深入学习SQL Server聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期。Sql server聚合函数对一组值执行计算并返回单一的值。聚合函数对一组值执行计算,并返回单个值。除了 COUNT 以外,聚合函数都会忽略空值。 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。
一.写在前面
如果有对Sql server聚合函数不熟或者忘记了的可以看我之前的一片博客。
本文中所有数据演示都是用Microsoft官方示例数据库:Northwind,至于Northwind大家也可以在网上下载。
二.Sql server标量聚合
2.1.概念:在只包含聚合函数的 SELECT 语句列列表中指定的一种聚合函数(如 MIN()、MAX()、COUNT()、SUM() 或 AVG())。当列列表只包含聚合函数时,则结果集只具有一个行给出聚合值,该值由与 WHERE 子句谓词相匹配的源行计算得到。
2.2.探索标量聚合:
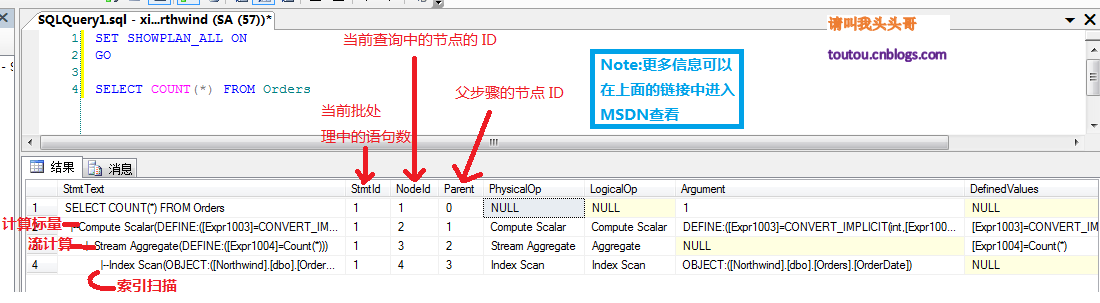
我们先用Sql server的"包括实际的执行计划"来看看一个简单的流聚合COUNT()来看看表里数据所有的行数。

再通过SET SHOWPLAN_ALL ON(关于输出中包含的列更多信息可以在链接中查看)来看看有关语句执行情况的详细信息,并估计语句对资源的需求。
通过SET SHOWPLAN_ALL ON我们来看看COUNT()具体做了那些事情:
- 索引扫描:扫描当前表的行数
- 流计算:计算行数的数量
- 计算标量:将流计算出来的结果转化为适当的类型。(因为索引扫描出来的结果是根据表中数据的大小决定的,如果表中数据很多的话,COUNT是int类型就会有问题,所以在最终返回的时候需要将默认类型(数值一般默认类型是Big)转成int类型。)
- 小结:通过SET SHOWPLAN_ALL ON我们可以查看Sql server聚合函数在给我们呈现最终效果的时候,为这个效果做了些什么事情。
2.3.标量聚合优化技巧:
我们通过两个比较简单的sql查询来看看他们的区别
SELECT COUNT(DISTINCT ShipCity) FROM OrdersSELECT COUNT(DISTINCT OrderID) FROM Orders
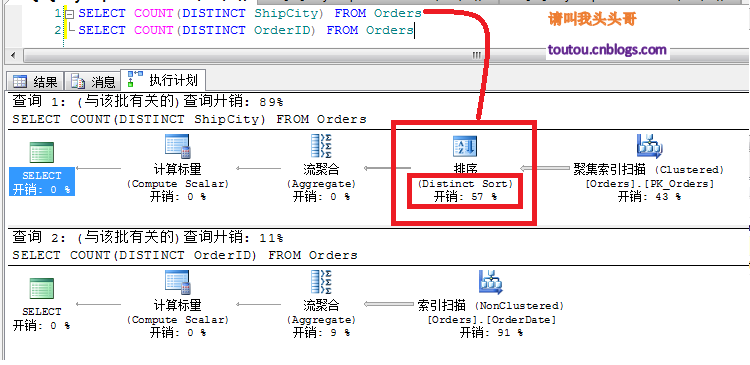
从上图中可以看到,其实这两个查询从语句上来说没什么太大的区别,但是为什么开销会不一样,一个是查询城市一个是查询订单号。这是因为其实DISTINCT对于OrderID查询来说,是没有什么意义的,因为OrderID是主键,是不会有重复的。而ShipCity是会有重复的,Sql server的去重机制在去重的时候,会有一个排序的过程。这个排序还是比较消耗资源的。
对于数据量比较大的表其实不是很建议对大表排序或者对大表的某个重复次数多的字段去重运算。所以我们这里可以对ShipCity进行优化一下。可以对ShipCity创建一个非聚集索引。
CREATE INDEX Index_ShipCity On Orders(ShipCity desc)go

从上图中可以看到,加了索引以后COUNT(DISTINCT ShipCity)的查询变成了两个流聚合,而没有了排序,节省了开销。
总结:对于标量聚合从上面的例子大家可以看到,标量聚合优缺点很明显:
- Sql server标量聚合优点:算法比较简单直观,适合非重复值的聚合操作。Sql server标量聚合缺点:性能较差(需要排序),不适合重复值的聚合操作。
- 优化技巧:尽量避免排序产生,将分组字(GROUP BY)段锁定在索引覆盖范围内
三.Sql server哈希聚合
3.1.概念:
哈希(Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。)
哈希聚合的内部实现方法和哈希连接的实现机制一样,需要哈希函数的内部运算,形成不同的哈希值,依次并行扫描数据形成聚合值。
3.2.背景:
为了解决流聚合的不足,应对大数据的操作,所以哈希聚合就诞生了。
3.3.分析:
来看看两个简单的查询。
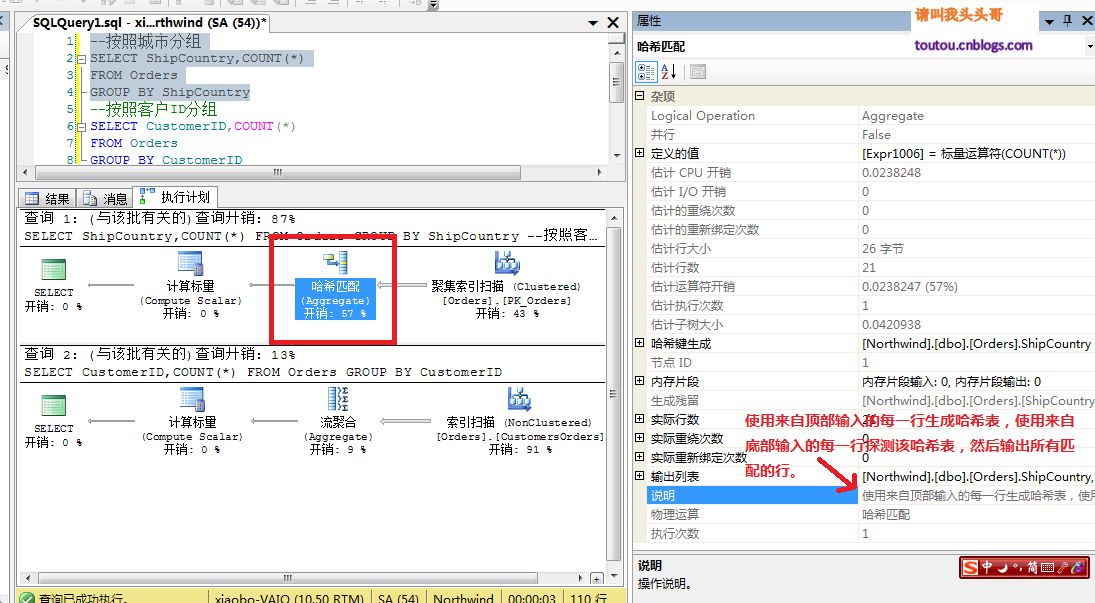
ShipCountry和CustomerID的分组查询看上去很类似,但是为什么执行计划会不同呢?这是因为ShipCountry包含了大量的重复值,CustomerID重复值非常少,所以Sql server系统给ShipCountry推送的哈希聚合,而CustomerID推送的是流聚合。也就是说Sql server系统会动态的根据查询的情况选择合适的聚合方式。所以我们在做SQL优化的时候不能仅根据SQL语句来优化,还得结合具体数据分布的环境。
四.运算过程监控指标
4.1.监控元素:
可视化查看运行时间T-sql语句查询时间占用内存T-sql语句查询IO
4.2.可视化查看运行时间: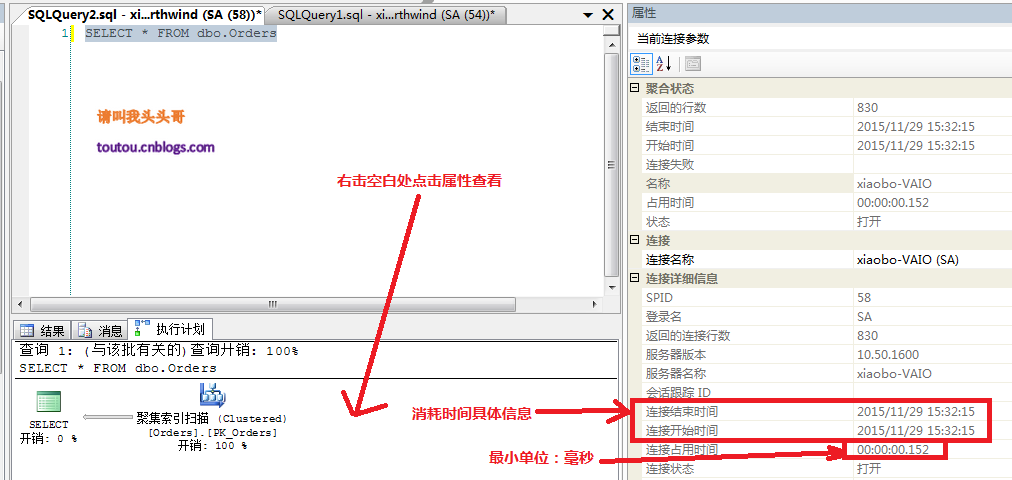
4.3.T-sql语句查询时间:

4.4.占用内存:
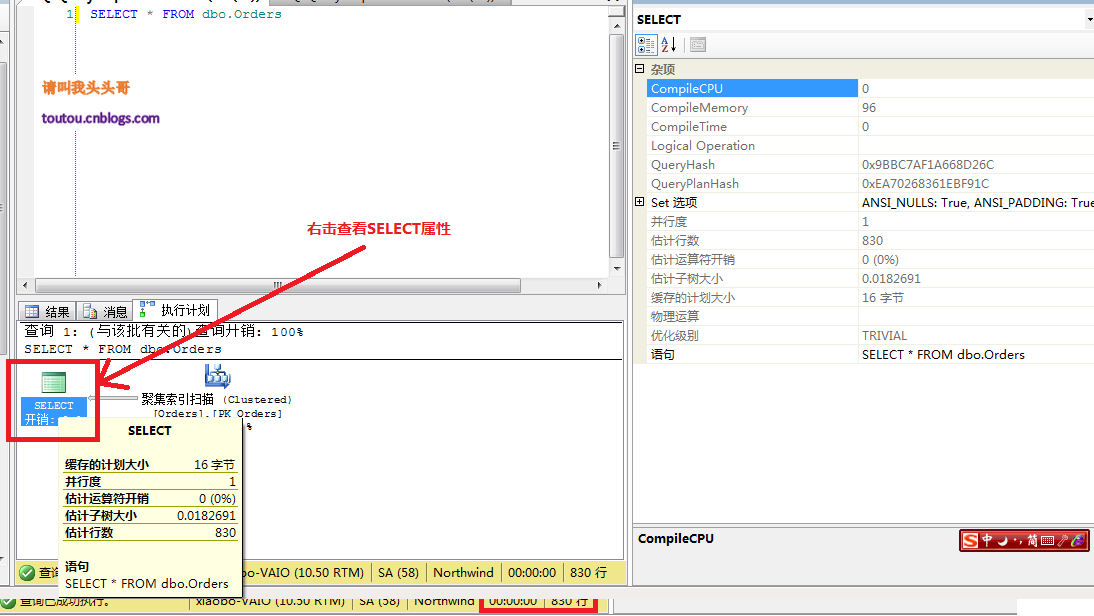
4.5.T-sql语句查询IO:
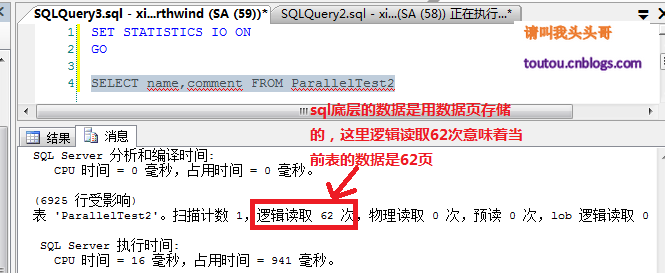
关于监控元素还有很多,这里就列举几个。
SQL Server 聚合函数算法优化技巧差不多就介绍到这里,希望对大家优化聚合函数算法有所帮助。
相关推荐
-

Sql Server 2000 行转列的实现(横排)
我们用到的表结构如下: 三张表的关系为: 现有的测试数据为: 我们需要的结果是: 复制代码 代码如下: DECLARE @strSQL VARCHAR(8000) SET @strSQL = 'SELECT t.STUNAME [姓名]' SELECT @strSQL = @strSQL + ',SUM(CASE s.SNAME WHEN ''' + SNAME + ''' THEN g.[Score] END) [' + SNAME + ']' FROM (SELECT SNAME FROM
-
sqlserver 行列互转实现小结
复制代码 代码如下: --行列互转 /****************************************************************************************************************************************************** 以学生成绩为例子,比较形象易懂 整理人:中国风(Roy) 日期:2008.06.06 *************************************
-
SQLServer行转列实现思路记录
最近面试遇到了一道面试题,顿时有点迷糊,只说出了思路,后来百度了一下,整理了一下思路,于是记录下来,方便以后学习.(面试题请参见附件) 相关的数据表: 1.Score表 2.[User]表 SQL语句如下: --方法一:静态SQL 复制代码 代码如下: SELECT * FROM (SELECT UID,Name, Score,ScoreName FROM Score,[User] WHERE Score.UID=[User].ID) AS SourceTable PIVOT(AVG(Sco
-
sqlserver下将数据库记录的列记录转换成行记录的方法
假设有张学生成绩表(tb)如下: Name Subject Result 张三 语文 74 张三 数学 83 张三 物理 93 李四 语文 74 李四 数学 84 李四 物理 94 想变成 姓名 语文 数学 物理 ---------- ----------- ----------- ----------- 李四 74 84 94 张三 74 83 93 SQL 语句如下: 复制代码 代码如下: create table tb ( Name varchar(10) , Subject varcha
-
Sql Server 字符串聚合函数
如下表:AggregationTable Id Name 1 赵 2 钱 1 孙 1 李 2 周 如果想得到下图的聚合结果 Id Name 1 赵孙李 2 钱周 利用SUM.AVG.COUNT.COUNT(*).MAX 和 MIN是无法做到的.因为这些都是对数值的聚合.不过我们可以通过自定义函数的方式来解决这个问题.1.首先建立测试表,并插入测试数据: 复制代码 代码如下: create table AggregationTable(Id int, [Name] varchar(10)) go
-
sqlserver2005 行列转换实现方法
复制代码 代码如下: --Create Company Table Create Table Company ( ComID varchar(50) primary key, ComName nvarchar(50) not null, ComNumber varchar(50) not null, ComAddress nvarchar(200), ComTele varchar(50) ) --Create Product Table Create Table Product ( Produ
-
SQLServer行列互转实现思路(聚合函数)
有时候会碰到行转列的需求(也就是将列的值作为列名称),通常我都是用 CASE END + 聚合函数来实现的. 如下: declare @t table (StudentName nvarchar(20), Subject nvarchar(20), Score int) Insert into @t (StudentName,Subject,Score) values ( '学生A', '中文', 80 ); Insert into @t (StudentName,Subject,Score)
-
深入学习SQL Server聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值执行计算并返回单一的值.聚合函数对一组值执行计算,并返回单个值.除了 COUNT 以外,聚合函数都会忽略空值. 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用. 一.写在前面 如果有对Sql server聚合函数不熟或者忘记了的可以看我之前的一片博客. 本文中所有数据演示都是用
-
SQL Server 开窗函数 Over()代替游标的使用详解
前言: 今天在优化工作中遇到的sql慢的问题,发现以前用了挺多游标来处理数据,这样就导致在数据量多的情况下,需要一行一行去遍历从而计算需要的数据,这样处理的结果就是数据慢,容易卡死. 语法介绍: 1.与Row_Number() 函数结合使用,对结果进行排序,这个是我们使用的非常多的 2.与聚合函数结合使用,利用over子句的分组和排序,对需要的数据进行操作 例如:SUM() Over() 累加值.AVG() Over() 平均数 MAX() Over() 最大值.MIN() Over() 最小值
-
sql server查询语句阻塞优化性能
在生产环境下,有时公司客服反映网页半天打不到,除了在浏览器按F12的Network响应来排查,确定web服务器无故障后.就需要检查数据库是否有出现阻塞 当时数据库的生产环境中主表数据量超过2000w,子表数据量超过1亿,且更新和新增频繁.再加上做了同步镜像,很消耗资源. 这时就要新建一个会话,大概需要了解以下几点: 1.当前活动会话量有多少? 2.会话运行时间? 3.会话之间有没有阻塞? 4.阻塞时间 ? 查询阻塞的方法有很多.有sql 2000 的sp_lock, 有sql 2005及以上的d
-
SQL Server 常用函数使用方法小结
之前就想要把一些 SQL 的常用函数记录下来,不过一直没有实行...嘿嘿... 直到今天用到substring()这个函数,C# 里面这个方法起始值是 0,而 SQL 里面起始值是 1.傻傻分不清楚... 这篇博客作为记录 SQL 的函数的使用方法,想到哪里用到哪里就写到哪里... SubString():用于截取指定字符串的方法.该方法有三个参数: 参数1:用于指定要操作的字符串. 参数2:用于指定要截取的字符串的起始位置,起始值为 1 . 参数3:用于指定要截取的长度. select sub
-
实例讲解sql server排名函数DENSE_RANK的用法
一.需求 之前sql server 的排名函数用得最多的应该是RoW_NUMBER()了,我通常用ROW_NUMBER() + CTE 来实现分页:今天逛园,看到另一个内置排名函数还不错,自己顺便想了一个需求,大家可以花1分钟先想想要怎么实现. 需求很简单:求成绩排名前五的学生信息. 例如: 由于成绩可以并列,所以前五名可能有多个.例如: 测试数据: declare @t table (ID int, StudentName nvarchar(15), Score int) insert int
-
Sql Server 开窗函数Over()的使用实例详解
利用over(),将统计信息计算出来,然后直接筛选结果集 declare @t table( ProductID int, ProductName varchar(20), ProductType varchar(20), Price int) insert @t select 1,'name1','P1',3 union all select 2,'name2','P1',5 union all select 3,'name3','P2',4 union all select 4,'name4
-
SQL Server中函数、存储过程与触发器的用法
一.函数 函数分为(1)系统函数,(2)自定义函数. 其中自定义函数又可以分为(1)标量值函数(返回单个值),(2)表值函数(返回查询结果) 本文主要介绍自定义函数的使用. (1)编写一个函数求该银行的金额总和 create function GetSumCardMoney() returns money as begin declare @AllMOney money select @AllMOney = (select SUM(CardMoney) from BankCard) return
-
SQL Server系统函数介绍
一.常用函数: APP_NAME: 返回当前会话的应用程序名称(如果应用程序进行了设置). SELECT APP_NAME() COALESCE: 返回其参数中第一个非空表达式 SELECT COALESCE(NULL,NULL,123,NULL) COL_LENGTH(table,column):返回table表中column字段的长度: SELECT COL_LENGTH('person','gender'),COL_LENGTH('person','FirstName'); COL_NAM
-
SQL Server COALESCE函数详解及实例
SQL Server COALESCE函数详解 很多人知道ISNULL函数,但是很少人知道Coalesce函数,人们会无意中使用到Coalesce函数,并且发现它比ISNULL更加强大,其实到目前为止,这个函数的确非常有用,本文主要讲解其中的一些基本使用: 首先看看联机丛书的简要定义: 返回其参数中第一个非空表达式语法: COALESCE ( expression [ ,...n ] ) 如果所有参数均为 NULL,则 COALESCE 返回 NULL.至少应有一个 Null 值为 NULL
-
SQL Server 聚焦存储过程性能优化、数据压缩和页压缩提高IO性能方法(一)
前言 关于SQL Server基础系列尚未结束,还剩下最后一点内容未写,后面会继续.有园友询问我什么时候开始写SQL Server性能系列,估计还得等一段时间,最近工作也比较忙,但是会陆陆续续的更新SQL Server性能系列,本篇作为性能系列的基本引导,让大家尝尝鲜.在涉及到SQL Server性能优化时,我看到的有些文章就是一上来列出SQL Server的性能优化条例,根本没有弄清楚为什么这么做,当然也有可能是自己弄懂了,只是作为备忘录,但是到了我这里,我会遵循不仅仅是备忘录,还要让各位园友