Python机器学习之基础概述
一、基础概述
- 机器学习(Machine Learing)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
- 机器学习专门研究计算机怎样模拟或实现人类的学习行为,以便获取新的知识和技能,重新组织已有的知识结构使之不断改善自身的性能。
- 机器学习是人工智能的核心,是计算机具有智能的根本途径,其应用遍及人工智能的各个领域。
- 机器学习使用归纳、综合而不是演绎。
二、算法分类
按照学习方式
监督学习

半监督学习
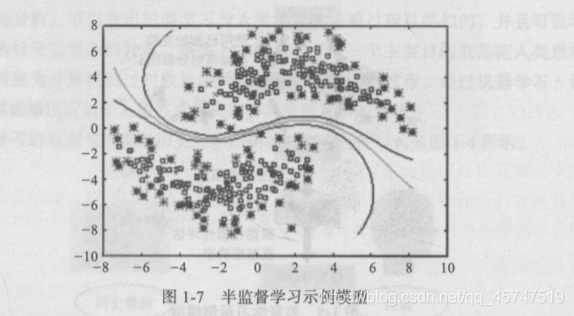
无监督学习
强化学习
按照算法相似性
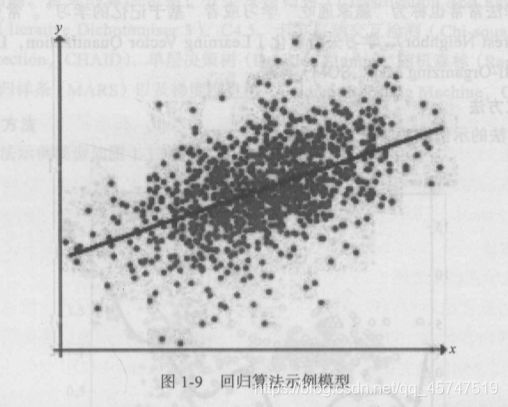
- 回归算法
- 聚类算法
- 降维算法
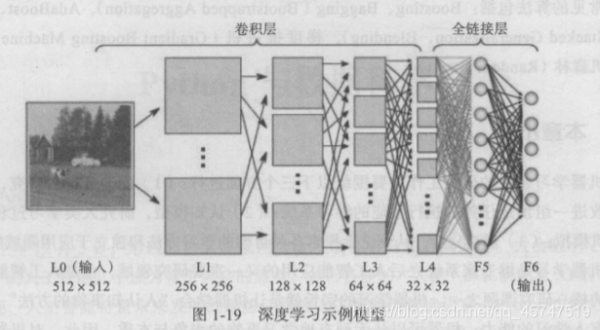
- 深度学习
- 集成算法
- 正则化算法
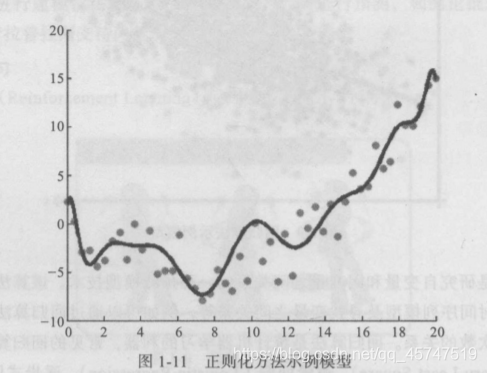
- 决策树算法
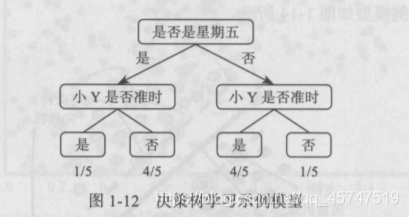
- 贝叶斯算法
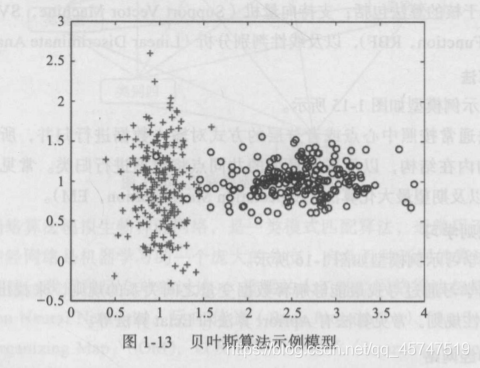
- 关联规则学习
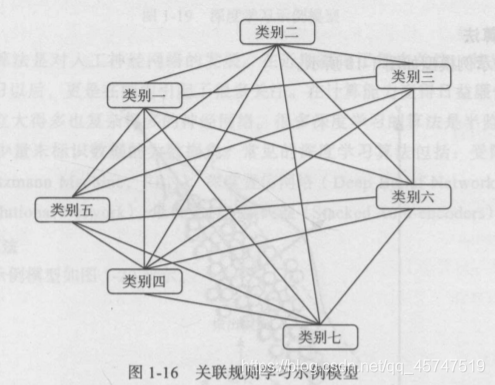
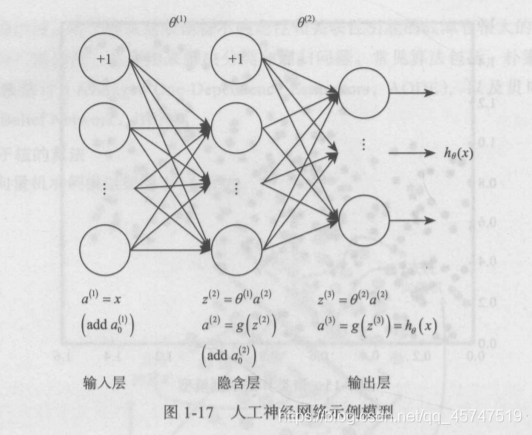
- 人工神经网络
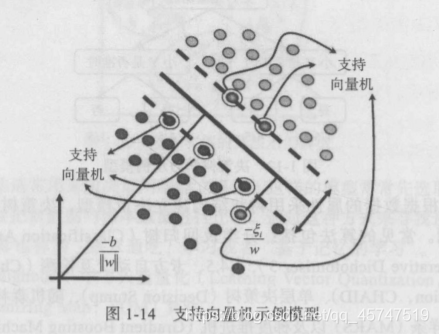
- 基于核的算法
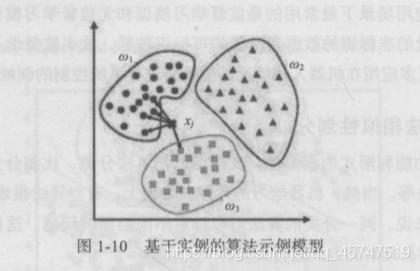
- 基于实例的算法
三、研究内容
机器学习领域的研究工作主要围绕以下三个方面
- 面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统。
- 认知模型,研究人类学习过程并进行计算机的模拟。
- 理论分析,从理论上探索各种可能的学习方法和独立于应用领域的算法。
到此这篇关于Python机器学习之基础概述的文章就介绍到这了,更多相关Python机器学习内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python机器学习之线性回归详解
一.python机器学习–线性回归 线性回归是最简单的机器学习模型,其形式简单,易于实现,同时也是很多机器学习模型的基础. 对于一个给定的训练集数据,线性回归的目的就是找到一个与这些数据最吻合的线性函数. 二.OLS线性回归 2.1 Ordinary Least Squares 最小二乘法 一般情况下,线性回归假设模型为下,其中w为模型参数 线性回归模型通常使用MSE(均方误差)作为损失函数,假设有m个样本,均方损失函数为:(所有实例预测值与实际值误差平方的均值) 由于模型的训练目标为找到使得损
-
Python机器学习之KNN近邻算法
一.KNN概述 简单来说,K-近邻算法采用测量不同特征值之间的距离方法进行分类 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 适用数据范围:数值型和标称2型 工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系(训练集).输入没有标签的新数据之后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签(测试集).一般来说,我们只选择样
-
Python机器学习算法之决策树算法的实现与优缺点
1.算法概述 决策树算法是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法. 分类算法是利用训练样本集获得分类函数即分类模型(分类器),从而实现将数据集中的样本划分到各个类中.分类模型通过学习训练样本中属性集与类别之间的潜在关系,并以此为依据对新样本属于哪一类进行预测. 决策树算法是直观运用概率分析的一种图解法,是一种十分常用的分类方法,属于有监督学习. 决策树是一种树形结构,其中每个内部结点表示在一个属性上的测试,每个
-
Python机器学习之决策树
一.要求 二.原理 决策树是一种类似于流程图的结构,其中每个内部节点代表一个属性上的"测试",每个分支代表测试的结果,每个叶节点代表一个测试结果.类标签(在计算所有属性后做出的决定).从根到叶的路径代表分类规则. 决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树.因此如何构建决策树,是后续预测的关键!而构建决策树,就需要确定类标签判断的先后,其决定了构建的决策树的性能.决策树的分支节点应该尽可能的属于同一类别,即节点的"纯度"要越来越高,只有这
-
python 机器学习的标准化、归一化、正则化、离散化和白化
机器学习的本质是从数据集中发现数据内在的特征,而数据的内在特征往往被样本的规格.分布范围等外在特征所掩盖.数据预处理正是为了最大限度地帮助机器学习模型或算法找到数据内在特征所做的一系列操作,这些操作主要包括标准化.归一化.正则化.离散化和白化等. 1 标准化 假定样本集是二维平面上的若干个点,横坐标 x 分布于区间 [0,100] 内,纵坐标 y 分布于区间 [0,1] 内.显然,样本集的 x 特征列和 y 特征列的动态范围相差巨大,对于机器学习模型(如k-近邻或 k-means 聚类)的影响也
-
Python机器学习工具scikit-learn的使用笔记
scikit-learn 是基于 Python 语言的机器学习工具 简单高效的数据挖掘和数据分析工具 可供大家在各种环境中重复使用 建立在 NumPy ,SciPy 和 matplotlib 上 开源,可商业使用 - BSD许可证 sklearn 中文文档:http://www.scikitlearn.com.cn/ 官方文档:http://scikit-learn.org/stable/ sklearn官方文档的类容和结构如下: sklearn是基于numpy和scipy的一个机器学习算法库,
-
python机器学习实现决策树
本文实例为大家分享了python机器学习实现决策树的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- """ Created on Sat Nov 9 10:42:38 2019 @author: asus """ """ 决策树 目的: 1. 使用决策树模型 2. 了解决策树模型的参数 3. 初步了解调参数 要求: 基于乳腺癌数据集完成以下任务: 1.调整参数criterion,使
-
Python 机器学习工具包SKlearn的安装与使用
1.SKlearn 是什么 Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包. Sklearn 主要用Python编写,建立在 Numpy.Scipy.Pandas 和 Matplotlib 的基础上,也用 Cython编写了一些核心算法来提高性能. Sklearn 包括六大功能模块: 分类(Classification):识别样本属于哪个类别,常用算法有 SVM(支持向量机).nearest neighbors(最近邻).random forest(
-
python机器学习包mlxtend的安装和配置详解
今天看到了mlxtend的包,看了下example集成得非常简洁.还有一个吸引我的地方是自带了一些data直接可以用,省去了自己造数据或者找数据的处理过程,所以决定安装体验一下. 依赖环境 首先,sudo pip install mlxtend 得到基础环境. 然后开始看看系统依赖问题的解决.大致看了下基本都是python科学计算用的那几个经典的包,主要是numpy,scipy,matplotlib,sklearn这些. LINUX环境下的话,一般这些都比较好装pip一般都能搞定. 这里要说的一
-
python机器学习库xgboost的使用
1.数据读取 利用原生xgboost库读取libsvm数据 import xgboost as xgb data = xgb.DMatrix(libsvm文件) 使用sklearn读取libsvm数据 from sklearn.datasets import load_svmlight_file X_train,y_train = load_svmlight_file(libsvm文件) 使用pandas读取完数据后在转化为标准形式 2.模型训练过程 1.未调参基线模型 使用xgboost原生库
-
Python机器学习三大件之一numpy
一.前言 机器学习三大件:numpy, pandas, matplotlib Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组. Numpy支持常见的数组和矩阵操作.对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多. Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器. NumPy提供了一个N维数组类型ndarray import numpy as np score = np.arr
-
Python机器学习之Kmeans基础算法
一.K-means基础算法简介 k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇.聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集. 二.算法过程 K-means中心思想:事先确定常数K,常数K意味着最终的聚类(或者叫簇)类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要