Django之使用haystack+whoosh实现搜索功能
为了实现项目中的搜索功能,我们使用的是全文检索框架haystack+搜索引擎whoosh+中文分词包jieba
安装和配置
安装所需包
pip install django-haystack pip install whoosh pip install jieba
去settings文件注册haystack应用
INSTALLED_APPS = [ 'haystack', # 注册全文检索框架 ]
在settings文件中配置全文检索框架
# 全文检索框架的配置
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
索引文件的生成
要生成索引文件,首先你要配置,对哪些内容进行索引,比如商品名称,简介和详情;为了配置对数据库指定内容进行索引,我们要做如下步骤:
配置search_indexes.py文件
因为在django中数据库一般都是通过ORM生成的,首先我们在要在数据表对应的应用中创建一个 search_indexes.py 文件,例如,我现在要检索商品对应的表就是GoodsSKU表,而表是在goods应用下的,所以我在goods应用下新建 search_indexes.py 文件,截图如下:
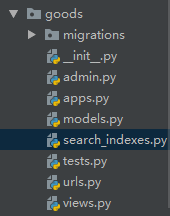
在 search_indexes.py 文件中加入以下内容
# 定义索引类
from haystack import indexes
# 导入你的模型类
from goods.models import GoodsSKU
# 指定对于某个类的某些数据建立索引
# 索引类名格式:模型类名+Index
class GoodsSKUIndex(indexes.SearchIndex, indexes.Indexable):
# 索引字段 use_template=True指定根据表中的哪些字段建立索引文件的说明放在一个文件中
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
# 返回你的模型类
return GoodsSKU
# 建立索引的数据
def index_queryset(self, using=None):
return self.get_model().objects.all()
指定要检索的内容
在templates文件夹下面新建search文件夹,在search文件夹下面新建indexes文件夹,在indexes文件夹下面新建要检索应用名的文件夹比如goods文件夹,在goods文件夹下面新建 表名_text.txt,表名小写,所以目前的目录结构是这样的 templates/search/indexes/goods/goodssku_text.txt ,截图如下:
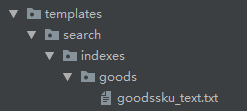
在goodssku_text.txt 文件中指定你要根据表中的哪些字段建立索引数据,现在我们要根据商品的名称,简介,详情来建立索引,如下配置
# 指定根据表中的哪些字段建立索引数据
{{ object.name }} # 根据商品的名称建立索引
{{ object.desc }} # 根据商品的简介建立索引
{{ object.goods.detail }} # 根据商品的详情建立索引
其中的objects可以理解为数据表对应的商品对象。
生成索引文件
使用pycharm自带的命令行terminal运行以下命令生成索引文件:
python manage.py rebuild_index
运行成功后,你可以在项目下看到类似如下索引文件

使用全文检索
通过如上的配置,我们的数据索引已经建立了,现在我们要在项目中使用全文检索。
在需要使用检索的地方进行 form 表单改造
<form action="/search" method="get"> <input type="text" class="input_text fl" name="q" placeholder="搜索商品"> <input type="submit" class="input_btn fr" name="" value="搜索"> </form>
如上所示,其中要注意的是:
发送方式必须使用get;
搜索的input框 name 必须是 q;
配置检索对应的url
在项目下的urls.py文件中添加如下url配置
urlpatterns = [
url(r'^search/', include('haystack.urls')), # 全文检索框架
]
检索成功后生成的参数
当haystack自动检索成功后,会给我们返回三个参数;
query参数,表示你查询的参数;
page参数,当前页的Page对象,是查询到的对象的集合,可以通过for循环类获取单个商品,通过 商品.objects.xxx 获取商品对应的字段;
paginator参数,分页paginator对象。
可以通过如下代码测试参数
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body>
搜索的关键字:{{ query }}<br/>
当前页的Page对象:{{ page }}<br/>
<ul>
{% for item in page %}
<li>{{ item.object }}</li>
{% endfor %}
</ul>
分页paginator对象:{{ paginator }}<br/>
</body>
</html>
templates/indexes/search.html
注意,位置和文件名都是固定的,并且这只是测试文件,后面使用全文检索时记得不能使用search.html,改成其他名字。
数据+search.html返回渲染后页面
当haystack全文检索后会返回数据,现在我们需要一个页面来接收这些数据,并且在页面渲染后返回这个页面给用户观看,渲染并返回页面的工作haystack已经帮我们做了,那么我们现在只需要准备一个页面容纳数据即可。
在templates文件夹下的indexes文件夹下新建一个search.html,注意路径和文件名是固定的,如下图

利用检索返回的参数在search.html中定义要渲染出的模板和样式,我的页面如下
<div class="breadcrumb">
<a href="#">{{ query }}</a>
<span>></span>
<a href="#">搜索结果如下:</a>
</div>
<div class="main_wrap clearfix">
<ul class="goods_type_list clearfix">
{% for item in page %}
<li>
<a href="{% url 'goods:detail' item.object.id %}"><img src="{{ item.object.image.url }}"></a>
<h4><a href="{% url 'goods:detail' item.object.id %}">{{ item.object.name }}</a></h4>
<div class="operate">
<span class="prize">¥{{ item.object.price }}</span>
<span class="unit">{{ item.object.price}}/{{ item.object.unite }}</span>
<a href="#" class="add_goods" title="加入购物车"></a>
</div>
</li>
{% endfor %}
</ul>
<div class="pagenation">
{% if page.has_previous %}
<a href="/search?q={{ query }}&page={{ page.previous_page_number }}"><上一页</a>
{% endif %}
{% for pindex in paginator.page_range %}
{% if pindex == page.number %}
<a href="/search?q={{ query }}&page={{ pindex }}" class="active">{{ pindex }}</a>
{% else %}
<a href="/search?q={{ query }}&page={{ pindex }}">{{ pindex }}</a>
{% endif %}
{% endfor %}
{% if page.has_next %}
<a href="/search?q={{ query }}&page={{ page.next_page_number }}">下一页></a>
{% endif %}
</div>
</div>
search.html
至此,我们可以在页面上搜索一下内容,应该是能成功的,但也有可能不会返回任何数据就算name就是你搜索的内容,这是因为我们现在使用的主要还是为英语服务的分词包,接下来我们要配置使用中文分词包了。
使用中文分词包jieba
在前面的配置中我们已经安装了jieba;
创建 ChineseAnalyzer.py 文件
进入虚拟环境下的 Lib\site-packages\haystack\backends 目录下新建 ChineseAnalyzer.py 文件
目录如下图
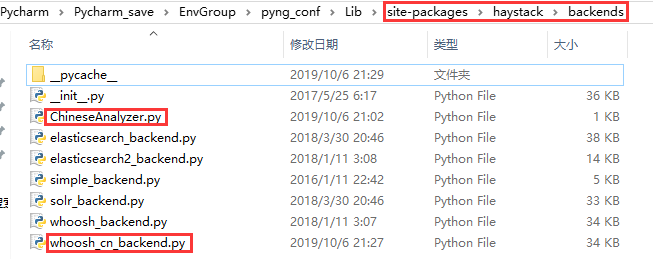
在文件中添加如下内容
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
ChineseAnalyzer.py
编写haystack可使用的 whoosh_cn_backend.py 文件
直接在 虚拟环境下的 Lib\site-packages\haystack\backends 目录下复制一份 whoosh_backend.py 文件 并且重命名复制文件为 whoosh_cn_backend.py;
在 whoosh_cn_backend.py 中导入我们编写的 ChineseAnalyzer 类
from .ChineseAnalyzer import ChineseAnalyzer
更改haystack使用的分词包为 jieba 编写的中文分词类,大概在第160行左右
# schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=StemmingAnalyzer(), field_boost=field_class.boost, sortable=True) schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=ChineseAnalyzer(), field_boost=field_class.boost, sortable=True)
配置whoosh引擎使用 whoosh_cn_backend.py
在settings文件中更改原来的配置如下
# 全文检索框架的配置
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
# 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
重新生成索引文件
python manage.py rebuild_index
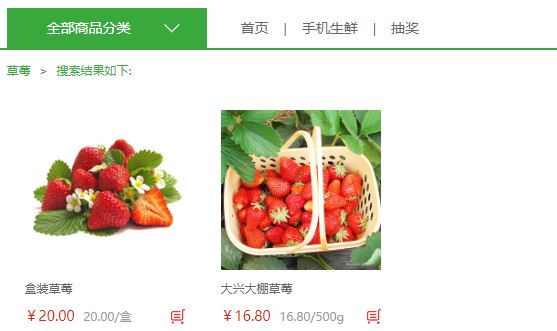
至此,就可以放心的使用搜索功能了,如图,搜索成功的显示页面
可以通过如下配置控制每个分页显示的搜索出来对象的数目
# 指定搜索结果每页显示的条数 HAYSTACK_SEARCH_RESULTS_PER_PAGE = 1
总结
以上所述是小编给大家介绍的Django之使用haystack+whoosh实现搜索功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Django集成搜索引擎Elasticserach的方法示例
1.背景 当用户在搜索框输入关键字后,我们要为用户提供相关的搜索结果.可以选择使用模糊查询 like 关键字实现,但是 like 关键字的效率极低.查询需要在多个字段中进行,使用 like 关键字也不方便,另外分词的效果也不理想. 全文检索方案 全文检索即在指定的任意字段中进行检索查询. 全文检索方案需要配合搜索引擎来实现. 搜索引擎原理 搜索引擎 进行全文检索时,会对数据库中的数据进行一遍预处理,单独建立起一份 索引结构数据 . 索引结构数据 类似字典的索引检索页 ,里面包含了关键词与词条的对
-
如何搜索查找并解决Django相关的问题
1. 卡住是怎么办 按照以下步骤, 前提是你需要懂点英文: 尽可能自己想办法解决 仔细阅读相关文档, 确保不错过任何相关内容 在Google, 百度, mailing lists或StackOverFlow上查看是否有人遇到相同问题 找不到? 在StackOverFlow上问问题, 需要使用小例子说明该问题, 并列出你的开发环境, 使用的软件版本 过了几天都没人回答? 到Django-users mailing list 或 django IRC中再提问 2. 如何问问题 IRC代表Intern
-

django使用haystack调用Elasticsearch实现索引搜索
前言: 在做一个商城项目的时候,需要实现商品搜索功能. 说到搜索,第一时间想到的是数据库的 select * from tb_sku where name like %苹果手机% 或者django的 SKU.objects.filter(name__contains="苹果手机") 但是,假如你的数据库有几千万条数据,name字段没有索引,可能查询需要十几分钟,用户可能会等你?那为什么不给name字段增加索引?商品表不仅仅是用来查询,也会经常修改数据,新增删除数据等.建立索引后,做增删
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-
pycharm+django创建一个搜索网页实例代码
本文主要研究的是pycharm+django创建一个搜索网页的实例代码,具体步骤和代码示例如下. 创建工程 比如,我创建的工程目录结构如下: 命令行 进入windows命令行,进入根目录: python manage.py startapp django_web 接着你会在pycharm中发现,多了一个django_web文件夹.如下将截图: 创建一个test.html <!DOCTYPE html> <html> <head> <title>开始搜索<
-
Django实现组合搜索的方法示例
一.实现方法 1.纯模板语言实现 2.自定义simpletag实现(本质是简化了纯模板语言的判断) 二.基本原理 原理都是通过django路由系统,匹配url筛选条件,将筛选条件作为数据库查询结果,返回给前端. 例如:路由系统中的url格式是这样: url(r'^article-(?P<article_type_id>\d+)-(?P<category_id>\d+).html',views.filter) 其中article_type_id和category_id和数据库中字段是
-
django 使用全局搜索功能的实例详解
安装需要的包 1 第一步: 全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理. haystack:全文检索的框架,支持whoosh.solr.Xapian.Elasticsearc四种全文检索引擎 whoosh:纯Python编写的全文搜索引擎对于小型的站点,whoosh已经足够使用 jieba:一款免费的中文分词包 1)在虚拟环境中依次安装需要的包. pip install django-haystack pip install whoosh pip in
-
Django项目之Elasticsearch搜索引擎的实例
1.使用Docker安装Elasticsearch及其扩展 获取镜像,可以通过网络pull sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0 或者加载镜像文件 sudo docker load -i elasticsearch-ik-2.4.6_docker.tar 修改elasticsearch的配置文件 elasticsearc-2.4.6/config/elasticsearch.yml第54行,更改ip地址为本机ip地址 n
-
python中django框架通过正则搜索页面上email地址的方法
本文实例讲述了python中django框架通过正则搜索页面上email地址的方法.分享给大家供大家参考.具体实现方法如下: import re from django.shortcuts import render from pattern.web import URL, DOM, abs, find_urls def index(request): """ find email addresses in requested url or contact page &quo
-
Django之使用haystack+whoosh实现搜索功能
为了实现项目中的搜索功能,我们使用的是全文检索框架haystack+搜索引擎whoosh+中文分词包jieba 安装和配置 安装所需包 pip install django-haystack pip install whoosh pip install jieba 去settings文件注册haystack应用 INSTALLED_APPS = [ 'haystack', # 注册全文检索框架 ] 在settings文件中配置全文检索框架 # 全文检索框架的配置 HAYSTACK_CONNECT
-
Django xadmin开启搜索功能的实现
应用目录下adminx.py class EmailVerifyRecordAdmin(object): search_fields = ['code','email','send_type'] 过滤器搜索 class EmailVerifyRecordAdmin(object): list_filter = ['code','email','send_type','send_time'] 以上这篇Django xadmin开启搜索功能的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,
-
Django用内置方法实现简单搜索功能的方法
Model中分别提供了filter方法和icontains方法实现简单的搜索功能. html页面中实现搜索框 模板api_test_manage.html中增加以下内容 <form method='get' action='/api_search/'> {% csrf_token %} <input type='search' name='api_test_name' placeholder='流程接口名称' required> <button type='submit'&g
-
Django利用elasticsearch(搜索引擎)实现搜索功能
1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.10/topics/http/urls/ Examples: Function views 1. Add an import: from my_ap
-
在Python的Flask框架中实现全文搜索功能
全文检索引擎入门 灰常不幸的是,关系型数据库对全文检索的支持没有被标准化.不同的数据库通过它们自己的方式来实现全文检索,而且SQLAlchemy在全文检索上也没有提供一个好的抽象. 我们现在使用SQLite作为我们的数据库,所以我们可以绕开SQLAlchemy而使用SQLite提供的工具来创建一个全文检索索引.但这么做不怎么好,因为如果有一天我们换用别的数据库,那么我们就得重写另一个数据库的全文检索方法. 所以我们的方案是,我们将让我们现有的数据库处理常规数据,然后我们创建一个专门的数据库来解
-
Django中使用pillow实现登录验证码功能(带刷新验证码功能)
首先在项目里建立common目录,编写验证码的函数 verification_code.py import random from PIL import Image, ImageFont, ImageDraw def get_code(): mode = 'RGB' bg_width = 180 #这个是验证码那个框框的宽度 bg_height = 30 #这个是验证码那个框框的高度 bg_size = (bg_width, bg_height) bg_color = (255, 255, 25
-
vue与django(drf)实现文件上传下载功能全过程
目录 文件上传功能 上传后端部分 上传前端部分(vue添加vue.js和node.js,设置eslint) 文件下载功能 下载后端部分 下载前端部分 总结 文件上传功能 上传后端部分 (一)Models.py from django.db import models class FilesModel(models.Model): //模型名(默认表名) name = models.CharField(max_length=20, default='') //name,fle是字段名(file为上
-
使用Bootrap和Vue实现仿百度搜索功能
用Vue调用百度的搜索接口,实现简单的搜索功能. 搜索框的样式是基于Bootstrap,当然对样式做了简单的调整, 使之类似于百度搜索.代码如下 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>百度搜索</title> <style type="text/css"> .gray{ background-color
-
ThinkPHP实现ajax仿官网搜索功能实例
本文实例讲述了ThinkPHP实现ajax仿官网搜索功能的方法.分享给大家供大家参考. 具体实现方法如下: 后台代码: 复制代码 代码如下: //搜索,如果在1不在0 function search(){ $keyword = $_POST['search']; $Goods=M('goods'); //这里我做的一个模糊查询到名字或者对应的id,主要目的因为我这个系统是 //商城系统里面用到直接看产品ID $map['goods_id|goods_n
-
JS实现表格数据各种搜索功能的方法
本文实例讲述了JS实现表格数据各种搜索功能.可忽略大小写,模糊搜索,多关键搜索.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title></title> <script type="text/javascript"> window.onl