js中根据字数截取字符串,不能截断url
今天收到个需求:
1,给一个文字,对输出的文字进行截取,保留400个字符
2,截取内容最后如果是url,保留完整url地址
3,添加省略号......
----
其中对url的保留比较麻烦,尤其是有两个相同url时不能采用indexOf获取其字符位置。
处理结果:
String.prototype.sizeAt = function(){
var nLen = 0;
for(var i = 0, end = this.length; i<end; i++){
nLen += this.charCodeAt(i)>128?2:1;
}
return nLen;
};
String.prototype.cutStr = function(n, sCut){
if(this.sizeAt() <= n){
return this;
}
sCut = sCut || "";
var max = n-sCut.sizeAt();
var nLen = 0;
var s = this;
for(var i =0,end = this.length;i<end;i++){
nLen += this.charCodeAt(i)>128?2:1;
if(nLen>max){
s = this.slice(0,i);
s += sCut;
break;
}
}
return s.toString();
};
String.prototype.cutStrButUrl = function(n, sCut){
if(this.sizeAt() <=n){
return this.toString();
}
sCut = sCut || "";
var max = n-sCut.sizeAt();
var s = this;
//查找所有包含的url
var aUrl = s.match(/https?:\/\/[a-zA-Z0-9]+(\.[a-zA-Z0-9]+)+([-_A-Z0-9a-z\$\.\+\!\*\/,:;@&=\?\~\#\%]*)*/gi);
//当第max个字符刚好在url之间时,bCut会被设置为flase;
var bCut = true;
if(aUrl){
//对每个url进行判断
for(var i=0, endI = aUrl.length;i<endI;i++){
var sUrl = aUrl[i];
//可能出现两个相同url的情况
var aP = s.split(sUrl);
var nCurr = 0;
var nLenURL = sUrl.sizeAt();
var sResult = "";
for(j = 0, endJ = aP.length; j<endJ; j++){
nCurr +=aP[j].sizeAt();
sResult +=aP[j];
sResult += sUrl;
//当前字数相加少于max但添加url超过max:即会截到url
if(nCurr < max && nCurr + nLenURL>max){
s = sResult + sCut;
bCut = false;
break;
}
nCurr += nLenURL;
}
if(bCut === false){
break;
}
};
}
if(bCut){
s = s.cutStr(n, sCut);
}
return s.toString();
};
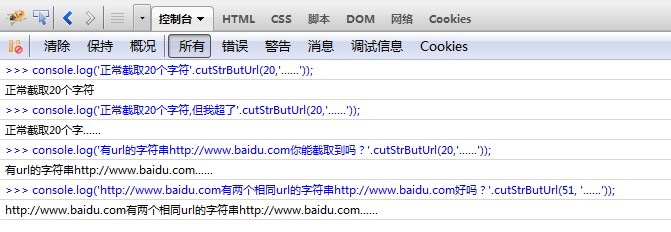
console.log('正常截取20个字符'.cutStrButUrl(20,'......'));
console.log('正常截取20个字符,但我超了'.cutStrButUrl(20,'......'));
console.log('有url的字符串http://www.baidu.com你能截取到吗?'.cutStrButUrl(20,'......'));
console.log('http://www.baidu.com有两个相同url的字符串http://www.baidu.com好吗?'.cutStrButUrl(51, '......'));
相关推荐
-
PHP截断标题且兼容utf8和gb2312编码
复制代码 代码如下: <?php if(strlen($r[title])>45){$str=utf8Substr($r[title],0,15)."...";}else{$str=$r[title];}echo $str; ?> //截取utf8字符串 function utf8Substr($str, $from, $len) { return preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.
-
C# double和decimal数据类型以截断的方式保留指定的小数位数
项目中要用到以截断的方式取小数点后两位,故写了以下方法: 复制代码 代码如下: /// <summary> /// 将小数值按指定的小数位数截断 /// </summary> /// <param name="d">要截断的小数</param> /// <param name="s">小数位数,s大于等于0,小于等于28</param> /// <returns></retur
-
c#完美截断字符串代码(中文+非中文)
复制代码 代码如下: public static string Truncation(this HtmlHelper htmlHelper, string str, int len) { if (str == null || str.Length == 0 || len <= 0) { return string.Empty; } int l = str.Length; #region 计算长度 int clen = 0; while (clen < len && clen &
-
MSSQL 将截断字符串或二进制数据问题的解决方法
地图数据存放在sqlserver 2008中,使用mapxtreme7 开发时,使用Feature.Update()方法时出错的提示包含"MSSQL 将截断字符串或二进制数据" 主要原因就是给某个字段赋值时,内容大于字段的长度或类型不符造成的 解决方法: 一个是修改数据库字段大小: 再一就是是加强数据强壮性,严格的输入判断. 防止添加的信息类型或者长度与数据库表中字段所对应的类型不符合.
-
PHP UTF8中文字符截断函数代码
php中英文混合字符截断不乱码函数(utf8) 复制代码 代码如下: //utf8格式下的中文字符截断//$sourcestr 是要处理的字符串//$cutlength 为截取的长度(即字数)//$addstr 超过长度时在尾处加上的字符function cut_str($sourcestr, $cutlength, $addstr='...'){ $returnstr=''; $i=0; $n=0; $str_length=strlen($sourcestr);//字符串的字节数 while
-
PHP在字符断点处截断文字的实现代码
复制代码 代码如下: //所谓断字 (word break),即一个单词可在转行时断开的地方.这一函数将在断字处截断字符串. // Please acknowledge use of this code by including this header. function myTruncate($string, $limit, $break=".", $pad="...") { // return with no change if string is shorte
-
php使用iconv中文截断问题的解决方法
本文实例讲述了php使用iconv中文截断问题的解决方法.分享给大家供大家参考.具体分析如下: 今天做了一个采集程序,原理很简单,使用curl方法把对方页面的html获取分析,然后正则提取需要的数据并保存在数据库. 由于对方页面是GB2312编码,而本地使用的是UTF-8编码.因此在采集后需要进行编码转换. 使用了iconv方法进行编码转换 iconv - 字符串按要求的字符编码来转换 string iconv ( string $in_charset , string $out_charse
-

js实现文字截断功能
先前用jq做了一个文字截断功能,但是不用jq的项目要实现此功能还要引如jq显得过于麻烦.这里写了一个js的文字截断功能.直接上代码. HTML(测试用的): <div>我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox我是pox</div> <div limit="10" >我是pox我是pox我是pox我是pox我是p
-
PHP连接MSSQL时nvarchar字段长度被截断为255的解决方法
本文实例讲述了PHP连接MSSQL时nvarchar字段长度被截断为255的解决方法.分享给大家供大家参考.具体分析如下: PHP 连接 MSSQL 的新手经常遇到这个问题:数据库里面的 nvarchar 字段中数据一切正常,但是用 PHP 查询出来却发现长度只有 255,我们都知道,在 MySQL 里面 varchar 的长度只有 255,但是 MSSQL 却不是,不会是 PHP 将 nvarchar 按照 MySQL 的 varchar 处理了吧. 本文给出了解决方法: 复制代码 代码如下:
-
oracle中截断表的使用介绍
在Oracle中如果删除了表中的某一条数据,还可以通过回滚操作(rollback)进行回滚,假如想清空一张 表的数据,但是又不想使其能进行回滚操作,就可以立刻释放资源,这时就需要使用截断表了.它的主要功能就是彻底删除数据,使其不能进行回滚.这里我打个比方大家就立刻能明了它的作用.大家众所周知,当我们在自己的PC(personcomputer)上删除某一个文件,它并没有彻底删除而是进入了回收站,你要在回收站中再将其删除才算彻底清除.截断表就相当于直接将数据从pc上删除,而不会放入回收站. 截断表格