正则表达式re.sub替换不完整的问题及完整解决方案
title: 正则表达式re.sub替换不完整的问题现象及其根本原因
toc: true
comment: true
date: 2018-08-27 21:48:22
tags: ["Python", "正则表达式"]
category: ["Python"]
---
问题描述
问题的起因来自于一段正则替换。为了从一段HTML代码里面提取出正文,去掉所有的HTML标签和属性,可以写一个Python函数:
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text
这段代码的使用了正则表达式的替换功能re.sub。这个函数的第一个参数表示需要被替换的内容的正则表达式,由于HTML标签都是使用尖括号包起来的,因此使用<.*?>就可以匹配所有<xxx yyy="zzz">和</xxx>。
第二个参数表示被匹配到的内容将要被替换成什么内容。由于我需要提取正文,那么只要把所有HTML标签都替换为空字符串即可。第三个参数就是需要被替换的文本,在这个例子中是HTML源代码段。
至于re.S,在4年前的一篇文章中我讲到了它的用法:https://www.jb51.net/article/146384.htm
现在使用一段HTML代码来测试一下:
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text
source_1 = '''
<div class="content">今天的主角是<a href="xxx">kingname</a>,我们掌声欢迎!</div>
'''
text = remove_tag(source_1)
print(text)
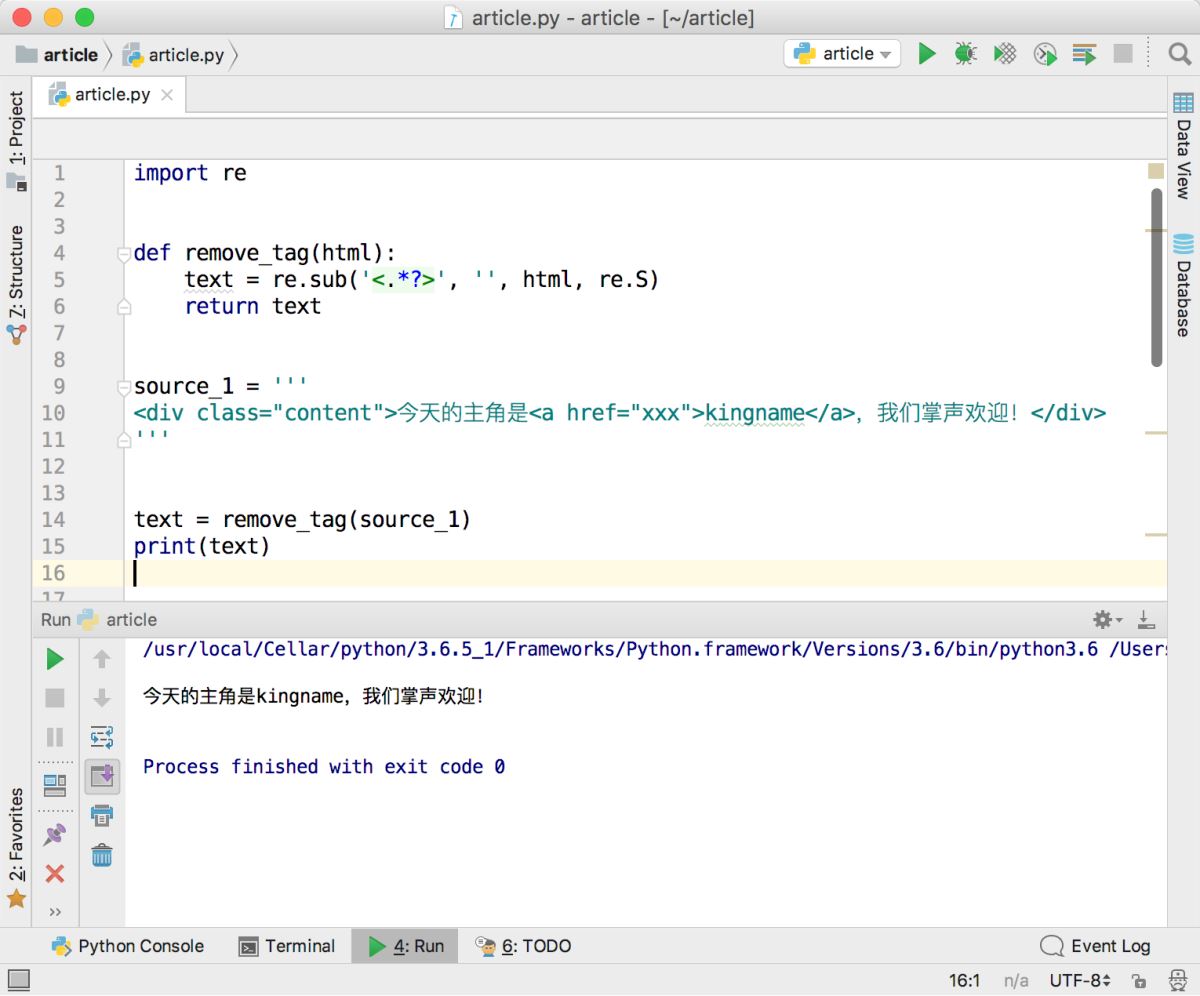
运行效果如下图所示,功能完全符合预期
再来测试一下代码中有换行符的情况:
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text
source_2 = '''
<div class="content">
今天的主角是
<a href="xxx">kingname</a>
,我们掌声欢迎!
</div>
'''
text = remove_tag(source_2)
print(text)
运行效果如下图所示,完全符合预期。

经过测试,在绝大多数情况下,能够从的HTML代码段中提取出正文。但也有例外。
例外情况
有一段HTML代码段比较长,内容如下:
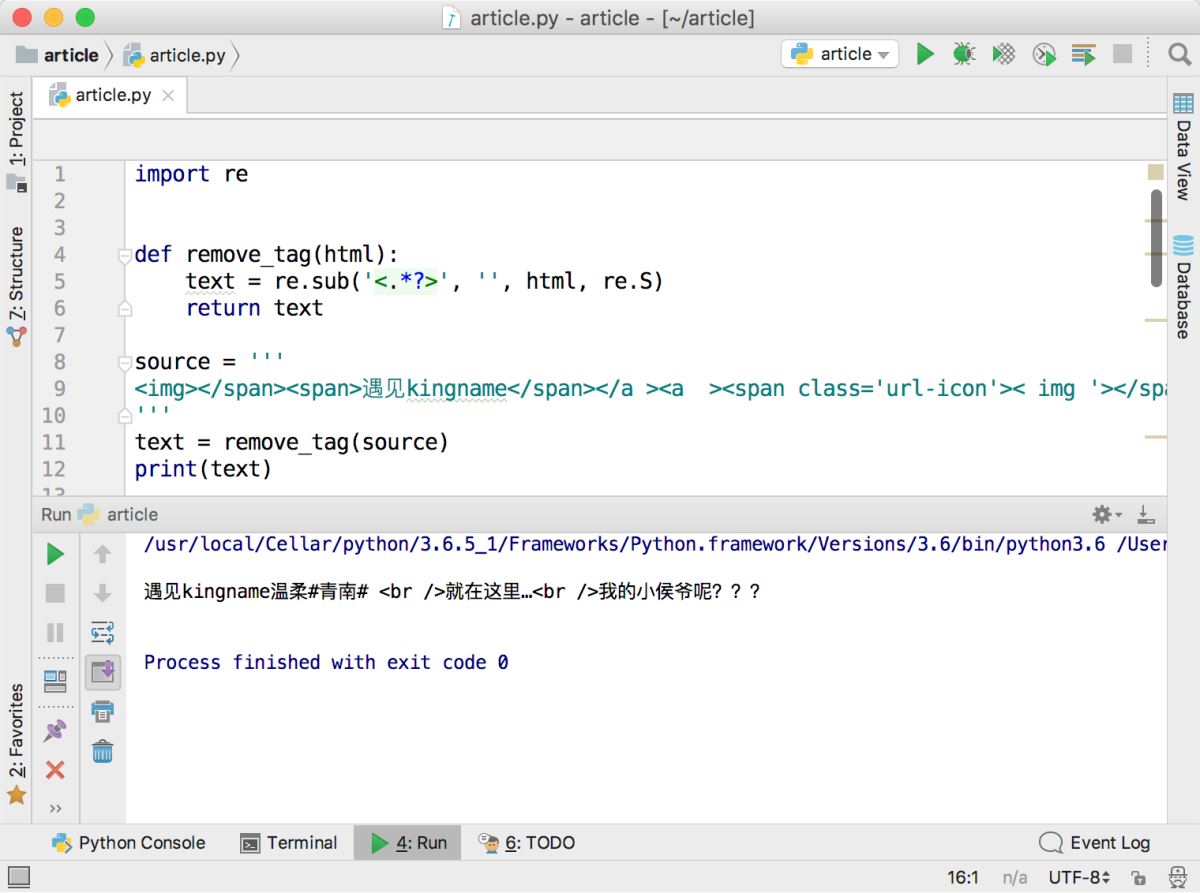
<img> </span><span>遇见kingname</span></a ><a ><span class='url-icon'>< img '></span><span >温柔</span></a ><a ><span >#青南#</span></a > <br />就在这里…<br />我的小侯爷呢???
运行效果如下图所示,最后两个HTML标签替换失败。
一开始我以为是HTML里面的空格或者引号引起的问题,于是我把HTML代码进行简化:
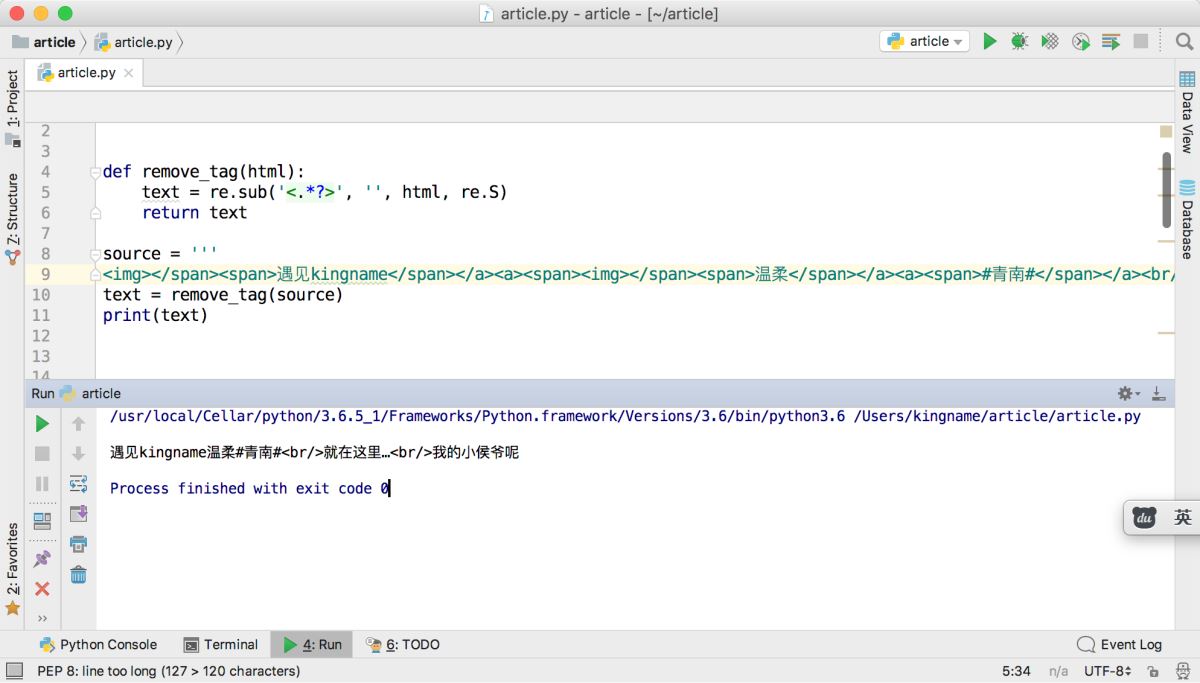
<img></span><span>遇见kingname</span></a><a><span><img></span><span>温柔</span></a><a><span>#青南#</span></a><br/>就在这里…<br/>我的小侯爷呢
问题依然存在,如下图所示。
而且更令人惊讶的是,如果把第一个标签<img>删了,那么替换结果里面就少了一个标签,如下图所示。

实际上,不仅仅是删除第一个标签,前面任意一个标签删了都可以减少结果里面的一个标签。如果删除前面两个或以上标签,那么结果就正常了。
答疑解惑
这个看起来很奇怪的问题,根本原因在re.sub的第4个参数。从函数原型可以看到:
def sub(pattern, repl, string, count=0, flags=0)
第四个参数是count表示替换个数,re.S如果要用,应该作为第五个参数。所以如果把remove_tag函数做一些修改,那么结果就正确了:
def remove_tag(html):
text = re.sub('<.*?>', '', html, flags=re.S)
return text
那么问题来了,把re.S放在count的位置,为什么代码没有报错?难道re.S是数字?实际上,如果打印一下就会发现,re.S确实可以作为数字:
>>> import re >>> print(int(re.S)) 16
现在回头数一数出问题的HTML代码,发现最后多出来的两个<br>标签,刚刚好是第17和18个标签,而由于count填写的re.S可以当做16来处理,那么Python就会把前16个标签替换为空字符串,从而留下最后两个。
至此问题的原因搞清楚了。
这个问题没有被及早发现,有以下几个原因:
被替换的HTML代码是代码段,大多数情况下HTML标签不足16个,所以问题被隐藏。re.S是一个对象,但也是数字,count接收的参数刚好也是数字。在很多编程语言里面,常量都会使用数字,然后用一个有意义的大写字母来表示。re.S 处理的情况是<div \n> 而不是<div>\n</div>但测试的代码段标签都是第二种情况,所以在代码段里面实际上加不加re.S效果是一样的。
补充:下面在给大家介绍下正则表达式 re.sub()替换功能
re.sub()替换功能
re.sub是个正则表达式方面的函数,用来实现通过正则表达式,实现比普通字符串的replace更加强大的替换功能。简单的替换功能可以使用replace()实现。
def main():
text = '123, word!'
text1 = text.replace('123', 'Hello')
print(text1)
if __name__ == '__main__':
main()
# Hello, wold!
如果通过re.sub(0函数则可以匹配任意的数字,并将其替换:
import re def main(): content = 'abc124hello46goodbye67shit' list1 = re.findall(r'\d+', content) print(list1) mylist = list(map(int, list1)) print(mylist) print(sum(mylist)) print(re.sub(r'\d+[hg]', 'foo1', content)) print() print(re.sub(r'\d+', '456654', content)) if __name__ == '__main__': main() # ['124', '46', '67'] # [124, 46, 67] # 237 # abcfoo1ellofoo1oodbye67shit # abc456654hello456654goodbye456654shit
总结
以上所述是小编给大家介绍的正则表达式re.sub替换不完整的问题及完整解决方案,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Python正则表达式中的re.S的作用详解
Python 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. 本章节给大家介绍P
-
Python使用正则表达式获取网页中所需要的信息
使用正则表达式的几个步骤: 1.用import re 导入正则表达式模块: 2.用re.compile()函数创建一个Regex对象: 3.用Regex对象的search()或findall()方法,传入想要查找的字符串,返回一个Match对象: 4.调用Match对象的group()方法,返回匹配到的字符串. 在交互式环境中简单尝试一下,查询字符串中的固话: import re text = '小明家的固话是0755-123456,而小丽家的固话时0789-654321,小王家的电话是1234
-
python 正则表达式 re.sub & re.subn
python正则表达式模块简介 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式.Python 1.5之前版本则是通过 regex 模块提供 Emacs 风格的模式.Emacs 风格模式可读性稍差些,而且功能也不强,因此编写新代码时尽量不要再使用 regex 模块,当然偶尔你还是可能在老代码里发现其踪影. 就其本质而言,正则表达式(或 RE)是一种小型的.高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现.使用这个小型语言
-
正则表达式re.sub替换不完整的问题及完整解决方案
title: 正则表达式re.sub替换不完整的问题现象及其根本原因 toc: true comment: true date: 2018-08-27 21:48:22 tags: ["Python", "正则表达式"] category: ["Python"] --- 问题描述 问题的起因来自于一段正则替换.为了从一段HTML代码里面提取出正文,去掉所有的HTML标签和属性,可以写一个Python函数: import re def remove
-
javascript正则表达式使用replace()替换手机号的方法
本文实例讲述了javascript正则表达式使用replace()替换手机号的方法.分享给大家供大家参考. 具体实现方法如下: 复制代码 代码如下: <html> <head> <title>javascript正则表达式使用replace()替换手机号</title> <meta http-equiv="content-type" content="text/html;charset=utf-8" />
-
JAVA中正则表达式匹配,替换,查找,切割的方法
正则表达式的查找;主要是用到String类中的split(); String str; str.split();方法中传入按照什么规则截取,返回一个String数组 常见的截取规则: str.split("\\.")按照.来截取 str.split(" ")按照空格截取 str.split("cc+")按照c字符来截取,2个c或以上 str.split((1)\\.+)按照字符串中含有2个字符或以上的地方截取(1)表示分组为1 截取的例子; 按照
-

JS使用正则表达式实现关键字替换加粗功能示例
本文实例讲述了JS使用正则表达式实现关键字替换加粗功能的方法.分享给大家供大家参考,具体如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml">
-
正则表达式匹配,替换,查找
上篇文章给大家介绍了Java正则表达式匹配,替换,查找,切割的方法,接下来,通过本篇文章给大家介绍js 正则匹配.查找与替换,具体内容请看下文. js 正则匹配.查找与替换 RegExp对象RegExp对象表示正则表达式,它是对字符串执行模式匹配的强大工具.直接量语法/pattern/attributes创建RegExp对象的语法:newRegExp(pattern,attributes);参数参数patter... RegExp 对象 RegExp 对象表示正则表达式,它是对字符串执行模式匹配
-
C#正则表达式匹配与替换字符串功能示例
本文实例讲述了C#正则表达式匹配与替换字符串功能.分享给大家供大家参考,具体如下: 事例一:\w+=>[A-Za-z1-9_],\s+=>任何空白字符,()=>捕获 string text = @"public string testMatchObj string s string match "; string pat = @"(\w+)\s+(string)"; // Compile the regular expression. Regex
-
Java基于正则表达式实现的替换匹配文本功能【经典实例】
本文实例讲述了Java基于正则表达式实现的替换匹配文本功能.分享给大家供大家参考,具体如下: package replaceDemo; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * Created by Frank * 替换匹配的文本 */ public class ReplaceDemo { public static void main(String[] args) { // 创建一个正则表达式模式
-
php preg_filter执行一个正则表达式搜索和替换
preg_filter (PHP 5 >= 5.3.0) preg_filter - 执行一个正则表达式搜索和替换 mixed preg_filter ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] ) preg_filter()等价于preg_replace() 除了它仅仅返回(可能经过转化)与目标匹配的结果. 这个函数怎样工作的更详细信息请阅读 preg
-
Python使用正则表达式过滤或替换HTML标签的方法详解
本文实例讲述了Python使用正则表达式过滤或替换HTML标签的方法.分享给大家供大家参考,具体如下: python正则表达式关键内容: python正则表达式转义符: . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \s 匹配任意的空白符 \d 匹配数字 \b 匹配单词的开始或结束 ^ 匹配字符串的开始 $ 匹配字符串的结束 \W 匹配任意不是字母,数字,下划线,汉字的字符 \S 匹配任意不是空白符的字符 \D 匹配任意非数字的字符 \B 匹配不是单词开头或结束的位置 [^
-
Python 实用技巧之正则表达式查找和替换文本的操作方法
1.需求 我们想对字符串中的文本做查找和替换. 2.解决方案 对于简单的文本模式,使用str.replace()即可. 例如: text='mark ,帅哥,18,183 帅,mark' print(text.replace('18','19')) print(text) 运行结果: mark ,帅哥,19,193 帅,mark mark ,帅哥,18,183 帅,mark 针对更为复杂的模式,可以使用re模块中的sub()函数. 实例:将日期格式从"11/28/2018"改为&quo