Java多线程优化方法及使用方式
一、多线程介绍
在编程中,我们不可逃避的会遇到多线程的编程问题,因为在大多数的业务系统中需要并发处理,如果是在并发的场景中,多线程就非常重要了。另外,我们在面试的时候,面试官通常也会问到我们关于多线程的问题,如:如何创建一个线程?我们通常会这么回答,主要有两种方法,第一种:继承Thread类,重写run方法;第二种:实现Runnable接口,重写run方法。那么面试官一定会问这两种方法各自的优缺点在哪,不管怎么样,我们会得出一个结论,那就是使用方式二,因为面向对象提倡少继承,尽量多用组合。
这个时候,我们还可能想到,如果想得到多线程的返回值怎么办呢?根据我们多学到的知识,我们会想到实现Callable接口,重写call方法。那么多线程到底在实际项目中怎么使用呢,他有多少种方式呢?
首先,我们来看一个例子:

这是一种创建多线程的简单方法,很容易理解,在例子中,根据不同的业务场景,我们可以在Thread()里边传入不同的参数实现不同的业务逻辑,但是,这个方法创建多线程暴漏出来的问题就是反复创建线程,而且创建线程后还得销毁,如果对并发场景要求低的情况下,这种方式貌似也可以,但是高并发的场景中,这种方式就不行了,因为创建线程销毁线程是非常耗资源的。所以根据经验,正确的做法是我们使用线程池技术,JDK提供了多种线程池类型供我们选择,具体方式可以查阅jdk的文档。

这里代码我们需要注意的是,传入的参数代表我们配置的线程数,是不是越多越好呢?肯定不是。因为我们在配置线程数的时候要充分考虑服务器的性能,线程配置的多,服务器的性能未必就优。通常,机器完成的计算是由线程数决定的,当线程数到达峰值,就无法在进行计算了。如果是耗CPU的业务逻辑(计算较多),线程数和核数一样就到达峰值了,如果是耗I/O的业务逻辑(操作数据库,文件上传、下载等),线程数越多一定意义上有助于提升性能。
线程数大小的设定又一个公式决定:
Y=N*((a+b)/a),其中,N:CPU核数,a:线程执行时程序的计算时间,b:线程执行时,程序的阻塞时间。有了这个公式后,线程池的线程数配置就会有约束了,我们可以根据机器的实际情况灵活配置。
二、多线程优化及性能比较
最近的项目中用到了所线程技术,在使用过程中遇到了很多的麻烦,趁着热度,整理一下几种多线程框架的性能比较。目前所掌握的大致分三种,第一种:ThreadPool(线程池)+CountDownLatch(程序计数器),第二种:Fork/Join框架,第三种JDK8并行流,下面对这几种方式的多线程处理性能做一下比较总结。
首先,假设一种业务场景,在内存中生成多个文件对象,这里暂定30000,(Thread.sleep(时间))线程睡眠模拟业务处理业务逻辑,来比较这几种方式的多线程处理性能。
1) 单线程
这种方式非常简单,但是程序在处理的过程中非常的耗时,使用的时间会很长,因为每个线程都在等待当前线程执行完才会执行,和多线程没有多少关系,所以效率非常低。
首先创建文件对象,代码如下:
public class FileInfo {
private String fileName;//文件名
private String fileType;//文件类型
private String fileSize;//文件大小
private String fileMD5;//MD5码
private String fileVersionNO;//文件版本号
public FileInfo() {
super();
}
public FileInfo(String fileName, String fileType, String fileSize, String fileMD5, String fileVersionNO) {
super();
this.fileName = fileName;
this.fileType = fileType;
this.fileSize = fileSize;
this.fileMD5 = fileMD5;
this.fileVersionNO = fileVersionNO;
}
public String getFileName() {
return fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public String getFileType() {
return fileType;
}
public void setFileType(String fileType) {
this.fileType = fileType;
}
public String getFileSize() {
return fileSize;
}
public void setFileSize(String fileSize) {
this.fileSize = fileSize;
}
public String getFileMD5() {
return fileMD5;
}
public void setFileMD5(String fileMD5) {
this.fileMD5 = fileMD5;
}
public String getFileVersionNO() {
return fileVersionNO;
}
public void setFileVersionNO(String fileVersionNO) {
this.fileVersionNO = fileVersionNO;
}
接着,模拟业务处理,创建30000个文件对象,线程睡眠1ms,之前设置的1000ms,发现时间很长,整个Eclipse卡掉了,所以将时间改为了1ms。
public class Test {
private static List<FileInfo> fileList= new ArrayList<FileInfo>();
public static void main(String[] args) throws InterruptedException {
createFileInfo();
long startTime=System.currentTimeMillis();
for(FileInfo fi:fileList){
Thread.sleep(1);
}
long endTime=System.currentTimeMillis();
System.out.println("单线程耗时:"+(endTime-startTime)+"ms");
}
private static void createFileInfo(){
for(int i=0;i<30000;i++){
fileList.add(new FileInfo("身份证正面照","jpg","101522","md5"+i,"1"));
}
}
}
测试结果如下:

可以看到,生成30000个文件对象消耗的时间比较长,接近1分钟,效率比较低。
2) ThreadPool (线程池) +CountDownLatch (程序计数器)
顾名思义,CountDownLatch为线程计数器,他的执行过程如下:首先,在主线程中调用await()方法,主线程阻塞,然后,将程序计数器作为参数传递给线程对象,最后,每个线程执行完任务后,调用countDown()方法表示完成任务。countDown()被执行多次后,主线程的await()会失效。实现过程如下:
public class Test2 {
private static ExecutorService executor=Executors.newFixedThreadPool(100);
private static CountDownLatch countDownLatch=new CountDownLatch(100);
private static List<FileInfo> fileList= new ArrayList<FileInfo>();
private static List<List<FileInfo>> list=new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
createFileInfo();
addList();
long startTime=System.currentTimeMillis();
int i=0;
for(List<FileInfo> fi:list){
executor.submit(new FileRunnable(countDownLatch,fi,i));
i++;
}
countDownLatch.await();
long endTime=System.currentTimeMillis();
executor.shutdown();
System.out.println(i+"个线程耗时:"+(endTime-startTime)+"ms");
}
private static void createFileInfo(){
for(int i=0;i<30000;i++){
fileList.add(new FileInfo("身份证正面照","jpg","101522","md5"+i,"1"));
}
}
private static void addList(){
for(int i=0;i<100;i++){
list.add(fileList);
}
}
}
FileRunnable类:
/**
* 多线程处理
* @author wangsj
*
* @param <T>
*/
public class FileRunnable<T> implements Runnable {
private CountDownLatch countDownLatch;
private List<T> list;
private int i;
public FileRunnable(CountDownLatch countDownLatch, List<T> list, int i) {
super();
this.countDownLatch = countDownLatch;
this.list = list;
this.i = i;
}
@Override
public void run() {
for(T t:list){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
}
}
}
测试结果如下:

3) Fork/Join 框架
Jdk从版本7开始,出现了Fork/join框架,从字面来理解,fork就是拆分,join就是合并,所以,该框架的思想就是。通过fork拆分任务,然后join来合并拆分后各个人物执行完毕后的结果并汇总。比如,我们要计算连续相加的几个数,2+4+5+7=?,我们利用Fork/join框架来怎么完成呢,思想就是拆分子任务,我们可以把这个运算拆分为两个子任务,一个计算2+4,另一个计算5+7,这是Fork的过程,计算完成后,把这两个子任务计算的结果汇总,得到总和,这是join的过程。
Fork/Join框架执行思想:首先,分割任务,使用fork类将大任务分割为若干子任务,这个分割过程需要按照实际情况来定,直到分割出的任务足够小。然后,join类执行任务,分割的子任务在不同的队列里,几个线程分别从队列里获取任务并执行,执行完的结果放到一个单独的队列里,最后,启动线程,队列里拿取结果并合并结果。
使用Fork/Join框架要用到几个类,关于类的使用方式可以参考JDK的API,使用该框架,首先需要继承ForkJoinTask类,通常,只需要继承他的子类RecursiveTask或RecursiveAction即可,RecursiveTask,用于有返回结果的场景,RecursiveAction用于没有返回结果的场景。ForkJoinTask的执行需要用到ForkJoinPool来执行,该类用于维护分割出的子任务添加到不同的任务队列。
下面是实现代码:
public class Test3 {
private static List<FileInfo> fileList= new ArrayList<FileInfo>();
// private static ForkJoinPool forkJoinPool=new ForkJoinPool(100);
// private static Job<FileInfo> job=new Job<>(fileList.size()/100, fileList);
public static void main(String[] args) {
createFileInfo();
long startTime=System.currentTimeMillis();
ForkJoinPool forkJoinPool=new ForkJoinPool(100);
//分割任务
Job<FileInfo> job=new Job<>(fileList.size()/100, fileList);
//提交任务返回结果
ForkJoinTask<Integer> fjtResult=forkJoinPool.submit(job);
//阻塞
while(!job.isDone()){
System.out.println("任务完成!");
}
long endTime=System.currentTimeMillis();
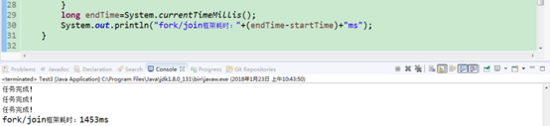
System.out.println("fork/join框架耗时:"+(endTime-startTime)+"ms");
}
private static void createFileInfo(){
for(int i=0;i<30000;i++){
fileList.add(new FileInfo("身份证正面照","jpg","101522","md5"+i,"1"));
}
}
}
/**
* 执行任务类
* @author wangsj
*
*/
public class Job<T> extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
private int count;
private List<T> jobList;
public Job(int count, List<T> jobList) {
super();
this.count = count;
this.jobList = jobList;
}
/**
* 执行任务,类似于实现Runnable接口的run方法
*/
@Override
protected Integer compute() {
//拆分任务
if(jobList.size()<=count){
executeJob();
return jobList.size();
}else{
//继续创建任务,直到能够分解执行
List<RecursiveTask<Long>> fork = new LinkedList<RecursiveTask<Long>>();
//拆分子任务,这里采用二分法
int countJob=jobList.size()/2;
List<T> leftList=jobList.subList(0, countJob);
List<T> rightList=jobList.subList(countJob, jobList.size());
//分配任务
Job leftJob=new Job<>(count,leftList);
Job rightJob=new Job<>(count,rightList);
//执行任务
leftJob.fork();
rightJob.fork();
return Integer.parseInt(leftJob.join().toString())
+Integer.parseInt(rightJob.join().toString());
}
}
/**
* 执行任务方法
*/
private void executeJob() {
for(T job:jobList){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
测试结果如下:
4) JDK8 并行流
并行流是jdk8的新特性之一,思想就是将一个顺序执行的流变为一个并发的流,通过调用parallel()方法来实现。并行流将一个流分成多个数据块,用不同的线程来处理不同的数据块的流,最后合并每个块数据流的处理结果,类似于Fork/Join框架。
并行流默认使用的是公共线程池ForkJoinPool,他的线程数是使用的默认值,根据机器的核数,我们可以适当调整线程数的大小。线程数的调整通过以下方式来实现。
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "100");
以下是代码的实现过程,非常简单:
public class Test4 {
private static List<FileInfo> fileList= new ArrayList<FileInfo>();
public static void main(String[] args) {
// System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "100");
createFileInfo();
long startTime=System.currentTimeMillis();
fileList.parallelStream().forEach(e ->{
try {
Thread.sleep(1);
} catch (InterruptedException f) {
f.printStackTrace();
}
});
long endTime=System.currentTimeMillis();
System.out.println("jdk8并行流耗时:"+(endTime-startTime)+"ms");
}
private static void createFileInfo(){
for(int i=0;i<30000;i++){
fileList.add(new FileInfo("身份证正面照","jpg","101522","md5"+i,"1"));
}
}
}
下面是测试,第一次没有设置线程池的数量,采用默认,测试结果如下:

我们看到,结果并不是很理想,耗时较长,接下来设置线程池的数量大小,即添加如下代码:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "100");
接着进行测试,结果如下:

这次耗时较小,比较理想。
三、总结
综上几种情况来看,以单线程作为参考,耗时最长的还是原生的Fork/Join框架,这里边尽管配置了线程池的数量,但效果较精确配置了线程池数量的JDK8并行流较差。并行流实现代码简单易懂,不需要我们写多余的for循环,一个parallelStream方法全部搞定,代码量大大的减少了,其实,并行流的底层还是使用的Fork/Join框架,这就要求我们在开发的过程中灵活使用各种技术,分清各种技术的优缺点,从而能够更好的为我们服务。
相关推荐
-

Java虚拟机JVM优化实战的过程全记录
前言 Java虚拟机是运行所有Java程序的抽象计算机,是Java语言的运行环境,它是Java 最具吸引力的特性之一.Java虚拟机是通过在实际的计算机上仿真模拟各种计算机功能模拟来实现的,通过Java虚拟机,您只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的任何Java代码能够在该系统上运行. 最近在看JVM群里有人发了一个GC情况,让人帮忙看优化的,于是我也凑热闹发了出来想让群里的大神们指导优化一下,以下是优化过程记录. 一开始我贴了下面的两张图 jstat看GC记录
-
29个要点帮你完成java代码优化
通过java代码规范来优化程序,优化内存使用情况,防止内存泄露 可供程序利用的资源(内存.CPU时间.网络带宽等)是有限的,优化的目的就是让程序用尽可能少的资源完成预定的任务.优化通常包含两方面的内容:减小代码的体积,提高代码的运行效率.本文讨论的主要是如何提高代码的效率. 在Java程序中,性能问题的大部分原因并不在于Java语言,而是在于程序本身.养成好的代码编写习惯非常重要,比如正确地.巧妙地运用java.lang.String类和java.util.Vector类,它能够显著地提高程序的
-
Java编程实现快速排序及优化代码详解
普通快速排序 找一个基准值base,然后一趟排序后让base左边的数都小于base,base右边的数都大于等于base.再分为两个子数组的排序.如此递归下去. public class QuickSort { public static <T extends Comparable<? super T>> void sort(T[] arr) { sort(arr, 0, arr.length - 1); } public static <T extends Comparabl
-
44条Java代码优化建议
前言 2016年3月修改,结合自己的工作和平时学习的体验重新谈一下为什么要进行代码优化.在修改之前,我的说法是这样的: 就像鲸鱼吃虾米一样,也许吃一个两个虾米对于鲸鱼来说作用不大,但是吃的虾米多了,鲸鱼自然饱了.代码优化一样,也许一个两个的优化,对于提升代码的运行效率意义不大,但是只要处处都能注意代码优化,总体来说对于提升代码的运行效率就很有用了. 这个观点,在现在看来,是要进行代码优化的一个原因,但不全对.在机械工艺发展的今天,服务器动辄8核.16核,64位CPU,代码执行效率非常高,Stri
-
JAVA下单接口优化实战TPS性能提高10倍
概述 最近公司的下单接口有些慢,老板担心无法支撑双11,想让我优化一把,但是前提是不允许大改,因为下单接口太复杂了,如果改动太大,怕有风险.另外开发成本和测试成本也非常大.对于这种有挑战性的任务,我向来是非常喜欢的,因为在解决问题的过程中,可以学习到很多东西. 当时我只是知道下单接口慢,但是没人告诉我慢在哪里,也即是说,哪些瓶颈导致下单接口慢了.其实没人知道也没关系的,因为我们可以通过压测来找到具体的瓶颈. 下面会详细介绍一下,在本次压测中遇到的问题以及如何解决,期间用了什么工具. 用到的工具和
-
Java性能优化之数据结构实例代码
-举例(学生排课)- 正常思路的处理方法和优化过后的处理方法: 比如说给学生排课.学生和课程是一个多对多的关系. 按照正常的逻辑 应该有一个关联表来维护 两者之间的关系. 现在,添加一个约束条件用于校验.如:张三上学期学过的课程,在排课的时候不应该再排这种课程. 所以需要出现一个约束表(即:历史成绩表). 即:学生选课表,需要学生成绩表作为约束. -方案一:正常处理方式- 当一个学生进行再次选课的时候.需要查询学生选课表看是否已经存在. 即有如下校验: //查询 学生code和课程code分别为
-
java代码效率优化方法(推荐)
1. 尽量指定类的final修饰符 带有final修饰符的类是不可派生的. 如果指定一个类为final,则该类所有的方法都是final.Java编译器会寻找机会内联(inline)所有的 final方法(这和具体的编译器实现有关).此举能够使性能平均提高50% . 2. 尽量重用对象. 特别是String 对象的使用中,出现字符串连接情况时应用StringBuffer 代替.由于系统不仅要花时间生成对象,以后可能还需花时间对这些对象进行垃圾回收和处理.因此,生成过多的对象将会给程序的性能带来很大
-
优化Java虚拟机总结(jvm调优)
堆设置 -Xmx3550m:设置JVM最大堆内存为3550M. -Xms3550m:设置JVM初始堆内存为3550M.此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存. -Xss128k:设置每个线程的栈大小.JDK5.0以后每个线程栈大小为1M,之前每个线程栈大小为256K.应当根据应用的线程所需内存大小进行调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右. -Xmn2g:设置堆
-
Java代码优化细节
代码优化细节 1.尽量指定类.方法的final修饰符 带有final修饰符的类是不可派生的.在Java核心API中,有许多应用final的例子,例如java.lang.String,整个类都是final的.为类指定final修饰符可以让类不可以被继承,为方法指定final修饰符可以让方法不可以被重写.如果指定了一个类为final,则该类所有的方法都是final的.Java编译器会寻找机会内联所有的final方法,内联对于提升Java运行效率作用重大 2.尽量重用对象 特别是String对象的
-
详解Java代码常见优化方案
首先,良好的编码规范非常重要.在 java 程序中,访问速度.资源紧张等问题的大部分原因,都是代码不规范造成的. 单例的使用场景 单例模式对于减少资源占用.提高访问速度等方面有很多好处,但并不是所有场景都适用于单例. 简单来说,单例主要适用于以下三个方面: 多线程场景,通过线程同步来控制资源的并发访问. 多线程场景,控制数据共享,让多个不相关的进程或线程之间实现通信(通过访问同一资源来控制). 控制实例的产生,单例只实例化一次,以达到节约资源的目的: 不可随意使用静态变量 当某个对象被定义为 s