解决MySQL中IN子查询会导致无法使用索引问题
今天看到一篇关于MySQL的IN子查询优化的案例,
一开始感觉有点半信半疑(如果是换做在SQL Server中,这种情况是绝对不可能的,后面会做一个简单的测试。)
随后动手按照他说的做了一个表来测试验证,发现MySQL的IN子查询做的不好,确实会导致无法使用索引的情况(IN子查询无法使用所以,场景是MySQL,截止的版本是5.7.18)
MySQL的测试环境

测试表如下
create table test_table2 ( id int auto_increment primary key, pay_id int, pay_time datetime, other_col varchar(100) )
建一个存储过程插入测试数据,测试数据的特点是pay_id可重复,这里在存储过程处理成,循环插入300W条数据的过程中,每隔100条数据插入一条重复的pay_id,时间字段在一定范围内随机
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT)
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''
BEGIN
declare cnt int;
set cnt = 0;
while cnt< loopcount do
insert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());
if (cnt mod 100 = 0) then
insert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());
end if;
set cnt = cnt + 1;
end while;
END
执行 call test_insert(3000000); 插入303000行数据

两种子查询的写法
查询大概的意思是查询某个时间段之内的业务Id大于1的数据,于是就出现两种写法。
第一种写法如下:IN子查询中是某段时间内业务统计大于1的业务Id,外层按照IN子查询的结果进行查询,业务Id的列pay_id上有索引,逻辑也比较简单,这种写法,在数据量大的时候确实效率比较低,用不到索引
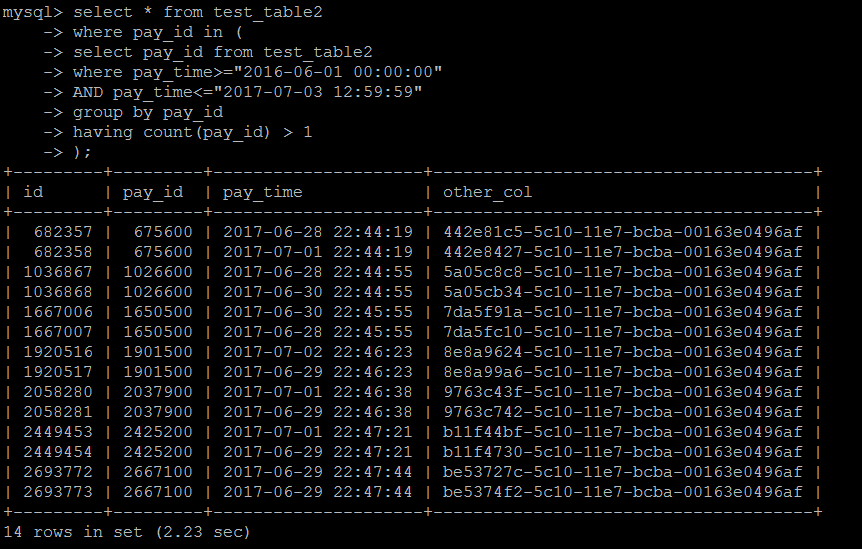
select * from test_table2 force index(idx_pay_id) where pay_id in ( select pay_id from test_table2 where pay_time>="2016-06-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1 );
执行结果:2.23秒
第二种写法,与子查询进行join关联,这种写法相当于上面的IN子查询写法,下面测试发现,效率确实有不少的提高
select tpp1.* from test_table2 tpp1, ( select pay_id from test_table2 WHERE pay_time>="2016-07-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1 ) tpp2 where tpp1.pay_id=tpp2.pay_id
执行结果:0.48秒

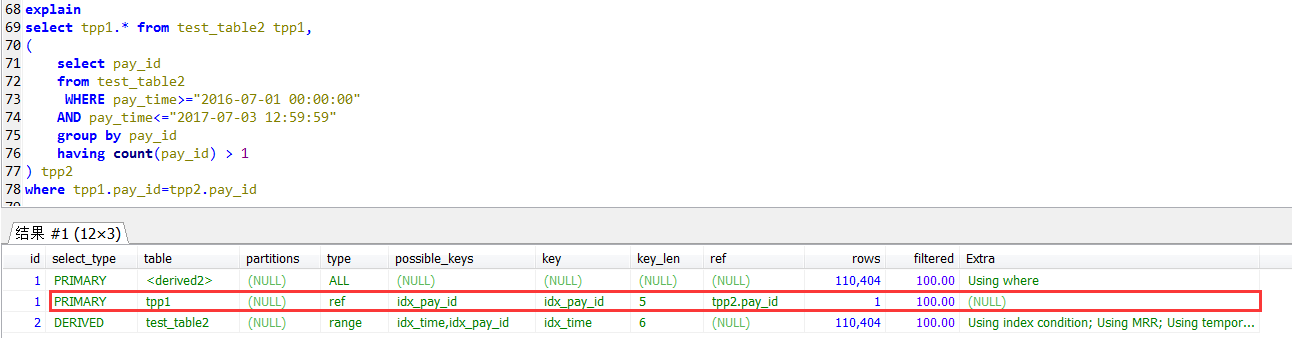
In子查询的执行计划,发现外层查询是一个全表扫描的方式,没有用到pay_id上的索引

join自查的执行计划,外层(tpp1别名的查询)是用到pay_id上的索引的。
后面想对第一种查询方式使用强制索引,虽然是不报错的,但是发现根本没用

如果子查询是直接的值,则是可以正常使用索引的。

可见MySQL对IN子查询的支持,做的确实不怎么样。
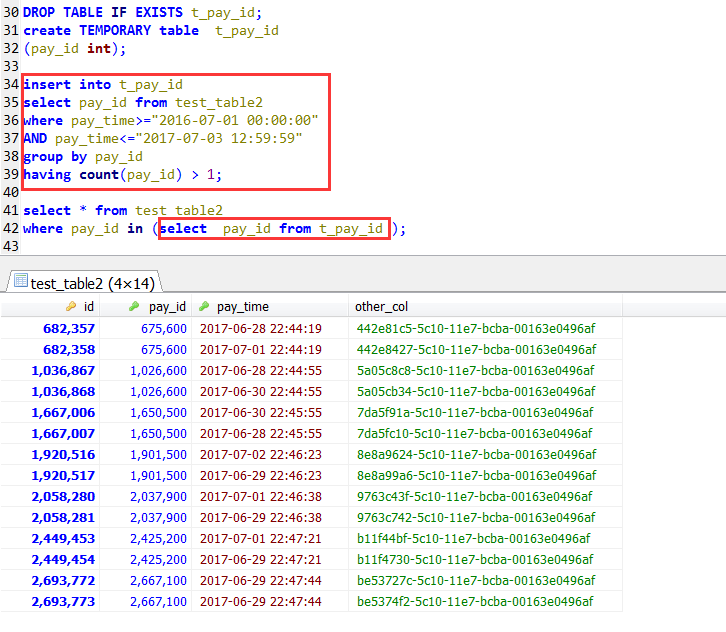
另外:加一个使用临时表的情况,虽然比不少join方式查询的,但是也比直接使用IN子查询效率要高,这种情况下,也是可以使用到索引的,不过这种简单的情况,是没有必要使用临时表的。
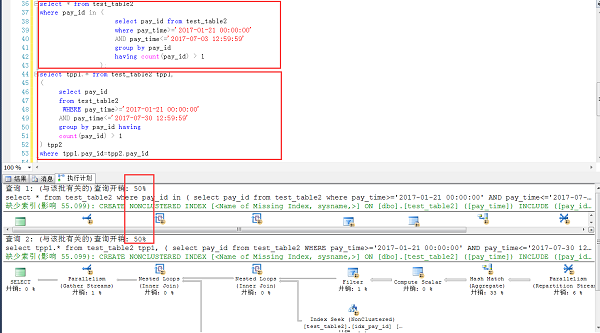
下面是类似案例在sqlserver 2014中的测试,几万完全一样的测试表结构和数量,可见这种情况下,两种写法,在SQL Server中可以认为是完全一样的(执行计划+效率),这一点SQL Server要比MySQL强不少
下面是sqlserver中的测试环境脚本。
create table test_table2
(
id int identity(1,1) primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
)
begin tran
declare @i int = 0
while @i<300000
begin
insert into test_table2 values (@i,getdate()-rand()*300,newid());
if(@i%1000=0)
begin
insert into test_table2 values (@i,getdate()-rand()*300,newid());
end
set @i = @i + 1
end
COMMIT
GO
create index idx_pay_id on test_table2(pay_id);
create index idx_time on test_table2(pay_time);
GO
select * from test_table2
where pay_id in (
select pay_id from test_table2
where pay_time>='2017-01-21 00:00:00'
AND pay_time<='2017-07-03 12:59:59'
group by pay_id
having count(pay_id) > 1
);
select tpp1.* from test_table2 tpp1,
(
select pay_id
from test_table2
WHERE pay_time>='2017-01-21 00:00:00'
AND pay_time<='2017-07-30 12:59:59'
group by pay_id having
count(pay_id) > 1
) tpp2
where tpp1.pay_id=tpp2.pay_id
总结:在MySQL数据中,截止5.7.18版本,对IN子查询,仍要慎用
相关推荐
-
Linux下刚安装完mysql修改密码的简单方法
在Centos中安装MySQL后默认的是没有root密码的,默认的是回车, 那么为了方便需要修改密码. 没有密码为MYSQL加密码: mysql -uroot -p 回车 提示输入密码,为空回车 update mysql.user set password=PASSWORD('12345678') where user='root'; 刷新权限表,输入如下命令 flush privileges; 退出 quit 以上所述是小编给大家介绍的Linux下刚安装完mysql修改密码的简单方法,希望对大
-
CentOS 6.6 源码编译安装MySQL 5.7.18教程详解
一.添加用户和组 1.添加mysql用户组 # groupadd mysql 2.添加mysql用户 # useradd -g mysql -s /bin/nologin mysql -M 二.查看系统中是否安装mysql,如果安装需要卸载 # rpm -qa | grep mysql mysql-libs-5.1.73-3.el6_5.x86_64 # rpm -e mysql-libs-5.1.73-3.el6_5.x86_64 --nodeps 三.安装所需依赖包 # yum -y ins
-
MySQL交换分区的实例详解
MySQL交换分区的实例详解 前言 在介绍交换分区之前,我们先了解一下 mysql 分区. 数据库的分区有两种:水平分区和垂直分区.而MySQL暂时不支持垂直分区,因此接下来说的都是水平分区.水平分区即:以行为单位对表进行分区.比如:按照时间分区,每一年一个分区等. 在MySQL中,分区是可以交换的,可以将一个分区表中的一个分区和一个普通表中的数据互换. 交换分区的实现 1.交换分区的语法 alter table pt exchange partition p with table nt; 解释
-
CentOS 7中MySQL连接数被限制为214个的解决方法
发现问题 最近在项目中遇到一个问题,由于连接数过多,提示 "Too many connections" ,需要增加连接数. 我在 /etc/my.cnf中修改了: max_connections = 2000 但是, 实际连接数一直被限制在 214: mysql> show variables like "max_connections"; +-----------------+-------+ | Variable_name | Value | +-----
-
通过案例分析MySQL中令人头疼的Aborted告警
本文主要给大家介绍的是关于MySQL中Aborted告警的相关内容,分享出来供大家参考学习,下面来一起看看详细的介绍: 实战 Part1:写在最前 在MySQL的error log中,我们会经常性看到一些各类的Aborted connection错误,本文中会针对这类错误进行一个初步分析,并了解一个问题产生后的基本排查思路和方法.掌握这种方法是至关重要的,而不是出现问题了,去猜,去试.数据库出现问题的时候需要DBA在短时间内快速解决问题,因此一个好与坏的DBA,区别也在于此. Part2:种类
-
MySql Error 1698(28000)问题的解决方法
一,问题描述: MysqlERROR1698(28000)解决,新装了mysql-server-5.7,登录为这一问题,普通用户不能进mysql,只有root用户才能进,并且不需要任何密码. ~$ mysql -u root -p Enter password: ERROR 1698 (28000): Access denied for user 'root'@'localhost' 二,解决步骤: 停止mysql服务 ~$ sudo service mysql stop 以安全模式启动MySQ
-

解决MySQL中IN子查询会导致无法使用索引问题
今天看到一篇关于MySQL的IN子查询优化的案例, 一开始感觉有点半信半疑(如果是换做在SQL Server中,这种情况是绝对不可能的,后面会做一个简单的测试.) 随后动手按照他说的做了一个表来测试验证,发现MySQL的IN子查询做的不好,确实会导致无法使用索引的情况(IN子查询无法使用所以,场景是MySQL,截止的版本是5.7.18) MySQL的测试环境 测试表如下 create table test_table2 ( id int auto_increment primary key, p
-
详细讲述MySQL中的子查询操作
继续做以下的前期准备工作: 新建一个测试数据库TestDB: create database TestDB; 创建测试表table1和table2: CREATE TABLE table1 ( customer_id VARCHAR(10) NOT NULL, city VARCHAR(10) NOT NULL, PRIMARY KEY(customer_id) )ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2 ( order_id
-
解决Mysql多行子查询的使用及空值问题
目录 1 定义 2 多行比较操作符 3 空值问题 3.1 问题 3.2 解决 1 定义 也称为集合比较子查询 内查询返回多行 使用多行比较操作符 2 多行比较操作符 -- 多行子查询 -- IN SELECT employee_id, manager_id, department_id FROM employees WHERE manager_id IN ( -- 在返回集合中查找有没有相同的manager_id在里面 SELECT manager_id FROM employees WHERE
-
在MySQL中使用子查询和标量子查询的基本操作教程
MySQL 子查询 子查询是将一个 SELECT 语句的查询结果作为中间结果,供另一个 SQL 语句调用.MySQL 支持 SQL 标准要求的所有子查询格式和操作,也扩展了特有的几种特性. 子查询没有固定的语法,一个子查询的例子如下: SELECT * FROM article WHERE uid IN(SELECT uid FROM user WHERE status=1) 对应的两个数据表如下: article 文章表: user 用户表: 查询返回结果如下所示: 在该例子中,首先通过子查询
-
MySql数据库中的子查询与高级应用浅析
MySql数据库中的子查询: 子查询:在一条select查询语句中嵌套另一条select语句,其主要作用是充当查询条件或确定数据源. 代码案例如下: 例1. 查询大于平均年龄的学生: select * from students where age > (select avg(age) from students); 例2. 查询学生在班的所有班级名字: select name from classes where id in (select cls_id from students where
-
深入了解MySQL中的慢查询
目录 一.什么是慢查询 二.慢查询的危害 三.慢查询常见场景 总结 一.什么是慢查询 什么是MySQL慢查询呢?其实就是查询的SQL语句耗费较长的时间. 具体耗费多久算慢查询呢?这其实因人而异,有些公司慢查询的阈值是100ms,有些的阈值可能是500ms,即查询的时间超过这个阈值即视为慢查询. 正常情况下,MySQL是不会自动开启慢查询的,且如果开启的话默认阈值是10秒 # slow_query_log 表示是否开启 mysql> show global variables like '%slo
-
MySQL里面的子查询的基本使用
目录 一.子查询定义 二.子查询分类 1. 标量子查询: 2. MySQL 列子查询: 3. MySQL 行子查询: 4. MySQL 表子查询: 三.字查询例举 1. ANY进行子查询 2. 使用IN进行子查询 3. 使用SOME进行子查询 4. 使用ALL进行子查询 5.标量子查询 6. 多值子查询 7. 独立子查询 8.相关子查询 9.EXISTS谓词 10. 派生表 四.子查询优化 一.子查询定义 定义: 子查询允许把一个查询嵌套在另一个查询当中. 子查询,又叫内部查询,相对于内部查询,
-
mysql中like % %模糊查询的实现
1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] WHERE u_name LIKE '%三%' 将会把u_name为"张三","张猫三"."三脚猫","唐三藏"等等有"三"的记录全找出来. 另外,如果需要找出u_name中既有"三"又有"猫"的记录,请使用a
-
MySQL实例讲解子查询的使用
目录 子查询-嵌套查询 原始查询方法 自连接 子查询 子查询分类 单行子查询 子查询的编写思路 HAVING中的子查询 CASE中的子查询 子查询中的空值问题 多行子查询 多行比较操作符 相关子查询 EXISTS与NOT EXISTS 关键字 子查询-嵌套查询 子查询是指一个查询语句嵌套在另一个语句内部的查询 原始查询方法 SELECT last_name,salaryFROM employeesWHERE last_name='Abel';SELECT last_name,salaryFROM
-
MySql中使用正则表达式查询的方法
正则表达式常用来检索和替换那些符合魔种模式的文本.例如从一个文本文件中提取电话号码,查找一篇文章中重复的单词或者替换用户输入的某些敏感词汇等.Mysql 使用 REGEXP 关键字指定正则表达式的字符匹配模式. 1. 字符 '^' 查询以特定字符或字符串开头的记录 SELECT * FROM user WHERE email REGEXP '^a' 字符 '^' 匹配以特定字符或字符串开头的记录,以上语句查询邮箱以 a 开头的记录 2. 字符 ' 查询以特定字符或字符串结尾的记录 SELECT