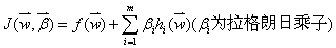
求偏倒方程

可以求得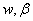 的值。这个就是神器拉格朗日乘子法。
的值。这个就是神器拉格朗日乘子法。
上面的拉格朗日乘子法还不足以帮我们解决所有的问题,下面引入不等式约束
最小化目标函数: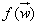
制约条件变为:
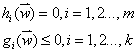
定义拉格朗日函数为:

可以列出方程:

新增加的条件被称为KKT条件
KKT条件详解
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT条件是说最优值必须满足以下条件:
1. L(a, b, x)对x求导为零;
2. h(x) =0;
3. a*g(x) = 0;
求取这三个等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
二. 为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够得到最优值?
为什么要这么求能得到最优值?先说拉格朗日乘子法,设想我们的目标函数z = f(x), x是向量, z取不同的值,相当于可以投影在x构成的平面(曲面)上,即成为等高线,如下图,目标函数是f(x, y),这里x是标量,虚线是等高线,现在假设我们的约束g(x)=0,x是向量,在x构成的平面或者曲面上是一条曲线,假设g(x)与等高线相交,交点就是同时满足等式约束条件和目标函数的可行域的值,但肯定不是最优值,因为相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,可能取得最优值,如下图所示,即等高线和目标函数的曲线在该点的法向量必须有相同方向,所以最优值必须满足:f(x)的梯度 = a* g(x)的梯度,a是常数,表示左右两边同向。这个等式就是L(a,x)对参数求导的结果。(上述描述,我不知道描述清楚没,如果与我物理位置很近的话,直接找我,我当面讲好理解一些,注:下图来自wiki)。

而KKT条件是满足强对偶条件的优化问题的必要条件,可以这样理解:我们要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a>=0,我们可以把f(x)写为:max_{a,b} L(a,b,x),为什么呢?因为h(x)=0, g(x)<=0,现在是取L(a,b,x)的最大值,a*g(x)是<=0,所以L(a,b,x)只有在a*g(x) = 0的情况下才能取得最大值,否则,就不满足约束条件,因此max_{a,b} L(a,b,x)在满足约束条件的情况下就是f(x),因此我们的目标函数可以写为 min_x max_{a,b} L(a,b,x)。如果用对偶表达式: max_{a,b} min_x L(a,b,x),由于我们的优化是满足强对偶的(强对偶就是说对偶式子的最优值是等于原问题的最优值的),所以在取得最优值x0的条件下,它满足 f(x0) = max_{a,b} min_x L(a,b,x) = min_x max_{a,b} L(a,b,x) =f(x0),我们来看看中间两个式子发生了什么事情:
f(x0) = max_{a,b} min_x L(a,b,x) = max_{a,b} min_x f(x) + a*g(x) + b*h(x) = max_{a,b} f(x0)+a*g(x0)+b*h(x0) = f(x0)
可以看到上述加黑的地方本质上是说 min_x f(x) + a*g(x) + b*h(x) 在x0取得了最小值,用Fermat定理,即是说对于函数 f(x) + a*g(x) + b*h(x),求取导数要等于零,即
f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
这就是KKT条件中第一个条件:L(a, b, x)对x求导为零。
而之前说明过,a*g(x) = 0,这时KKT条件的第3个条件,当然已知的条件h(x)=0必须被满足,所有上述说明,满足强对偶条件的优化问题的最优值都必须满足KKT条件,即上述说明的三个条件。可以把KKT条件视为是拉格朗日乘子法的泛化。
上面跑题了,下面我继续我们的SVM之旅。
经过拉格朗日乘子法和KKT条件推导之后
最终问题转化为:
最大化: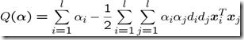
条件:

这个是著名的QP问题。决策面: 其中
其中  为问题的优化解。
为问题的优化解。
松弛变量(slack vaviable)
由于在采集数据的过程中,也可能有误差(如图)
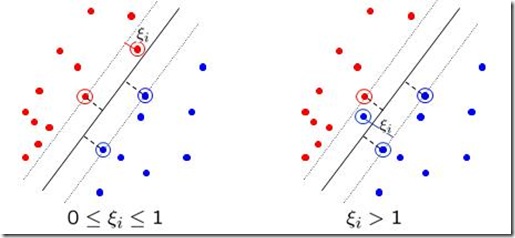
所以我们引入松弛变量对问题进行优化。
 式子就变为
式子就变为
最终转化为下面的优化问题:

其中的C是惩罚因子,是一个由用户去指定的系数,表示对分错的点加入多少的惩罚,当C很大的时候,分错的点就会更少,但是过拟合的情况可能会比较严重,当C很小的时候,分错的点可能会很多,不过可能由此得到的模型也会不太正确。
上面那个个式子看似复杂,现在我带大家一起推倒一下
……
…(草稿纸上,敲公式太烦人了)
最终得到:
最大化:
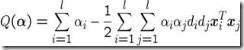
条件:

呵呵,是不是感觉和前面的式子没啥区别内,亲,数学就是这么美妙啊。
这个式子看起来beautiful,但是多数情况下只能解决线性可分的情况,只可以对线性可分的样本做处理。如果提供的样本线性不可分,结果很简单,线性分类器的求解程序会无限循环,永远也解不出来。但是不怕不怕。我们有杀手锏还没有出呢。接着咱要延伸到一个新的领域:核函数。嘻嘻,相信大家都应该听过这厮的大名,这个东东在60年代就提出来,可是直到90年代才开始火起来(第二春哈),主要是被Vapnik大大翻出来了。这也说明计算机也要多研读经典哈,不是说过时了就不看的,有些大师的论文还是有启发意义的。废话不多说,又跑题了。
核函数
那到底神马是核函数呢?
介个咱得先介绍一下VC维的概念。
为了研究经验风险最小化函数集的学习一致收敛速度和推广性,SLT定义了一些指标来衡量函数集的性能,其中最重要的就是VC维(Vapnik-Chervonenkis Dimension)。
VC维定义:对于一个指示函数(即只有0和1两种取值的函数)集,如果存在h个样本能够被函数集里的函数按照所有可能的2h种形式分开,则称函数集能够把h个样本打散,函数集的VC维就是能够打散的最大样本数目。
如果对任意的样本数,总有函数能打散它们,则函数集的VC维就是无穷大。
看图比较方便(三个点分类,线性都可分的)。
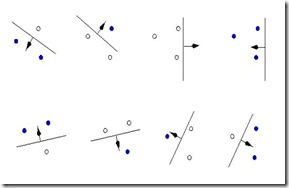
如果四个点呢?哈哈,右边的四个点要分为两个类,可能就分不啦。

如果四个点,一条线可能就分不过来啦。
一般而言,VC维越大, 学习能力就越强,但学习机器也越复杂。
目前还没有通用的关于计算任意函数集的VC维的理论,只有对一些特殊函数集的VC维可以准确知道。
N维实数空间中线性分类器和线性实函数的VC维是n+1。
Sin(ax)的VC维为无穷大。
对于给定的学习函数集,如何计算其VC维是当前统计学习理论研究中有待解决的一个难点问题,各位童鞋有兴趣可以去研究研究。
咱们接着要说说为啥要映射。
例子是下面这张图:
下面这段来自百度文库
俺觉得写的肯定比我好,所以咱就选择站在巨人的肩膀上啦。
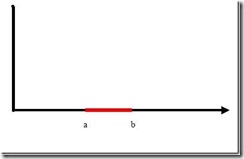
我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
但我们可以找到一条曲线,例如下面这一条:

显然通过点在这条曲线的上方还是下方就可以判断点所属的类别(你在横轴上随便找一点,算算这一点的函数值,会发现负类的点函数值一定比0大,而正类的一定比0小)。这条曲线就是我们熟知的二次曲线,它的函数表达式可以写为:
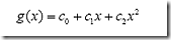
问题只是它不是一个线性函数,但是,下面要注意看了,新建一个向量y和a:

这样g(x)就可以转化为f(y)=<a,y>,你可以把y和a分别回带一下,看看等不等于原来的g(x)。用内积的形式写你可能看不太清楚,实际上f(y)的形式就是:
g(x)=f(y)=ay
在任意维度的空间中,这种形式的函数都是一个线性函数(只不过其中的a和y都是多维向量罢了),因为自变量y的次数不大于1。
看出妙在哪了么?原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。
而转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。具体到我们的文本分类问题,文本被表示为上千维的向量,即使维数已经如此之高,也常常是线性不可分的,还要向更高的空间转化。其中的难度可想而知。
为什么说f(y)=ay是四维空间里的函数?
大家可能一时没看明白。回想一下我们二维空间里的函数定义 g(x)=ax+b 变量x是一维的,为什么说它是二维空间里的函数呢?因为还有一个变量我们没写出来,它的完整形式其实是 y=g(x)=ax+b 即 y=ax+b 看看,有几个变量?两个。那是几维空间的函数? 再看看 f(y)=ay 里面的y是三维的变量,那f(y)是几维空间里的函数?
用一个具体文本分类的例子来看看这种向高维空间映射从而分类的方法如何运作,想象一下,我们文本分类问题的原始空间是1000维的(即每个要被分类的文档被表示为一个1000维的向量),在这个维度上问题是线性不可分的。现在我们有一个2000维空间里的线性函数
f(x')=<w',x'>+b
注意向量的右上角有个 '哦。它能够将原问题变得可分。式中的 w'和x'都是2000维的向量,只不过w'是定值,而x'是变量(好吧,严格说来这个函数是2001维的,哈哈),现在我们的输入呢,是一个1000维的向量x,分类的过程是先把x变换为2000维的向量x',然后求这个变换后的向量x'与向量w'的内积,再把这个内积的值和b相加,就得到了结果,看结果大于阈值还是小于阈值就得到了分类结果。
你发现了什么?我们其实只关心那个高维空间里内积的值,那个值算出来了,分类结果就算出来了。而从理论上说, x'是经由x变换来的,因此广义上可以把它叫做x的函数(有一个x,就确定了一个x',对吧,确定不出第二个),而w'是常量,它是一个低维空间里的常量w经过变换得到的,所以给了一个w 和x的值,就有一个确定的f(x')值与其对应。这让我们幻想,是否能有这样一种函数K(w,x),他接受低维空间的输入值,却能算出高维空间的内积值<w',x'>?
如果有这样的函数,那么当给了一个低维空间的输入x以后,
g(x)=K(w,x)+b
f(x')=<w',x'>+b
这两个函数的计算结果就完全一样,我们也就用不着费力找那个映射关系,直接拿低维的输入往g(x)里面代就可以了(再次提醒,这回的g(x)就不是线性函数啦,因为你不能保证K(w,x)这个表达式里的x次数不高于1哦)。
万幸的是,这样的K(w,x)确实存在(发现凡是我们人类能解决的问题,大都是巧得不能再巧,特殊得不能再特殊的问题,总是恰好有些能投机取巧的地方才能解决,由此感到人类的渺小),它被称作核函数(核,kernel),而且还不止一个,事实上,只要是满足了Mercer条件的函数,都可以作为核函数。核函数的基本作用就是接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。几个比较常用的核函数,俄,教课书里都列过,我就不敲了(懒!)。
回想我们上节说的求一个线性分类器,它的形式应该是:
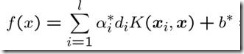
现在这个就是高维空间里的线性函数(为了区别低维和高维空间里的函数和向量,我改了函数的名字,并且给w和x都加上了 '),我们就可以用一个低维空间里的函数(再一次的,这个低维空间里的函数就不再是线性的啦)来代替,
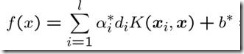
又发现什么了?f(x') 和g(x)里的α,y,b全都是一样一样的!这就是说,尽管给的问题是线性不可分的,但是我们就硬当它是线性问题来求解,只不过求解过程中,凡是要求内积的时候就用你选定的核函数来算。这样求出来的α再和你选定的核函数一组合,就得到分类器啦!
明白了以上这些,会自然的问接下来两个问题:
1. 既然有很多的核函数,针对具体问题该怎么选择?
2. 如果使用核函数向高维空间映射后,问题仍然是线性不可分的,那怎么办?
第一个问题现在就可以回答你:对核函数的选择,现在还缺乏指导原则!各种实验的观察结果(不光是文本分类)的确表明,某些问题用某些核函数效果很好,用另一些就很差,但是一般来讲,径向基核函数是不会出太大偏差的一种,首选。(我做文本分类系统的时候,使用径向基核函数,没有参数调优的情况下,绝大部分类别的准确和召回都在85%以上。
感性理解,映射图:

常用的两个Kernel函数:
多项式核函数:
高斯核函数:
定义: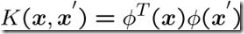
将核函数带入,问题又转化为线性问题啦,如下:
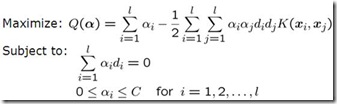
求 ,其中
,其中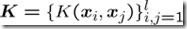
式子是有了,但是如何求结果呢?不急不急,我会带着大家一步一步的解决这个问题,并且通过动手编程使大家对这个有个问题有个直观的认识。(PS:大家都对LIBSVM太依赖了,这样无助于深入的研究与理解,而且我觉得自己动手实现的话会比较有成就感)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

SVM基本概念及Python实现代码
SVM(support vector machine)支持向量机: 注意:本文不准备提到数学证明的过程,一是因为有一篇非常好的文章解释的非常好:支持向量机通俗导论(理解SVM的三层境界),另一方面是因为我只是个程序员,不是搞数学的(主要是因为数学不好.),主要目的是将SVM以最通俗易懂,简单粗暴的方式解释清楚. 线性分类: 先从线性可分的数据讲起,如果需要分类的数据都是线性可分的,那么只需要一根直线f(x)=wx+b就可以分开了,类似这样: 这种方法被称为:线性分类器,一个线性分类器的学习目标便
-
Python中使用支持向量机SVM实践
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)SVM一般
-
Python中支持向量机SVM的使用方法详解
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类.因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm. 一.导入sklearn算法包 Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明 skleran中集成了许多算法,其导入包的方式如下所示, 逻辑回归:from sklearn.linear_model import LogisticRegression 朴素贝叶斯:fro
-
Python中使用支持向量机(SVM)算法
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)S
-
Python机器学习之SVM支持向量机
SVM支持向量机是建立于统计学习理论上的一种分类算法,适合与处理具备高维特征的数据集. SVM算法的数学原理相对比较复杂,好在由于SVM算法的研究与应用如此火爆,CSDN博客里也有大量的好文章对此进行分析,下面给出几个本人认为讲解的相当不错的: 支持向量机通俗导论(理解SVM的3层境界) JULY大牛讲的是如此详细,由浅入深层层推进,以至于关于SVM的原理,我一个字都不想写了..强烈推荐. 还有一个比较通俗的简单版本的:手把手教你实现SVM算法 SVN原理比较复杂,但是思想很简单,一句话概括,就
-
手把手教你python实现SVM算法
什么是机器学习 (Machine Learning) 机器学习是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能.它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域. 机器学习的大致分类: 1)分类(模式识别):要求系统依据已知的分类知识对输入的未知模式(该模式的描述)作分析,以确定输入模式的类属,例如手写识别(识别是不是这个数). 2)问题求解:要求对于给定的目标状态,寻找一个将当前状态转换为目标状态的动作序
-
详解python 支持向量机(SVM)算法
相比于逻辑回归,在很多情况下,SVM算法能够对数据计算从而产生更好的精度.而传统的SVM只能适用于二分类操作,不过却可以通过核技巧(核函数),使得SVM可以应用于多分类的任务中. 本篇文章只是介绍SVM的原理以及核技巧究竟是怎么一回事,最后会介绍sklearn svm各个参数作用和一个demo实战的内容,尽量通俗易懂.至于公式推导方面,网上关于这方面的文章太多了,这里就不多进行展开了~ 1.SVM简介 支持向量机,能在N维平面中,找到最明显得对数据进行分类的一个超平面!看下面这幅图: 如上图中,
-
Python利用 SVM 算法实现识别手写数字
目录 前言 使用 SVM 进行手写数字识别 参数 C 和 γ 对识别手写数字精确度的影响 完整代码 前言 支持向量机 (Support Vector Machine, SVM) 是一种监督学习技术,它通过根据指定的类对训练数据进行最佳分离,从而在高维空间中构建一个或一组超平面.在博文<OpenCV-Python实战(13)--OpenCV与机器学习的碰撞>中,我们已经学习了如何在 OpenCV 中实现和训练 SVM 算法,同时通过简单的示例了解了如何使用 SVM 算法.在本文中,我们将学习如何
-
手把手教你Python yLab的绘制折线图的画法
Python的可视化工具有很多,数不胜数,各有优劣.本文就对其中的pylab进行介绍.之所以介绍这一款,是因为它和Matlab的强烈相似度,如果你使用过Matlab,那么相信pylab你也会很快上手. 简单的plot函数 pylab绘图,最基本的函数就是plot函数,当然如果想要将图片显示出来,需要额外添加一个show函数. 在python的绘图中,numpy是一个非常常用的工具,不太熟悉的可以参考博主的另一篇博文:[Python]Python之Numpy的超实用基础详细教程. 例如: impo
-
手把手教你Python抓取数据并可视化
目录 前言 一.数据抓取篇 1.简单的构建反爬措施 2.解析数据 3.完整代码 二.数据可视化篇 1.数据可视化库选用 2.案例实战 (1).柱状图Bar (2).地图Map (3).饼图Pie (4).折线图Line (5).组合图表 总结 前言 大家好,这次写作的目的是为了加深对数据可视化pyecharts的认识,也想和大家分享一下.如果下面文章中有错误的地方还请指正,哈哈哈!!!本次主要用到的第三方库: requests pandas pyecharts 之所以数据可视化选用pyechar
-
手把手教你用python抢票回家过年(代码简单)
首先看看如何快速查看剩余火车票? 当你想查询一下火车票信息的时候,你还在上12306官网吗?或是打开你手机里的APP?下面让我们来用Python写一个命令行版的火车票查看器, 只要在命令行敲一行命令就能获得你想要的火车票信息!如果你刚掌握了Python基础,这将是个不错的小练习. 接口设计 一个应用写出来最终是要给人使用的,哪怕只是给你自己使用.所以,首先应该想想你希望怎么使用它?让我们先给这个小应用起个名字吧,既然及查询票务信息,那就叫它tickets好了.我们希望用户只要输入出发站,到达站以
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-
手把手教你进行Python虚拟环境配置教程
/1 前言/ 咱们今天就来说一下Python的虚拟环境,可能有的小伙伴会疑惑,Python的虚拟环境有什么用呢?接下来我们一起来探讨一下. /2 虚拟环境的作用/ 咱们今天就来说一下Python的虚拟环境,可能有的小伙伴会疑惑,Python的虚拟环境有什么用呢?接下来我们一起来探讨一下. 我们先来举个例子,来说明为什么需要虚拟环境.我们在学习Python的时候,可能会学到越来越多的第三方库,比如爬虫,我们需要安装requests,可能学着学着,我们还需要安装bs4,或者又学着学着,我们还需要安装
-
手把手教你用python发送短消息(基于阿里云平台)
本次是纯发送演示,一步步讲解如何让发送成功,后继会介绍与网站注册功能的结合运用,敬请关注"有只狗狗叫多多" 一.首先,注册阿里云账号一个,完成实名认证,然后在产品中找到短信服务,选择免费开通 这里还是要推荐下小编的Python学习群:483546416,不管你是小白还是大牛,小编我都欢迎,不定期分享干货,包括小编自己整理的一份2017最新的Python资料和0基础入门教程,欢迎初学和进阶中的小伙伴.在不忙的时间我会给大家解惑. 二.控制台生成后,进入短信控制台,获取你的AK,保留备用,
-
手把手教你怎么用Python实现zip文件密码的破解
Python有一个内置模块zipfile可以干这个事情,测试一波,一个测试文件,设置解压密码为123. import zipfile # 创建文件句柄 file = zipfile.ZipFile("测试.zip", 'r') # 提取压缩文件中的内容,注意密码必须是bytes格式,path表示提取到哪 file.extractall(path='.', pwd='123'.encode('utf-8')) 运行效果如下图所示,提取成功. 好了开始破解老文件的密码,为了提高速度我加了多