如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求
网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的UserAgent。
所以通过UserAgent判断请求的发起者是否是搜索引擎爬虫(蜘蛛)的方式是不靠谱的,更靠谱的方法是通过请求者的ip对应的host主机名是否是搜索引擎自己家的host的方式来判断。
要获得ip的host,在windows下可以通过nslookup命令,在linux下可以通过host命令来获得,例如:
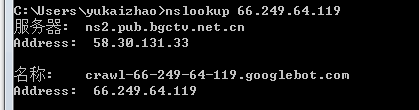
这里我在windows下执行了nslookup ip 的命令,从上图可以看到这个ip的主机名是crawl-66-249-64-119.googlebot.com。 这说明这个ip是一个google爬虫,google爬虫的域名都是 xxx.googlebot.com.
我们也可以通过python程序的方式来获得ip的host信息,代码如下:
import socket def getHost(ip): try: result=socket.gethostbyaddr(ip) if result: return result[0], None except socket.herror,e: return None, e.message
上述代码使用了socket模块的gethostbyaddr的方法获得ip地址的主机名。
常用蜘蛛的域名都和搜索引擎官网的域名相关,例如:
百度的蜘蛛通常是baidu.com或者baidu.jp的子域名
google爬虫通常是googlebot.com的子域名
微软bing搜索引擎爬虫是search.msn.com的子域名
搜狗蜘蛛是crawl.sogou.com的子域名
基于以上原理,我写了一个工具页面提供判断ip是否是真实搜索引擎的工具页面,该页面上提供了网页判断的工具和常见的google和bing的搜索引擎爬虫的ip地址。
附带常见搜索引擎蜘蛛的IP段:
| 蜘蛛名称 | IP地址 |
|---|---|
| Baiduspider |
202.108.11.* 220.181.32.* 58.51.95.* 60.28.22.* 61.135.162.* 61.135.163.* 61.135.168.* |
| YodaoBot |
202.108.7.215 202.108.7.220 202.108.7.221 |
| Sogou web spider |
219.234.81.* 220.181.61.* |
| Googlebot |
203.208.60.* |
| Yahoo! Slurp |
202.160.181.* 72.30.215.* 74.6.17.* 74.6.22.* |
| Yahoo ContentMatch Crawler |
119.42.226.* 119.42.230.* |
| Sogou-Test-Spider |
220.181.19.103 220.181.26.122 |
| Twiceler |
38.99.44.104 64.34.251.9 |
| Yahoo! Slurp China |
202.160.178.* |
| Sosospider | 124.115.0.* |
| CollapsarWEB qihoobot |
221.194.136.18 |
| NaverBot |
202.179.180.45 |
| Sogou Orion spider |
220.181.19.106 220.181.19.74 |
| Sogou head spider |
220.181.19.107 |
| SurveyBot |
216.145.5.42 64.246.165.160 |
| Yanga WorldSearch Bot v |
77.91.224.19 91.205.124.19 |
| baiduspider-mobile-gate |
220.181.5.34 61.135.166.31 |
| discobot |
208.96.54.70 |
| ia_archiver | 209.234.171.42 |
| msnbot |
65.55.104.209 65.55.209.86 65.55.209.96 |
| sogou in spider |
220.181.19.216 |
ps:https协议网页能够被搜索引擎收录吗
百度现在只能收录少部分的https,大部分的https网页无法收录。
不过我查询了google资料,Google能够比较好地收录https协议的网站。
所以如果你的网站是中文的,而且比较关注搜索引擎自然排名流量这块,建议尽量不要将所有内容都放到https中去加密去。
可考虑的方式是:
1、对于需要加密传递的数据,使用https,比如用户登录以及用户登录后的信息;
2、对于普通的新闻、图片,建议使用http协议来传输;
3、网站首页建议使用http协议的形式。
相关推荐
-
使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
复制代码 代码如下: #!/usr/bin/env python# -*- coding: utf-8 -*- from scrapy.contrib.spiders import CrawlSpider, Rulefrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom scrapy.selector import Selector from cnbeta.items import CnbetaItemclass
-
apache禁止搜索引擎收录、网络爬虫采集的配置方法
Apache中禁止网络爬虫,之前设置了很多次的,但总是不起作用,原来是是写错了,不能写到Dirctory中,要写到Location中 复制代码 代码如下: <Location /> SetEnvIfNoCase User-Agent "spider" bad_bot BrowserMatchNoCase bingbot bad_bot BrowserMatchNoCase Googlebot bad_bot Order Deny,Allow #下面是禁止soso的爬虫 De
-
Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为
摘要 做好网站SEO优化的第一步就是首先让蜘蛛爬虫经常来你的网站进行光顾,下面的Linux命令可以让你清楚的知道蜘蛛的爬行情况.下面我们针对nginx服务器进行分析,日志文件所在目录:/usr/local/nginx/logs/access.log,access.log这个文件记录的应该是最近一天的日志情况,首先请看看日志大小,如果很大(超过50MB)建议别用这些命令分析,因为这些命令很消耗CPU,或者更新下来放到分析机上执行,以免影响网站的速度. Linux shell命令 1. 百度蜘蛛爬行
-
php IIS日志分析搜索引擎爬虫记录程序第1/2页
使用注意: 修改iis.php文件中iis日志的绝对路径 例如:$folder="c:/windows/system32/logfiles/站点日志目录/"; //后面记得一定要带斜杠(/). ( 用虚拟空间的不懂查看你的站点绝对路径?上传个探针查看! 直接查看法:http://站点域名/iis.php 本地查看法:把日志下载到本地 http://127.0.0.1/iis.php ) 注意: //站点日志目录,注意该目录必须要有站点用户读取权限! //如果把日志下载到本地请修改143
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
在这篇文章中,我们将分析一个网络爬虫. 网络爬虫是一个扫描网络内容并记录其有用信息的工具.它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行同样的操作. 如果爬虫正在分析的网页中有一些链接,那么爬虫将会根据这些链接分析更多的页面. 搜索引擎就是基于这样的原理实现的. 这篇文章中,我特别选了一个稳定的."年轻"的开源项目pyspider,它是由 binux 编码实现的. 注:据认为pyspider持续监控网络,它假定网页在一
-
Nginx限制搜索引擎爬虫频率、禁止屏蔽网络爬虫配置示例
复制代码 代码如下: #全局配置 limit_req_zone $anti_spider zone=anti_spider:10m rate=15r/m; #某个server中 limit_req zone=anti_spider burst=30 nodelay; if ($http_user_agent ~* "xxspider|xxbot") { set $anti_spider $http_user_agent; } 超过设置的限定频率,就会给spider一个503. 上
-

如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求
网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的UserAgent. 所以通过UserAgent判断请求的发起者是否是搜索引擎爬虫(蜘蛛)的方式是不靠谱的,更靠谱的方法是通过请求者的ip对应的host主机名是否是搜索引擎自己家的host的方式来判断. 要获得ip的host,在windows下可以通过nslookup
-
PHP判断来访是搜索引擎蜘蛛还是普通用户的代码小结
1.推荐的一种方法:php判断搜索引擎蜘蛛爬虫还是人为访问代码,摘自Discuz x3.2 <?php function checkrobot($useragent=''){ static $kw_spiders = array('bot', 'crawl', 'spider' ,'slurp', 'sohu-search', 'lycos', 'robozilla'); static $kw_browsers = array('msie', 'netscape', 'opera', 'konq
-
php/asp/asp.net中判断百度移动和PC蜘蛛的实现代码
由于移动流量日趋增多,我们统计网站流量的时候,需要把移动和PC的流量分开,而遇到百度蜘蛛的时候,为了更好更细的统计,也需要把百度蜘蛛的移动端和PC端分别来统计,这对网站分析有着非常重要的意义.本文提供判断百度移动蜘蛛和百度PC蜘蛛的源代码,有php.asp.asp.net三个版本. php版 <?php $ua=$_SERVER['HTTP_USER_AGENT']; $ua=strtolower($ua); if($ua!="" && strpos($ua,&q
-
python反反爬虫技术限制连续请求时间处理
目录 前言 用勾子函数根据缓存行为设置访问时间 爬虫相关库 1. 爬虫常用的测试网站:httpbin.org 2. requests-cache 为原有代码微创式添加缓存功能 缓存的清空和识别 自定义设置缓存的形式 自定义设置缓存的例子1:设置缓存文件类型 自定义设置缓存的例子2:设置缓存保存内容 前言 一般的反爬措施是在多次请求之间增加随机的间隔时间,即设置一定的延时.但如果请求后存在缓存,就可以省略设置延迟,这样一定程度地缩短了爬虫程序的耗时. 下面利用requests_cache实现模拟浏
-
php实现不通过扩展名准确判断文件类型的方法【finfo_file方法与二进制流】
本文实例讲述了php实现不通过扩展名准确判断文件类型的方法.分享给大家供大家参考,具体如下: 第一种方法 通过php的finfo_file() $handle=finfo_open(FILEINFO_MIME_TYPE);//This function opens a magic database and returns its resource. $fileInfo=finfo_file($handle,'./test.txt');// Return information about a f
-
Pytho爬虫中Requests设置请求头Headers的方法
1.为什么要设置headers? 在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题. headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据. 对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 . 2. headers在哪里找? 谷歌或者火狐浏览器,在网页面上点击:右键–>检查–>剩余按照图中显示操作,需要按Fn+F5刷新出网页来 有的浏览器是点击
-
Python爬虫基础讲解之请求
一.请求目标(URL) URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法.类似于windows的文件路径. 二.网址的组成: 1.http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议. 2.mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail. 3.163.com:这个是域名,是用来定位网站的独一无二的名字. 4.mail.163.com:这个是网站名,由服务器名+域名组成. 5./:这个是根目录,也就是说,
-
golang爬虫colly 发送post请求
继续还是工作中使用colly,不管是官网,还是网上的一些文章(其实90%就是把官网的案例抄过去),都是一样的格式,没有讲到post,测试了几次,记录一下post的使用 c := colly.NewCollector() type data struct { Phone string `json:"phone" binding:"required"` } d:=&data{ Phone:"
-
Python爬虫实现HTTP网络请求多种实现方式
1.通过urllib.requests模块实现发送请求并读取网页内容的简单示例如下: #导入模块 import urllib.request #打开需要爬取的网页 response = urllib.request.urlopen('http://www.baidu.com') #读取网页代码 html = response.read() #打印读取的内容 print(html) 结果: b'<!DOCTYPE html><!--STATUS OK-->\n\n\n \n \n &
-
JavaScript中发出HTTP请求最常用的方法
JavaScript具有很好的模块和方法来发送可用于从服务器端资源发送或接收数据的HTTP请求.在本文中,我们将介绍一些在JavaScript中发出HTTP请求的流行方法. Ajax Ajax是发出异步HTTP请求的传统方式.可以使用HTTP POST方法发送数据,并使用HTTP GET方法接收数据.我们来看看发送GET请求.我将使用JSONPlaceholder,这是一个免费的在线REST API,适用于以JSON格式返回随机数据的开发人员. 要在Ajax中进行HTTP调用,您需要初始化一个新