SQLServer中临时表与表变量的区别分析
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢?
临时表
临时表与永久表相似,只是它的创建是在Tempdb中,它只有在一个数据库连接结束后或者由SQL命令DROP掉,才会消失,否则就会一直存在。临时表在创建的时候都会产生SQL Server的系统日志,虽它们在Tempdb中体现,是分配在内存中的,它们也支持物理的磁盘,但用户在指定的磁盘里看不到文件。
临时表分为本地和全局两种,本地临时表的名称都是以“#”为前缀,只有在本地当前的用户连接中才是可见的,当用户从实例断开连接时被删除。全局临时表的名称都是以“##”为前缀,创建后对任何用户都是可见的,当所有引用该表的用户断开连接时被删除。
下面我们来看一个创建临时表的例子:
CREATE TABLE dbo.#News ( News_id int NOT NULL, NewsTitle varchar(100), NewsContent varchar(2000), NewsDateTime datetime )
临时表可以创建索引,也可以定义统计数据,所以可以用数据定义语言(DDL)的声明来阻止临时表添加的限制,约束,并参照完整性,如主键和外键约束。比如来说,我们现在来为#News表字段NewsDateTime来添加一个默认的GetData()当前日期值,并且为News_id添加一个主键,我们就可以使用下面的语句:
ALTER TABLE dbo.#News ADD CONSTRAINT [DF_NewsDateTime] DEFAULT (GETDATE()) FOR [NewsDateTime], PRIMARY KEY CLUSTERED ( [News_id] ) ON [PRIMARY] GO
临时表在创建之后可以修改许多已定义的选项,包括:
1)添加、修改、删除列。例如,列的名称、长度、数据类型、精度、小数位数以及为空性均可进行修改,只是有一些限制而已。
2)可添加或删除主键和外键约束。
3)可添加或删除 UNIQUE 和 CHECK 约束及 DEFAULT 定义(对象)。
4)可使用 IDENTITY 或 ROWGUIDCOL 属性添加或删除标识符列。虽然 ROWGUIDCOL 属性也可添加至现有列或从现有列删除,但是任何时候在表中只能有一列可具有该属性。
5)表及表中所选定的列已注册为全文索引。
表变量
表变量创建的语法类似于临时表,区别就在于创建的时候,必须要为之命名。表变量是变量的一种,表变量也分为本地及全局的两种,本地表变量的名称都是以“@”为前缀,只有在本地当前的用户连接中才可以访问。全局的表变量的名称都是以“@@”为前缀,一般都是系统的全局变量,像我们常用到的,如 @@Error代表错误的号,@@RowCount代表影响的行数。
如我们看看创建表变量的语句:
DECLARE @News Table
(
News_id int NOT NULL,
NewsTitle varchar(100),
NewsContent varchar(2000),
NewsDateTime datetime
)
比较临时表及表变量都可以通过SQL的选择、插入、更新及删除语句,它们的的不同主要体现在以下这些:
1)表变量是存储在内存中的,当用户在访问表变量的时候,SQL Server是不产生日志的,而在临时表中是产生日志的;
2)在表变量中,是不允许有非聚集索引的;
3)表变量是不允许有DEFAULT默认值,也不允许有约束;
4)临时表上的统计信息是健全而可靠的,但是表变量上的统计信息是不可靠的;
5)临时表中是有锁的机制,而表变量中就没有锁的机制。
我们现在来看一个完整的例子,来看它们的用法的异同:
利用临时表
CREATE TABLE dbo.#News
(
News_id int NOT NULL,
NewsTitle varchar(100),
NewsContent varchar(2000),
NewsDateTime datetime
)
INSERT INTO dbo.#News (News_id, NewsTitle, NewsContent, NewsDateTime)
VALUES (1,'BlueGreen', 'Austen', 200801, GETDATE())
SELECT News_id, NewsTitle, NewsContent, NewsDateTime FROM dbo.#News
DROP TABLE dbo.[#News]
利用表变量
DECLARE @News table
(
News_id int NOT NULL,
NewsTitle varchar(100),
NewsContent varchar(2000),
NewsDateTime datetime
)
INSERT INTO @News (News_id, NewsTitle, NewsContent, NewsDateTime)
VALUES (1,'BlueGreen', 'Austen', 200801, GETDATE())
SELECT News_id, NewsTitle, NewsContent, NewsDateTime FROM @News
我们可以看到上面两种情况实现的是一样的效果,第一种利用临时表的时候,临时表一般被创建后,如果在执行的时候,没有通过DROP Table的操作,第二次就不能再被创建,而定义表变量也不需要进行DROP Table的操作,一次执行完成后就会消失。
其实在选择临时表还是表变量的时候,我们大多数情况下在使用的时候都是可以的,但一般我们需要遵循下面这个情况,选择对应的方式:
1)使用表变量主要需要考虑的就是应用程序对内存的压力,如果代码的运行实例很多,就要特别注意内存变量对内存的消耗。我们对于较小的数据或者是通过计算出来的推荐使用表变量。如果数据的结果比较大,在代码中用于临时计算,在选取的时候没有什么分组的聚合,就可以考虑使用表变量。
2)一般对于大的数据结果,或者因为统计出来的数据为了便于更好的优化,我们就推荐使用临时表,同时还可以创建索引,由于临时表是存放在Tempdb中,一般默认分配的空间很少,需要对tempdb进行调优,增大其存储的空间。
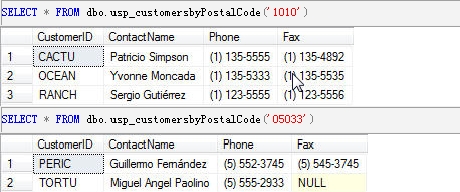
3)如果要在自定义函数中返回一个表,要用表变量如:
dbo.usp_customersbyPostalCode
( @PostalCode VARCHAR(15) )
RETURNS
@CustomerHitsTab TABLE (
[CustomerID] [nchar] (5),
[ContactName] [nvarchar] (30),
[Phone] [nvarchar] (24),
[Fax] [nvarchar] (24)
)
AS
BEGIN
DECLARE @HitCount INT
INSERT INTO @CustomerHitsTab
SELECT [CustomerID],
[ContactName],
[Phone],
[Fax]
FROM [Northwind].[dbo].[Customers]
WHERE PostalCode = @PostalCode
SELECT @HitCount = COUNT(*)
FROM @CustomerHitsTab
IF @HitCount = 0
--No Records Match Criteria
INSERT INTO @CustomerHitsTab (
[CustomerID],
[ContactName],
[Phone],
[Fax] )
VALUES ('','No Companies In Area','','')
RETURN
END
GO
相关推荐
-
sqlserver通用的删除服务器上的所有相同后缀的临时表
复制代码 代码如下: use tempdb if object_id('tempdb..#table') is not null drop table tempdb..#table select name into tempdb..#table from (select * from sysobjects where xtype='U') a where a.name like '%test_select' declare @table varchar(100),@count int selec
-
关于sqlserver 2005 使用临时表的问题( Invalid object name #temptb)
最近在利用 SSRS 2005 做报表的时候,调用带有临时表的数据源时,系统会报错,并无法进入向导的下一步,错误如下: There is an error in the query. Invalid object name '#temptb'. 经过研究后想到如下三种解决方案: 1. 使用表变量代替临时表,这样做法可以避免SSRS 2005 的语法错误提示,缺点就是如果处理的数据量比较大,会占用过大的内存,并且报表加载时间过长. 2.使用一个不包含临时表的SQL语句创建报表,创建成功以后,修改数
-
sqlserver2005利用临时表和@@RowCount提高分页查询存储过程性能示例分享
最近发现现有框架的通用查询存储过程的性能慢,于是仔细研究了下代码: 复制代码 代码如下: Alter PROCEDURE [dbo].[AreaSelect] @PageSize int=0, @CurrentPage int=1, @Identifier int=NULL, @ParentId int=NULL, @AreaLevel int=NULL, @Children int=NULL, @AreaName nvarchar(50)=NULL,
-
sqlserver 动态创建临时表的语句分享
因此计划先把数据转插入一个临时表,再对临时表的数据进行分析. 问题点是如何动态创建临时表.原先Insus.NET使用下面代码实现: 复制代码 代码如下: DECLARE @s NVARCHAR(MAX) = ' IF OBJECT_ID(''[dbo].[#Tb]'') IS NOT NULL DROP TABLE [dbo].[#Tb] CREATE TABLE [dbo].[#Tb] ( [xxx] INT, [xxx] NVARCHAR(50), '+ [dbo].[Column]() +
-
SQLServer获取临时表所有列名或是否存在指定列名的方法
获取临时表中所有列名 select name from tempdb.dbo.syscolumns where id=object_id( '#TempTB') 判断临时表中是否存在指定列名 if col_length('tempdb.dbo.#TempTB','columnName') is not null print '存在' else print '不存在' 以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
-

sqlserver 临时表 Vs 表变量 详细介绍
这里我们在SQL Server 2005\SQL Server 2008版本上通过举例子,说明临时表和表变量两者的一些特征,让我们对临时表和表变量有进一步的认识.在本章中,我们将从下面几个方面去进行描述,对其中的一些特征举例子说明: 约束(Constraint) 索引(Index) I/0开销 作用域(scope) 存儲位置 其他 例子描述 约束(Constraint) 在临时表和表变量,都可以创建Constraint.针对表变量,只有定义时能加Constraint. e.g.在Microsof
-
sqlserver 临时表的用法
用法: 用于复杂查询时可以用临时表来暂存相关记录,能够提高效率.提高程序的可读性,类似于游标中的 my_cursor declare my_cursor cursor scroll for select 字段 from tablename 临时表分为:用户临时表和系统临时表. 系统临时表和用户临时表的区别: 1)用户临时表:用户临时表的名称以#开头; 用户临时表的周期只存在于创建这个表的用户的Session,对其他进程是不可见. 当创建它的进程消失时此临时表自动删除. 2)系统临时表:系统临时表
-
SQLServer中临时表与表变量的区别分析
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢? 临时表 临时表与永久表相似,只是它的创建是在Tempdb中,它只有在一个数据库连接结束后或者由SQL命令DROP掉,才会消失,否则就会一直存在.临时表在创建的时候都会产生SQL Server的系统日志,虽它们在Tempdb中体现,是分配在内存中的,它们也支持物理的磁盘,但用户在指定的磁盘里看不到文件. 临时表分为本地
-
C#中属性和成员变量的区别说明
一个类,有时候搞不清楚到底用成员变量还是属性. 如: 成员变量 public string Name; 或者用属性 private string name public string Name{ get { return name; } set { name = value; } } 属性与成员变量类似
-
PHP中$GLOBALS['HTTP_RAW_POST_DATA']和$_POST的区别分析
本文分析了PHP中$GLOBALS['HTTP_RAW_POST_DATA']和$_POST的区别.分享给大家供大家参考,具体如下: $_POST:通过 HTTP POST 方法传递的变量组成的数组.是自动全局变量. $GLOBALS['HTTP_RAW_POST_DATA'] :总是产生 $HTTP_RAW_POST_DATA 变量包含有原始的 POST 数据.此变量仅在碰到未识别 MIME 类型的数据时产生.$HTTP_RAW_POST_DATA 对于 enctype="multipart/
-
Go语言中普通函数与方法的区别分析
本文实例分析了Go语言中普通函数与方法的区别.分享给大家供大家参考.具体分析如下: 1.对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然. 2.对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以. 以下为简单示例: 复制代码 代码如下: package structTest //普通函数与方法的区别(在接收者分别为值类型和指针类型的时候) //Date:2014-4-3 10:00:07 import (
-
C#中Convert.ToString和ToString的区别分析
本文实例分析了C#中Convert.ToString和ToString的区别,对于初学者来说是很有必要加以熟练掌握的.具体分析如下: 1.Convert.ToString能处理字符串为null的情况. 测试代码如下: static void Main(string[] args) { string msg = null; Console.WriteLine(Convert.ToString(msg)); Console.ReadKey(); } 运行,没有抛出异常. 2.ToString方法不能
-
JSP中response.setContentType和response.setCharacterEncoding区别分析
本文实例讲述了JSP中response.setContentType和response.setCharacterEncoding区别.分享给大家供大家参考,具体如下: response.setContentType 设置发送到客户端的响应的内容类型,可以包括字符编码说明. 也就是说在服务器端坐了这个设置,那么他将在浏览器端起到作用,在你打开浏览器时决定编码方式 如果该方法在response.getWriter()被调用之前调用,那么响应的字符编码将仅从给出的内容类型中设置.该方法如果在respo
-
node.js中的定时器nextTick()和setImmediate()区别分析
1.node中使用定时器的问题在于,它并非精确的.譬如setTimeout()设定一个任务在10ms后执行,但是在9ms后,有一个任务占用了5ms,再次轮到定时器时,已经耽误了4ms. 好了node中的定时器就简单的讲这么多. 2.看代码: 复制代码 代码如下: process.nextTick(function(){ console.log("延迟执行"); }); console.log("正常执行1"); console.log("正常执行2
-
jquery中live()方法和bind()方法区别分析
本文实例讲述了jquery中live()方法和bind()方法区别.分享给大家供大家参考,具体如下: live()不受加载时间顺序的影响,只要查找能够配对上就能够绑定对应的事件,而bind方法只有在第一次被加载的时候才绑定时间,如果代码之后再加载配对的元素,则不能绑定对应的事件 $("#manual_disconnect").live("click", function(){ connectionProfile("0"); }); $("
-
C#中常量和只读变量的区别小结
常量和只读变量有以下区别: 1.常量必须在声明时就被初始化,指定了值后就不能修改了.只读字段可以在声明时被初始化,也可以在构造函数中指定初始化的值,在构造以后值就不能修改. 2.常量是静态的,而只读字段可以是静态和动态的 3.Const可以用在字段和局部变量,readonly只可以修饰字段